




Best AI Models June 2026: Every Major LLM From Every Company Ranked & Compared
255 model releases dropped in Q1 2026 alone. Roughly three significant models every single day. By June 2026, the AI landscape has fractured so completely that there is no longer one winner, one company, or even one category. There is a best coding model, a best reasoning model, a best open-source model, a best multimodal model, and a best value model, and none of them are the same system. If you picked a model in January and have not changed since, you are almost certainly leaving performance, money, or both on the table.
This post covers every major AI model released as of June 2026 across 15 companies: Anthropic, OpenAI, Google DeepMind, xAI, Meta, DeepSeek, Alibaba (Qwen), Mistral, Microsoft, NVIDIA, Zhipu AI (Z.ai), Moonshot AI (Kimi), Xiaomi, MiniMax, and Cohere. Every benchmark number is sourced. Every recommendation is honest. No marketing fluff, no sponsored rankings.
1. The June 2026 Frontier: What Has Changed
Six months ago, choosing an AI model meant picking between GPT, Claude, and Gemini. Today you are navigating a field of 15+ serious players where the performance gap between top open-source and top proprietary models has shrunk to single-digit percentage points on most benchmarks. Three structural shifts define mid-2026:
First, the open-source explosion. Chinese labs (DeepSeek, Z.ai, Moonshot AI, Alibaba, MiniMax) have shipped flagship models with open weights under MIT or Apache 2.0 licenses that compete directly with $25/million-token proprietary APIs at a fraction of the cost. DeepSeek V4 Flash charges $0.28 per million output tokens. GLM-5.1 does 94.6% of Claude Opus performance for $3/month. This is not incremental, this is a pricing earthquak
Second, SWE-bench Verified has saturated. Every frontier model now scores 78%+ on the benchmark that defined AI coding in 2025. The real proxy for production engineering is now SWE-bench Pro (2,294 real GitHub issues) and Terminal-Bench 2.1 (agentic, CLI-first tasks). Claude Opus 4.8 leads SWE-bench Pro at 69.2%; the gap between #1 and #5 is approximately 13 points
Third, Mythos-class models are arriving. Anthropic's Claude Mythos Preview reaches a 72.5 reasoning score on LLM Stats' composite (94.6% GPQA Diamond) but remains restricted to approximately 50 Project Glasswing partner organizations. When it ships publicly, it will become the new ceiling. Plan for that transition. For a detailed breakdown of every model's position on the leaderboard, the Best AI Models & Leaderboards collection at Build Fast with AI tracks every major release as it drops
2. Anthropic: Claude Opus 4.8, Sonnet 4.6, Haiku 4.5, and Mythos Preview
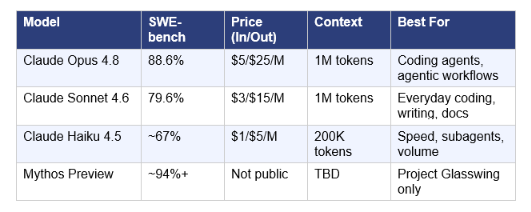
Anthropic holds the #1 spot on the Artificial Analysis Intelligence Index as of June 2026, with Claude Opus 4.8 scoring 61.4 on the composite and 88.6% on SWE-bench Verified. The family covers four models plus the unreleased Mythos tier.
Claude Opus 4.8 (Flagship)
Released May 28, 2026, Opus 4.8 is Anthropic's most capable generally available model. SWE-bench Verified: 88.6%, SWE-bench Pro: 69.2%, Terminal-Bench 2.1: 74.6%. Cursor's CEO confirmed it exceeds prior Opus models across every effort level on CursorBench. Pricing: $5/$25 per million input/output tokens with optional Fast mode at $10/$50. 1M token context window with no long-context surcharge. Prompt caching can cut input cost by up to 90%. Best for: production coding agents, long-horizon agentic workflows, multi-file refactors, financial analysis.
Claude Sonnet 4.6 (Volume Workhorse)
The default model on Claude.ai Free and Pro plans, powering GitHub Copilot's coding agent, and the model most professional developers run in Cursor and Windsurf daily. SWE-bench Verified: 79.6%. GDPval-AA Elo: 1,633 (highest of any mid-tier model). Pricing: $3/$15 per million tokens. Delivers approximately 90% of Opus 4.8 quality at 40% of the price. Claude Sonnet 4.6 is the right default for 80%+ of production workloads where you do not need the Opus ceiling.
Claude Haiku 4.5 (Speed Tier)
Anthropic's fastest and most cost-efficient model. Pricing starts at $1/$5 per million tokens. Designed for quick edits, subagent tasks within larger pipelines, and high-volume use cases where latency matters more than maximum capability. Matches Claude Sonnet 4 performance at a fraction of the price.
Claude Mythos Preview (Unreleased / Project Glasswing)
Claude Mythos Preview is Anthropic's most advanced frontier model, currently not publicly available due to cybersecurity concerns. Restricted to approximately 50 trusted organizations as part of Project Glasswing. LLM Stats composite score: 72.5 (top of the entire leaderboard). GPQA Diamond: 94.6%. When Mythos ships publicly, it will become the new flagship and Opus will shift to mid-range positioning. Anthropic confirmed in the Opus 4.8 launch post that Mythos-class general availability is expected within weeks.
3. OpenAI: GPT-5.5, GPT-5.4 Pro, and GPT-OSS
OpenAI released GPT-5.5 in April 2026 as its current flagship, scoring 60.2 on the Artificial Analysis Intelligence Index (second to Claude Opus 4.8's 61.4). The GPT-5 family spans proprietary flagships to open-weight releases.
GPT-5.5 (Flagship)
OpenAI's current flagship, built for agentic and professional work: coding, tool use, research, and long-horizon tasks. SWE-bench Pro: 58.6%, Terminal-Bench 2.0: 82.7% (different benchmark version than Anthropic's 2.1). AA Intelligence Index: 60.2. Pricing: approximately $15/$30 per million tokens for standard/Pro tiers. 1.1M token context window. GPT-5.5 wins on creative writing (leads Creative Writing v3 benchmark) and agentic/terminal workflows. Plans range from free to $200/month on ChatGPT. Full computer use and Tool Search built in. Best for: teams already in the OpenAI ecosystem, creative writing, and complex agentic CLI work.
GPT-5.4 Pro
The mid-tier flagship from OpenAI's Q1 2026 wave. SWE-bench Pro: ~43.4% on Scale's standardized harness (59.1% on the xHigh effort tier). Competitive with Gemini 3.1 Pro on document comprehension. Broadly available across API and ChatGPT Plus tiers.
GPT-OSS (Open Weights)
OpenAI's open-weight release. Ships in two sizes: GPT-OSS 120B and GPT-OSS 20B. Available on Hugging Face under OpenAI's open model license. The 120B variant competes with Llama 4 Maverick on reasoning benchmarks and represents OpenAI's first serious move into the open-weight market after years of proprietary-only releases.
4. Google DeepMind: Gemini 3.1 Pro, Gemini 3.5 Flash, and Gemma 4
Google DeepMind wins the reasoning and scientific knowledge categories outright in 2026. Gemini 3.1 Pro leads GPQA Diamond at 94.3% and ARC-AGI-2 at 77.1%. The Gemma open-weight line competes aggressively with Meta's Llama 4
Gemini 3.1 Pro (Flagship)
Released February 19, 2026, Gemini 3.1 Pro is the reasoning and multimodal leader. GPQA Diamond: 94.3% (highest of any model). ARC-AGI-2: 77.1% (more than double its previous version's score). SWE-bench Verified: 80.6%. AA Intelligence Index: 57. Pricing: $2/$12 per million tokens. Accepts text, images, audio, video, and code in a single 1M token context window. Important caveat: Gemini generates 20-30% more tokens per task than Claude or GPT, which erodes the pricing advantage at scale. Best for: scientific reasoning, research workflows, multimodal inputs, Google Workspace integration.
Gemini 3.5 Flash (Fast Tier)
Google's fast, cost-optimized model. SWE-bench Verified: ~78.8% (third-party estimate). Pricing: approximately $1.50/$9.00 per million tokens. The 3.3x input cost gap versus Opus 4.8 makes it the default recommendation for high-volume workloads where maximum frontier capability is not required. 1M token context window.
Gemma 4 (Open Weights, Apache 2.0)
Available in sizes from 1B to 27B parameters. Gemma 4 31B outperforms Llama 4 Maverick on math (AIME 2026: 89.2% vs 88.3%) and coding (LiveCodeBench: 80.0% vs 77.1%). Ships under Apache 2.0 with no MAU restrictions (unlike Llama 4's Meta Community License). The 4B and 12B variants are the strongest options for on-device or edge deployment. For the full open-source comparison, see Best Open-Source LLMs 2026.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. xAI: Grok 4.3 and Grok 4.20 Expert Mode
xAI's Grok models occupy a unique position: strong on Humanity's Last Exam (frontier knowledge) and the most affordable of the Big 4 frontier models. Grok 4.3 is the April 2026 release; Grok 4.20 Expert Mode is the heavy-reasoning variant with a 2M context window
Grok 4.3
AA Intelligence Index: 53. Grok 4.3 jumped from 25/100 to 72/100 (Tier B) on the independent LLM coding benchmark from May 2026 — a massive generational improvement over Grok 4.20. Added native video input (MP4/MOV/WEBM up to 5 minutes at 1080p) and document generation, making it one of only six frontier models with full video processing as of June 2026. However, best features (Expert Mode, extended thinking) are locked behind the $300/month SuperGrok Heavy tier. Always-on reasoning that cannot be disabled. Best for: Humanity's Last Exam tasks, cost-conscious frontier users, reasoning-heavy research.
Grok 4.20 Expert Mode
The maximum reasoning tier for xAI's model. 2M token context window (largest of any frontier model). Leads Humanity's Last Exam at 50.7% — the hardest benchmark available, designed to resist memorization. Grok 4.20 Expert Mode is the right pick when your work requires cutting-edge scientific knowledge at the absolute frontier. Warning: Every reasoning model tested in May 2026 exceeded 10% hallucination rate on Vectara's dataset. Grok is no exception.
6. Meta: Llama 4 Maverick, Llama 4 Scout, and Muse Spark
Meta's 2026 AI strategy splits across two tracks: the open Llama 4 family (strong open-source flagships) and Muse Spark, a closed model from the newly formed Meta Superintelligence Labs.
Llama 4 Maverick (Flagship Open)
Meta's flagship open-weight model for 2026. AIME 2026: 88.3%, GPQA Diamond: 82.3%, LiveCodeBench: 77.1%. Ships under Meta's Community License (commercial use permitted up to 700M monthly active users). Gemma 4 31B outperforms Maverick on math, reasoning, and coding while shipping under the more permissive Apache 2.0 license with no MAU restrictions. Still a strong pick for teams in the Meta/PyTorch ecosystem. The AI agent frameworks on Build Fast with AI cover how to integrate Llama 4 into agentic pipelines.
Llama 4 Scout (10M Token Context)
Llama 4 Scout ships with a 10 million token context window — by far the largest of any open-weight model and competitive with proprietary long-context offerings. The tradeoff: benchmark scores on reasoning and coding fall below Maverick. Scout is the pick for teams doing whole-repository analysis, large-scale document processing, or any workload where context length is the primary constraint. The 256K context window of Gemma 4 and Kimi K2.6 cannot compete here.
Muse Spark (Closed, Meta Superintelligence Labs)
Muse Spark is Meta's closed-weights frontier model, developed by the newly formed Meta Superintelligence Labs. SWE-bench Pro (Scale SEAL): 55.0% on the standardized harness, placing it second behind GPT-5.4 xHigh at 59.1%. Not publicly available for self-hosting. Signals Meta's strategic pivot toward a closed-plus-open dual track, similar to how Google operates Gemini alongside Gemma.
7. DeepSeek: V4 Pro, V3.2-Exp, and R1
DeepSeek is the pricing disruptor of 2026. DeepSeek V4 Flash at $0.28/M output tokens versus GPT-5.5's ~$30/M is a 107x price difference for competitive benchmark performance. The MIT license, open weights, and competitive pricing make DeepSeek the default recommendation for cost-sensitive teams and high-volume production deployments.
DeepSeek V4 Pro
Released April 24, 2026. 1.6 trillion total parameters, 49 billion activated per token (MoE architecture). 1M token context window. Introduces a hybrid attention architecture (Compressed Sparse Attention + Heavily Compressed Attention) that requires only 27% of single-token inference FLOPs vs V3.2 at 1M context. SWE-bench Verified: 80.6%. GPQA Diamond: 90.1%. Terminal-Bench 2.0: 67.9%. Pricing: $0.43/$0.87 per million tokens (standard, after June 2026 promo ended). MIT license. For the full DeepSeek V4 Pro benchmark and pricing guide, including the Pro/Flash architecture comparison.
DeepSeek V3.2-Exp
The experimental iteration of the V3 series, still available via the public API and serving as a cost-conscious alternative to V4 Pro. Approximately 90% of GPT-5.4 quality. Roughly $0.28/M output tokens on DeepSeek's API. For teams not yet ready to migrate to V4's new architecture, V3.2-Exp remains a solid production choice.
DeepSeek R1 (Reasoning Model)
DeepSeek R1 is the reasoning-specialized model in the DeepSeek lineup. MIT license, fully open weights. Strong on mathematics and logic-chain tasks. Competes with OpenAI's o-series reasoning models at a fraction of the price. DeepSeek leads all evaluated models on LiveCodeBench (93.5) and Codeforces (3,206) — including closed frontier APIs — positioning V4 Pro as the current agentic coding reference for open weights.
8. Alibaba Qwen: Qwen 3.7 Max, Qwen 3.6, and Qwen 3.5
Alibaba's Qwen family covers the full spectrum from API-only flagship to open Apache 2.0 weights. Qwen 3.7 Max is the cheapest top-10 model at $1.53 per million blended tokens; Qwen 3.5 at 397B parameters is the most capable open-weight Alibaba model
Qwen 3.7 Max (API-Only, Closed)
Alibaba closed the weights on Qwen 3.7 Max in May 2026 — the first time Alibaba's flagship has gone API-only. LLM Stats reasoning score: 60.3. SWE-bench Pro: 60.6%, Terminal-Bench 2.0: 69.7%. Pricing: approximately $2.50/$7.50 per million tokens. Qwen 3.7 Max is cheaper than Opus 4.8 and GPT-5.5 at comparable benchmark tiers and ships text-only (no vision or audio), making it the strongest code-only model in the field for teams that do not need multimodal inputs. Always-on reasoning that cannot be disabled
Qwen 3.6 (Open, Apache 2.0)
The open-weight flagship from Alibaba. Hybrid architecture (linear attention + sparse MoE routing). Available via Ollama, Hugging Face, and Together AI. 1M token context window. Qwen 3.6 Plus (proprietary variant) is the only open-weight model in the Kimi/GLM/DeepSeek/Qwen cluster with 1M context support, making it the pick for whole-monorepo analysis that cannot fit in a 262K window.
Qwen 3.5 (397B MoE, Apache 2.0)
Qwen 3.5 at 397B total / 17B active parameters. Updated May 2026. Leads open weights on GPQA Diamond at 88.4%. Apache 2.0 with no MAU restrictions. If you want Alibaba's frontier quality without the closed-weights constraint of Qwen 3.7 Max, Qwen 3.5 is the answer.
9. Mistral AI, Microsoft Phi, and NVIDIA Nemotron
Mistral Large 3 (Flagship MoE)
Mistral AI's most capable model, using a Mixture-of-Experts architecture. Strong on coding and agentic workflows. Devstral 2 is Mistral's coding-specialized variant, available on Ollama Cloud and competing directly with Qwen and GLM on frontend UI tasks. Mistral's pricing remains competitive with DeepSeek at the mid-tier.
Mistral Small 4
A dense, fast model optimized for instruction following, RAG workloads, and enterprise knowledge retrieval. Best positioned against Claude Haiku 4.5 and GPT-4.1 Mini for cost-effective production deployments. Ministral 3 is the edge variant for on-device deployment scenarios.
Codestral (Coding Specialist)
Mistral's dedicated coding model. Competes with DeepSeek V4 Flash and GLM-5.1 in the coding-specialist tier. Available via Mistral API and optimized for IDE integrations via Cursor and Windsurf.
Microsoft Phi-4 and Phi-4 Mini
Microsoft's Phi-4 is a reasoning-focused model designed for efficiency at small parameter counts. Phi-4 Mini is optimized for edge and on-device deployment where model size matters. Neither competes at the frontier on composite benchmarks, but both significantly outperform their parameter count suggests on specific reasoning tasks — the defining characteristic of the Phi family since its debut. For the full comparison of NVIDIA's strategy across physical AI and LLMs, see NVIDIA AI Models 2026: Full Guide, Rankings & Comparisons.
NVIDIA Nemotron 3 Ultra and Nemotron Cascade 2
NVIDIA Nemotron 3 Ultra: 550B parameters, fully permissive license, released June 4, 2026. Built on a Mamba-Transformer MoE hybrid architecture. Nemotron 3 Super scored 60.47% on SWE-bench Verified and delivers 2.2x throughput over previous-generation models. Nemotron Speech achieves 10x faster real-time ASR than comparable models. NVIDIA's differentiation is not at the LLM text reasoning tier (where OpenAI and Google lead) but at the physical AI, robotics, and voice layers where they have a near-monopoly. Nemotron Cascade 2 is the latest in the cascade inference architecture family.
10. Zhipu AI (GLM), Moonshot AI (Kimi), Xiaomi MiMo, MiniMax, and Cohere
Zhipu AI / Z.ai: GLM-5.2 and GLM-5.1
GLM-5.2 landed June 13, 2026, with a 1M token context window and MIT license. GLM-5.1 (released April 7, 2026) is a 754B MoE parameter model with 94.6% of Claude Opus coding performance at $3/month via the GLM Coding Plan. SWE-bench Pro: 58.4%. Code Arena Elo: 1,530 (third globally on agentic web development). Independently verified. GLM-5.1 is the best budget coding model for enterprise teams that need Claude-level output without Claude-level pricing. Hot take: GLM-5.1 at $3/month vs Claude Opus at $100-200/month is not a niche optimization. It is a pricing disruption that most enterprise teams have not processed yet.
Moonshot AI (Kimi): K2.7 Code and K2.6
Kimi K2.7 Code (released June 12, 2026) uses a 1 trillion parameter MoE architecture with 32B active parameters. 81.1% on MCP Mark Verified tool-use accuracy, beating Claude Opus 4.8's 76.4% on the same benchmark. Roughly 30% fewer reasoning tokens than K2.6. Mandatory thinking mode (cannot be disabled). Price: $0.95/M input tokens. Modified MIT license. Kimi K2.6 (April 2026) supports up to 300 parallel sub-agents and sustained 4,000+ tool calls over a 13-hour uninterrupted session in published benchmarks. The most capable open-weight model for long-horizon agentic coding. For the complete Kimi K2 comparison, see the Best AI Models June 2026 Full Leaderboard.
Xiaomi MiMo-V2.5-Pro
Xiaomi's MiMo-V2.5-Pro is the most recent flagship from the consumer electronics giant turned AI lab. Competes in the efficient reasoning segment. Xiaomi's entry into frontier LLMs reflects the broader trend of Chinese hardware companies building model capabilities in-house, similar to NVIDIA's strategy in the West.
MiniMax M3
Released June 1, 2026. MiniMax M3 tops open-weight SWE-bench Pro at 59.0% (edging past Kimi K2.6 at 58.6%). GPQA Diamond: 92.68%. LiveCodeBench: 82.15%. New sparse attention architecture (MSA) that cuts per-token compute at 1M context to roughly one-twentieth of the previous generation. Price: $1.20/M output tokens. Native multimodality: text, image, and video in a single model. MiniMax M3 is the open-weight model to watch in H2 2026, combining frontier coding with multimodal capability at prices that undercut every closed model.
Cohere Command A
Cohere's Command A is the enterprise RAG and retrieval specialist. Optimized for document-heavy knowledge retrieval pipelines, enterprise compliance environments, and multi-step tool use. Cohere's strength is not raw benchmark performance but production enterprise deployment: private deployment, data privacy controls, and fine-tuning APIs that most frontier labs do not offer at equivalent pricing.
11. Master Comparison Table: All 18 Models Head-to-Head
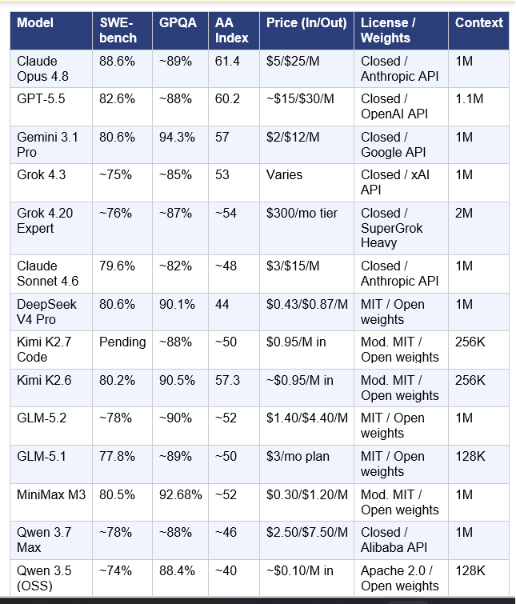
Note: Benchmarks marked with ~ are third-party estimates or vendor-reported scores awaiting independent verification. All figures sourced from Artificial Analysis, LLM Stats, vals.ai, and official model launch posts as of June 21, 2026.
12. Category Winners: Best Model Per Task in June 2026
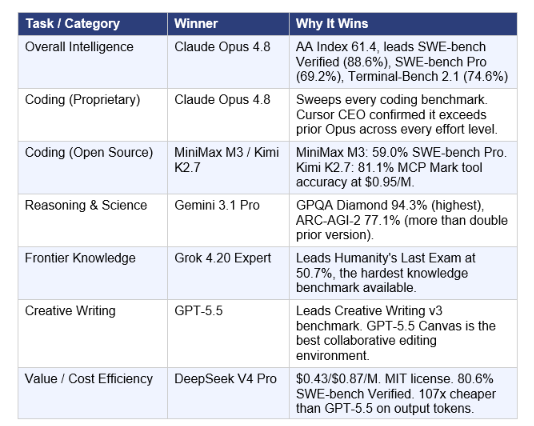
13. The Value Gap: Open Source vs Proprietary in 2026
The most important structural shift in June 2026 is not who built the smartest model. It is how narrow the capability gap between open and closed models has become relative to the pricing gap. DeepSeek V4 Flash ($0.28/M output) versus GPT-5.5 (~$30/M output) is a 107x price difference for roughly 85-90% of the performance. For most applications, that 10-15% performance delta does not justify the 100x cost premium.
The correct routing architecture for mid-2026 is not 'pick one model'. It is intelligent routing: run GLM-5.1 or DeepSeek V4 Flash for high-volume batch tasks, Claude Opus 4.8 or GPT-5.5 for edge cases that require maximum capability, and Kimi K2.7 Code or MiniMax M3 for specialized coding pipelines where tool-use accuracy matters more than general reasoning. For the implementation patterns behind this approach, see Best AI Models May 2026 on Build Fast with AI which covers the multi-model routing architecture in detail.
My contrarian take: the teams losing the most in this environment are the ones that picked a model 18 months ago, built everything around its API, and now face a migration cost that is higher than the cost of switching would have been in the first place. Build model-agnostic from day one. The routing layer is where the real competitive advantage lives, not the model selection.
FAQ: Best AI Models June 2026
Which AI model is #1 overall in June 2026?
Claude Opus 4.8 leads the Artificial Analysis Intelligence Index at 61.4, ahead of GPT-5.5 (60.2), Gemini 3.1 Pro (57), and Grok 4.3 (53). For category-specific winners, the answer changes: Gemini 3.1 Pro wins reasoning (GPQA Diamond 94.3%), GPT-5.5 wins creative writing, and DeepSeek V4 Pro wins on value.
What is Claude Mythos Preview and how do I access it?
Claude Mythos Preview is Anthropic's most advanced model, not publicly available due to cybersecurity concerns. As of June 2026, it is accessible only to approximately 50 trusted organizations through Project Glasswing. Anthropic has indicated general availability is expected within weeks of the Claude Opus 4.8 launch (May 28, 2026).
Is DeepSeek V4 Pro truly open-source?
Yes. DeepSeek V4 Pro ships under the MIT license with open weights on Hugging Face. You can download, self-host, modify, and use it commercially without per-token fees. The API is also available at $0.43/$0.87 per million tokens, roughly 12x cheaper than Claude Opus 4.8.
What is the best open-source AI model in 2026?
As of June 2026, the top open-source models by benchmark are Kimi K2.6 (AA Index 57.3, 80.2% SWE-bench Verified), MiniMax M3 (59.0% SWE-bench Pro, 92.68% GPQA), DeepSeek V4 Pro (80.6% SWE-bench Verified, MIT), and GLM-5.2 (1M context, MIT). Choice depends on your task: MiniMax M3 for coding, Kimi K2.6/K2.7 for long-horizon agentic tasks, DeepSeek V4 Pro for cost-sensitive production, GLM-5.1 for budget enterprise coding.
How does Llama 4 Maverick compare to Gemma 4?
Gemma 4 31B outperforms Llama 4 Maverick on math (AIME 2026: 89.2% vs 88.3%), reasoning (GPQA Diamond: 84.3% vs 82.3%), and coding (LiveCodeBench: 80.0% vs 77.1%). Gemma 4 also ships under the more permissive Apache 2.0 license with no MAU restrictions. Llama 4 Scout wins on context window (10M tokens vs Gemma 4's 256K).
Do AI reasoning models hallucinate more than standard models?
Yes, paradoxically. Every reasoning model tested in May 2026 exceeded 10% hallucination rate on Vectara's dataset. GPT-5.5, Claude Sonnet 4.5, Grok 4, and Gemini 3 Pro all crossed that threshold. Non-reasoning models like Gemini Flash Lite scored 3.3%. The chain-of-thought process in reasoning models amplifies confident-sounding incorrect outputs. Always apply output validation in production pipelines.
Which AI model has the largest context window?
Llama 4 Scout holds the largest context window at 10 million tokens among publicly available models as of June 2026. Among frontier proprietary models, Grok 4.20 Expert Mode offers 2M tokens (largest), followed by Claude Opus 4.8, GPT-5.5, and Gemini 3.1 Pro at approximately 1M tokens each.
What is the cheapest frontier AI model in 2026?
DeepSeek V4 Flash holds the price floor at $0.14/$0.28 per million input/output tokens with open MIT weights. Among models with independently verified frontier-class benchmarks, DeepSeek V4 Pro ($0.43/$0.87) is the cheapest closed-frontier equivalent. GLM-5.1's $3/month Coding Plan is the most cost-effective subscription for enterprise coding workloads.
Recommended Blogs
- Best AI Models June 2026: Full Ranked Leaderboard
- Best AI Models May 2026: Winners, Losers & Full Comparison
- Latest AI Models April 2026: Rankings & Features
- Best Open-Source LLMs 2026: Qwen, GLM, DeepSeek & Llama Compared
- NVIDIA AI Models 2026: Full Guide, Rankings & Comparisons
- Best AI Models for Frontend UI Development 2026: Kimi K2.5, GLM-5, Qwen 3.6 Ranked
- LLM Scaling Laws Explained: Will Bigger AI Models Always Win? (2026)
Resources & Community
Join our community of 70,000+ AI enthusiasts and learn to build powerful AI applications! Whether you're a beginner or an experienced developer, Build Fast with AI helps you understand and implement AI in your projects.
- Website — buildfastwithai.com
- LinkedIn — Build Fast with AI
- Instagram — @buildfastwithai
- Founder Twitter — @satvikps
- Twitter — @BuildFastWithAI
Agentic AI Launchpad 2026
A structured 6-week cohort program that takes you from AI basics to building and deploying real-world agentic AI systems. Includes live sessions, expert mentorship, project reviews, and a builder community network.
Ready to go from learning to building? Join the next cohort: Agentic AI Launchpad 2026
Free AI Resources
Access free tools, workshops, and micro-learning to keep building:
- AI Workshops — Free resources, upcoming events & past recordings
- Unrot — Learn AI in 5 minutes a day (free micro-learning app)
Stay ahead of every model drop. Subscribe to Build Fast with AI for weekly breakdowns of the latest AI models, benchmarks, and builder tools delivered straight to your inbox.
References
- Artificial Analysis Intelligence Index — https://artificialanalysis.ai
- LLM Stats — Live Model Leaderboard (300+ models) — https://llm-stats.com
- BFWAI — Best AI Models June 2026 Full Ranked Leaderboard
- BFWAI — Best AI Models May 2026: Winners, Losers & Full Comparison
- Anthropic — Claude Opus 4.8 Launch Post (May 28, 2026)
- Anthropic — Project Glasswing (Claude Mythos Preview)
- Google DeepMind — Gemini 3.1 Pro Technical Report (February 2026)
- DeepSeek — V4 Pro Release Announcement and Hugging Face Model Card (April 24, 2026)
- MiniMax — M3 Launch Post (June 1, 2026)
- Moonshot AI — Kimi K2.7 Code Model Card (June 12, 2026)
- Z.ai — GLM-5.2 Release (June 13, 2026)
- vals.ai — SWE-bench Verified Leaderboard (June 2026 snapshot)
- Scale AI — SWE-bench Pro SEAL Leaderboard

