





GPT-5.5 Review 2026: Benchmarks, Mixed Reactions & What It Actually Means
Six weeks. That's the gap between GPT-5.4 (March 5, 2026) and GPT-5.5 (April 23, 2026). OpenAI isn't releasing at this pace because it's ahead. It's releasing at this pace because the race is tighter than it has ever been.
GPT-5.5, codenamed "Spud" internally, became ChatGPT's default model on May 5. It's the first fully retrained OpenAI base model since GPT-4.5 -- every model in between was an incremental update built on the same foundation. This one is a ground-up rebuild, and that distinction matters.
The launch stirred strong reactions: developer praise, a controversial quote from Sam Altman, benchmark debates, and real questions about whether the 2x price hike is justified. I dug through the 100-page system card, independent benchmark data, and developer community feedback to give you the actual picture.
What Is GPT-5.5 and What Makes It Different
GPT-5.5 is the most capable model OpenAI has shipped as of April 23, 2026 -- and the first to be completely rebuilt from scratch since GPT-4.5. Three architectural decisions separate it from every model OpenAI has released in the past year:
Natively omnimodal. Previous OpenAI "multimodal" models were essentially separate models stitched together with routing logic. GPT-5.5 processes text, images, audio, and video through a single unified architecture -- end-to-end, no hand-offs between subsystems.
Hardware co-designed with NVIDIA. GPT-5.5 was co-designed alongside NVIDIA's GB200 and GB300 NVL72 rack-scale systems. The result: GPT-5.5 matches GPT-5.4's per-token latency despite being substantially more capable. Bigger models are usually slower. This one isn't.
Self-improving infrastructure. GPT-5.5 and Codex rewrote OpenAI's own serving infrastructure before launch. Codex analyzed weeks of production traffic and wrote custom load-balancing heuristics that increased token generation speeds by over 20%. The model tuned the system that runs it.
I think the self-improving infrastructure detail is the one that deserves more attention. It's not a benchmark. It's a signal about what these models are becoming.
GPT-5.5 Benchmarks: Full Breakdown vs Claude Opus 4.7
GPT-5.5 retakes the overall performance lead for OpenAI -- but the picture is more nuanced than most headlines suggest. On some benchmarks, it wins decisively. On others, Claude Opus 4.7 still leads. Here's the full table, sourced from OpenAI's official announcement and verified against third-party data from Vellum AI and LLM Stats.
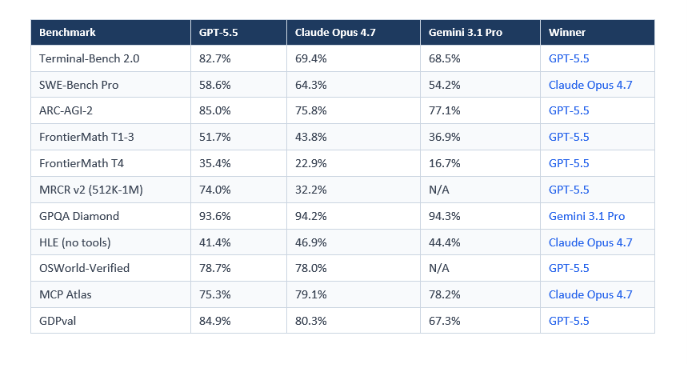
Source: OpenAI GPT-5.5 announcement, Vellum AI benchmark analysis, LLM Stats. Figures are vendor-reported unless otherwise noted.
Where GPT-5.5 Wins Decisively
Agentic Coding: Terminal-Bench 2.0
GPT-5.5 scores 82.7% on Terminal-Bench 2.0, versus Claude Opus 4.7's 69.4% -- a 13-point lead. This benchmark tests real command-line workflows: planning, iteration, and multi-tool coordination in a sandboxed terminal. For developers building unattended pipeline runners or DevOps automation agents, no publicly available model is close.
Early testers described a model that understands the shape of a system: why something is failing, where the fix needs to land, and what else in the codebase would be affected. CodeRabbit published independent testing showing GPT-5.5 improved expected issue found rate from 55% to 65% in real-world pull request reviews, with precision rising from 11.6% to 13.2%.
Long-Context: The Most Underreported Improvement
On MRCR v2 at 512K-1M token contexts, GPT-5.5 jumps to 74.0% from GPT-5.4's 36.6% -- a 37-point improvement. At 128K-256K tokens, it scores 87.5% versus Claude's 59.2%.
The API supports a 1M token context window (400K in Codex). If your workflows involve processing entire codebases, large document sets, or multi-session conversation logs, this is a qualitative leap worth taking seriously.
Abstract Reasoning: ARC-AGI-2
GPT-5.5 scores 85.0% on ARC-AGI-2, versus Claude Opus 4.7's 75.8% and Gemini 3.1 Pro's 77.1%. ARC-AGI-2 tests novel pattern recognition that cannot be solved by memorization -- which means this gap is more meaningful than most benchmark gaps.
Scientific Research
GPT-5.5 shows strong performance on GeneBench (multi-stage genetic data analysis) and BixBench (real-world bioinformatics). OpenAI describes it as a 'bona fide co-scientist' capable of handling problems that represent multi-day projects for human domain experts.
Where Claude Opus 4.7 Still Leads
The honest summary: Claude Opus 4.7 holds the lead on the benchmarks that matter most for real software engineering workflows.
- SWE-Bench Pro: Claude Opus 4.7 scores 64.3% versus GPT-5.5's 58.6%. This is the harder, less contaminated version of the software engineering benchmark -- the one that's more representative of production coding work.
- Humanity's Last Exam (no tools): Claude scores 46.9% versus GPT-5.5's 41.4%. HLE tests graduate-level reasoning in biology, physics, and chemistry -- the domain where Anthropic's Constitutional AI training seems to show up.
- MCP Atlas tool orchestration: Claude leads 79.1% vs 75.3%. For teams running complex multi-tool agent workflows, Claude's tool coordination is still the benchmark leader.
- GPQA Diamond: Gemini 3.1 Pro leads here at 94.3%, with Claude at 94.2% and GPT-5.5 at 93.6% -- all three within rounding error, but GPT-5.5 is third.
For developers doing heavy agentic coding, Claude Opus 4.7 at $5/$25 per million tokens also offers better price-performance for API-heavy workflows.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
The Hallucination Drop: 52.5% Fewer Errors
According to OpenAI's system card, GPT-5.5 reduces hallucinations by nearly 52.5% compared to predecessor models, with the most significant improvements in domains like medicine and law -- where accuracy isn't optional.
This number comes from OpenAI's internal evaluation, so treat it with appropriate skepticism until independent testing corroborates it. What I can say is that developer feedback on X and dev communities consistently describes GPT-5.5 as noticeably more reliable for factual recall and better at saying 'I don't know' rather than fabricating answers.
The model also introduces adjustable reasoning levels: low reasoning for fast, simple tasks, and higher reasoning modes for complex problem-solving -- similar to the extended thinking features Anthropic introduced with Claude. This flexibility is useful if you're building applications that need to balance latency against accuracy.
Developer Reactions and Community Sentiment
The GPT-5.5 launch landed in two very different ways across the community.
The praise was specific. DHH (creator of Ruby on Rails) praised the model's speed and concise outputs for agentic coding. Greg Brockman called it 'one step closer to OpenAI's super app.' Developers at NVIDIA -- where 10,000+ employees now have Codex access -- described the Codex integration as restructuring how engineering work gets done.
The controversy was also specific. Sam Altman's off-hand description of GPT-5.5 as an 'autistic genius' during the press briefing spread across X and generated significant backlash from disability advocates and community members, many of whom called the framing reductive and harmful. OpenAI did not issue a formal statement.
From a product perspective, the community comparisons are fairly consistent: GPT-5.5 wins on front-end design assistance, retrieval quality, long-context tasks, and agentic terminal work. It trails on advanced multi-file software engineering tasks and complex reasoning chains where Claude holds the lead.
A few developers reported switching from Claude Code to GPT-5.5-powered Codex and calling it a workflow improvement. I'd say that's plausible on Terminal-Bench data, but recommend running your own evaluation before switching infrastructure based on benchmarks alone.
GPT-5.5 Pricing, Availability and Token Efficiency
GPT-5.5 is available now in ChatGPT (Plus, Pro, Business, Enterprise, Edu) and Codex with a 400K context window. API access launched at $5/$30 per million input/output tokens -- a 2x increase over GPT-5.4.
OpenAI claims 40% fewer tokens per task in Codex workflows, which partially offsets the price increase. If that holds on your workloads, the effective cost increase is closer to 20% rather than 100%. Verify this on your own tasks before making budget decisions based on that number.
For teams running high-volume standalone API queries rather than agentic Codex loops, the 2x price increase is real and Claude Opus 4.7 at $5/$25 is competitive at comparable capability on most benchmarks.
Context windows: 1M tokens via API, 400K in Codex. Knowledge cutoff: December 2025.
The Super App Strategy: Why Benchmarks Miss the Point
Here's the thing I keep coming back to: OpenAI's six-week release cadence isn't really about beating Claude on SWE-bench Pro.
Greg Brockman's framing at the press briefing -- 'one step closer to the creation of OpenAI's super app' -- is the actual signal. The super app strategy is convergence: ChatGPT (conversation) + Codex (coding) + AI browser (in development) + GPT-Image-2 (visual generation) -- all merging into a single interface where AI can see your screen, read your files, browse the web, write and run code, and generate outputs in one session.
The NVIDIA integration makes this concrete. 10,000+ NVIDIA employees across engineering, legal, marketing, and HR now have GPT-5.5-powered Codex access. Jensen Huang's internal email calling it a 'jump to lightspeed' moment is a landmark data point: this isn't a developer tool anymore. A company of 30,000 people is restructuring around it.
The company that gets tens of millions of ChatGPT users standardized on its interface -- and enterprises locked into annual procurement contracts -- wins the enterprise AI race regardless of which model scores highest on SWE-bench Pro in Q3 2026. That's the bet OpenAI is making. And the six-week release cadence is how you win it.
Want to build AI agents and apps using the latest frontier models.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
Frequently Asked Questions
What is GPT-5.5?
GPT-5.5, codenamed 'Spud' internally, is OpenAI's most capable frontier model, released April 23, 2026. It's the first fully retrained OpenAI base model since GPT-4.5, built with a natively omnimodal architecture and co-designed with NVIDIA's GB200/GB300 hardware. It became ChatGPT's default model on May 5, 2026.
How does GPT-5.5 compare to Claude Opus 4.7?
GPT-5.5 leads on Terminal-Bench 2.0 (82.7% vs 69.4%), ARC-AGI-2 (85.0% vs 75.8%), and long-context retrieval (MRCR v2: 74.0% vs 32.2%). Claude Opus 4.7 leads on SWE-Bench Pro (64.3% vs 58.6%), Humanity's Last Exam without tools (46.9% vs 41.4%), and MCP Atlas tool orchestration (79.1% vs 75.3%). Neither wins everywhere.
Does GPT-5.5 really reduce hallucinations by 52.5%?
That figure comes from OpenAI's internal system card evaluation, with improvements concentrated in medicine and law domains. Independent third-party corroboration is still limited. Developer sentiment on X is consistent with improved factual reliability, but treat the 52.5% number as a directional claim until external testing confirms it.
What is GPT-5.5 Instant?
GPT-5.5 Instant is the fast, cost-efficient tier of the GPT-5.5 family, designed for lower-latency tasks where reasoning depth is less critical. It became ChatGPT's default model on May 5, 2026, replacing GPT-5.4 Instant for most users.
How much does GPT-5.5 cost?
API pricing is $5 per million input tokens and $30 per million output tokens -- a 2x increase over GPT-5.4. OpenAI claims 40% token efficiency gains in Codex workflows, which reduces the effective cost increase to around 20% for agentic use cases. Standard API query workloads pay the full 2x increase.
Is GPT-5.5 available for free?
No. GPT-5.5 and GPT-5.5 Pro are not available to free-tier ChatGPT users. Access requires a Plus, Pro, Business, Enterprise, or Edu subscription. API access is billed at $5/$30 per million tokens.
What is the GPT-5.5 context window?
GPT-5.5 supports a 1 million token context window via the API. In Codex, the context window is 400K tokens. The knowledge cutoff is December 2025.
What was Sam Altman's 'autistic genius' comment about?
During the GPT-5.5 press briefing, Sam Altman described the model as an 'autistic genius' in what appeared to be an off-hand remark about its reliability and narrow specialization in certain tasks. The phrase spread widely on X and generated significant backlash from disability advocates, who called the framing reductive. OpenAI did not issue a public response.
Recommended Reads
If you found this useful, these posts from Build Fast with AI go deeper on related topics:
- GPT-5.5 Review: Benchmarks, Pricing & Vs Claude (2026)
- Best AI Models April + May 2026: Full Leaderboard (GPT-5.5, Claude Opus 4.7, DeepSeek V4)
- Best AI Models April 2026: Ranked by Benchmarks
- LLM Scaling Laws Explained: Will Bigger AI Models Always Win? (2026)
- Best AI Models Leaderboard: April 2026 Update
References
- Introducing GPT-5.5 - OpenAI Official Announcement
- Everything You Need to Know About GPT-5.5 - Vellum AI
- GPT-5.5 Benchmark Results (CodeRabbit) - CodeRabbit
- GPT-5.5 Benchmarks, Pricing & Context Window - LLM Stats
- GPT-5.5 Review: Benchmarks, Pricing & Vs Claude - Build Fast with AI
- Best AI Models Leaderboard: April 2026 Update - Build Fast with AI

