




GLM-5.2 vs Claude Opus 4.8 vs GPT-5.6 vs Kimi K2.7: Best Coding AI Model (2026)
On June 13, 2026, Z.ai (formerly Zhipu AI) released GLM-5.2, a 753 billion parameter open-weight coding model under a fully permissive MIT license. Six days later, the published benchmark suite confirmed what early testers suspected: GLM-5.2 scores 62.1% on SWE-bench Pro, closes to within four points of Claude Opus 4.8 on Terminal-Bench 2.1 (81.0% vs 85.0%), and beats GPT-5.5 outright on the same benchmark. It does all of this at $1.40 per million input tokens and $4.40 per million output tokens, roughly one-sixth the cost of a closed frontier model. This is the comparison that matters most for any team choosing a coding model in mid-2026: GLM-5.2 against the three models it is most directly being benchmarked against in the wild. Claude Opus 4.8 (Anthropic's current public flagship, since Claude Opus 5 has not shipped and the tier above Opus, Fable 5, remains export-restricted as of this writing). GPT-5.6 (OpenAI's newest model family, Sol/Terra/Luna, in limited preview as of June 26, 2026). And Kimi K2.7, Moonshot AI's most recent K2-series release, the natural successor to the Kimi 2.5 line that started this category of cheap, capable, open-weight coding models in January 2026. We break this down across the eight dimensions that actually decide which model wins for your specific workload: raw coding ability, SWE-bench scores specifically, agentic task performance, context window, price, UI and frontend generation, startup fit, and a final verdict you can act on.
1. Quick Verdict Table
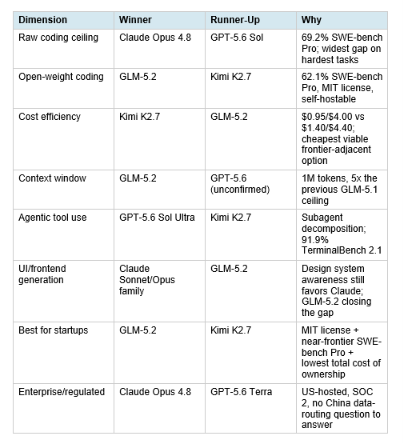
Hot take: there is no single winner in 2026 anymore, and pretending otherwise wastes money. The real skill is routing the right task to the right model. GLM-5.2 for self-hosted or budget-constrained coding work. Claude Opus 4.8 for the hardest multi-file refactors where correctness matters more than cost. GPT-5.6 for agentic workflows that benefit from subagent parallelism. Kimi K2.7 for high-volume tool-calling pipelines where token efficiency compounds. Model loyalty is the wrong strategy. Model routing is the right one.
2. The Four Models at a Glance
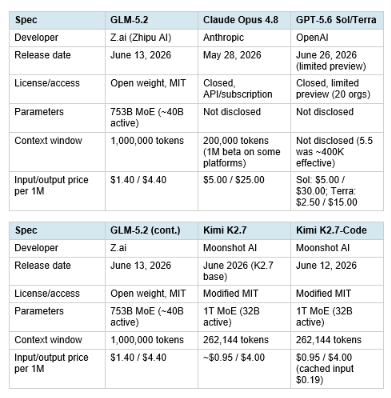
The lineage worth knowing: this is not the first time these four labs have been benchmarked head to head. The Qwen 3.6 Plus vs GLM-5.1 vs Kimi 2.5 comparison from April 2026 covered the previous generation of this exact race, when GLM-5.1 first beat Claude Opus 4.6 on SWE-bench Pro and Kimi 2.5 (the model the original Kimi 2.5 vs GLM 5.2 framing references) led on LiveCodeBench. GLM-5.2 is the direct sequel to that story, and the gap to closed-source models has narrowed further since.
3. Coding: General Capability
GLM-5.2's headline claim is closing the gap to frontier closed models, and the independent confirmation backs this up. Artificial Analysis, the independent benchmark house most frequently cited for cross-model comparisons, confirmed GLM-5.2 as the top-ranked openly available language model on the market following its release. On Terminal-Bench 2.1, a benchmark focused on autonomous terminal-based coding, GLM-5.2 scored 81.0 (82.7 with its best harness), landing within four points of Claude Opus 4.8's 85.0 and ahead of every other open-weight model tested. The generational jump from GLM-5.1 to GLM-5.2 is the steepest single-release improvement Zhipu has shipped: DeepSWE leaps from 18.0 to 46.2, Terminal-Bench from 63.5 to 81.0, and ProgramBench from 50.9 to 63.7. That is not incremental tuning. That is a structurally different model.
Claude Opus 4.8 remains the strongest closed-source coding model on the hardest tasks specifically. Anthropic's own framing is honest about this: Opus 4.8 is 'a modest but tangible improvement' over 4.7, but the SWE-bench Pro jump from 64.3% to 69.2% is real, and the gap to every other model widens on the most contamination-resistant benchmark variant. The honesty improvement Anthropic shipped alongside it (Opus 4.8 is roughly four times less likely to let a code flaw pass without flagging it) is a quality-of-life upgrade that benchmark scores do not capture but every engineer who has used it notices immediately.
GPT-5.6 Sol and Sol Ultra are the newest entrants and currently the hardest to evaluate independently, since the model remains in limited preview to roughly 20 partner organizations as of this writing. The vendor-reported TerminalBench 2.1 figures (Sol Ultra at 91.9%, Sol at 88.8%) would put GPT-5.6 ahead of Claude Opus 4.8 on that specific benchmark if independently confirmed at general availability. The full breakdown of GPT-5.6's coding claims, including the subagent-based Sol Ultra architecture, is covered in the GPT-5.6 review on Build Fast with AI.
Kimi K2.7 sits in a different competitive lane: not chasing the absolute coding ceiling, but optimizing token efficiency and tool-calling accuracy for long agentic sessions. It posts a roughly 30% reduction in reasoning token usage versus K2.6 and beats Claude Opus 4.8 outright on MCP Mark Verified (81.1 vs 76.4), a benchmark for correct tool invocation through the Model Context Protocol. For pure code-generation quality on hard, single-shot problems, it trails GLM-5.2, Claude Opus 4.8, and GPT-5.6. For tool-heavy multi-step agent pipelines where the model calls APIs hundreds of times per task, that MCP Mark lead matters more than raw SWE-bench score.
4. SWE-Bench: The Benchmark That Matters Most
SWE-bench Pro is the benchmark every serious coding model comparison in 2026 ultimately gets reduced to, because it is the hardest variant resistant to training-data contamination: it restricts the test set to issues that only models scoring above 50% on the original SWE-bench Verified consistently solve.
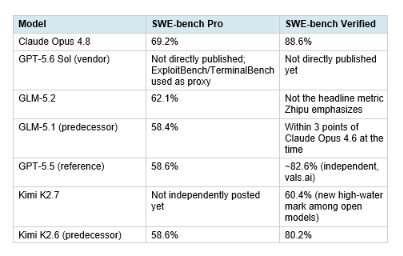
Read the table carefully: GLM-5.2's 62.1% SWE-bench Pro is a 3.7-point gain over GLM-5.1, decisively ahead of GPT-5.5's 58.6%, and within seven points of Claude Opus 4.8's 69.2%. That seven-point gap, on the hardest contamination-resistant coding benchmark available, between a free MIT-licensed model and the most capable closed-source coding model on the market, is the single most important number in this entire comparison. Six months ago that gap was structurally unbridgeable. It no longer is. Important caveat that every credible source flags: SWE-bench Pro scores are sensitive to agent scaffolding, with 4 to 10 point swings depending on harness configuration. A 1 to 3 point gap between any two models on this table is noise, not signal. The meaningful comparisons are the wider gaps: Claude Opus 4.8 over GPT-5.5 (10.6 points) is real. GLM-5.2 over GPT-5.5 (3.5 points) is at the edge of meaningful. For the deeper benchmark-reading methodology that explains why this matters, our GLM-5.1 open-source review covers the harness-sensitivity issue in detail.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Agent Tasks: Long-Horizon and Tool Use
- GLM-5.2: manages a full plan-execute-test-fix-optimize loop autonomously. The GLM-5.1 predecessor demonstrated 8 continuous hours of autonomous operation building a Linux desktop environment across 655 iterations. GLM-5.2's FrontierSWE score of 74.4% nearly ties Claude Opus 4.8's 75.1% on long-horizon task completion specifically, a near-dead-heat on the metric that most directly measures whether a model can be trusted to work unsupervised.
- Claude Opus 4.8: ships with dynamic workflows, where Claude Code plans a task and fans it out across hundreds of parallel subagents in a single session, each verified before the final report. This is the feature Anthropic built specifically for codebase-wide migrations: framework upgrades and API deprecations across hundreds of thousands of lines, from kickoff to merge.
- GPT-5.6 Sol Ultra: the most architecturally similar competitor to Claude's dynamic workflows. Sol Ultra deploys subagents in parallel for complex tasks, which is why it scores higher than plain Sol on TerminalBench 2.1 (91.9% vs 88.8%). The mechanism is comparable; independent verification of real-world reliability is not yet available since the model remains preview-only.
- Kimi K2.7: Agent Swarm coordinates up to 300 sub-agents across 4,000 steps, the largest swarm scale of any model in this comparison. It beats Claude Opus 4.8 on MCP Mark Verified specifically (81.1 vs 76.4), meaning when a tool call needs to be invoked correctly through MCP, K2.7 gets it right more often. The Kimi Claw 24/7 Bench, which measures sustained agentic performance over very long sessions, places K2.7 at 46.9, trailing GPT-5.5 (52.8) and Opus 4.8 (50.4) but improving meaningfully over K2.6's 42.9.
The honest read on agent tasks: Claude Opus 4.8 and GPT-5.6 Sol Ultra both bet on subagent parallelism for hard, high-stakes long-horizon work. GLM-5.2 bets on a tight autonomous iteration loop for sustained single-thread tasks. Kimi K2.7 bets on swarm scale and MCP tool-call correctness for breadth-heavy agentic pipelines. None of these approaches is universally superior; they solve different problems. For a deeper look at how Kimi's swarm architecture specifically compares against GLM's iteration-loop approach, the Kimi K2.7 Code review covers the architectural tradeoffs in detail.
6. Context Window
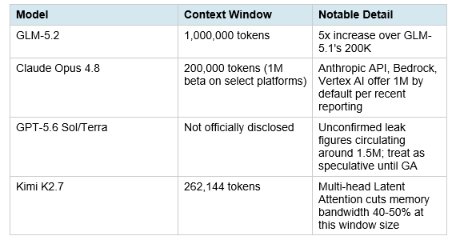
GLM-5.2's jump to 1 million tokens is the single largest context-window leap in this comparison, and it is the feature most directly built for the use case of ingesting an entire codebase, a full monorepo, or a large document set in a single pass without chunking. For repository-scale code review, full-codebase refactor planning, or large legal and compliance document analysis, this is the deciding factor independent of raw coding benchmark scores.
7. Price: Full Cost Breakdown
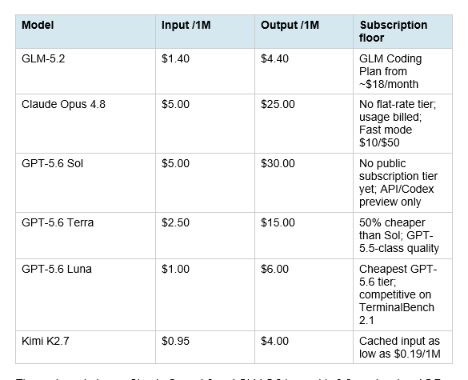
The cost gap between Claude Opus 4.8 and GLM-5.2 is roughly 3.6x on input and 5.7x on output. Against GPT-5.6 Sol the gap is similarly wide. Kimi K2.7 undercuts GLM-5.2 slightly on raw per-token pricing but loses on coding benchmark ceiling and context window size. For a team running thousands of agentic coding sessions per month, the difference between $5.00/$25.00 and $1.40/$4.40 per million tokens compounds into a real budget line item, not a rounding error. The best AI for coding 2026 comparison has the full cost-per-task math worked out across realistic agentic workflows if you want to model your own usage pattern before committing to a vendor.
8. UI Generation: Frontend and Design-to-Code
This is the dimension where the gap between Claude and the open-weight Chinese models has been most persistent, and GLM-5.2 has not fully closed it yet, though it has narrowed it meaningfully.
Independent frontend-specific testing has consistently found that Claude Sonnet 4.6 and the Opus family produce the cleanest component code with the least post-generation cleanup, with notably better Tailwind CSS output and more idiomatic React patterns than the open-weight alternatives. GLM-5 previously held the highest Intelligence Index score among open-weight models for systems-level and agentic tasks but was rated less fine-tuned for frontend aesthetics specifically than Kimi 2.5 in head-to-head UI testing. On the LMArena Code Arena: Frontend leaderboard, GLM-5.2 (Max) now ranks #2 overall, behind only Fable 5 and a full 29 points ahead of Claude Opus 4.7 (Thinking), a meaningful jump from where GLM-5.1 sat in this same leaderboard category.
Kimi's native multimodal architecture remains its specific differentiator for UI work: it can take a Figma export or a hand-drawn wireframe screenshot and generate working component code directly, a capability that is not as cleanly available in GLM-5.2's text-first design. For pure visual-to-code conversion specifically, Kimi retains an edge over GLM-5.2 despite GLM-5.2's stronger general coding scores.
The practical guidance: if your primary workload is backend logic, API design, infrastructure code, or systems-level engineering, GLM-5.2's benchmark profile makes it the strongest open-weight choice by a clear margin. If your primary workload is frontend component generation, design-system-aware UI work, or visual-to-code conversion, Claude's family still holds the cleanest output, with Kimi K2.7's multimodal input as the strongest open-weight alternative specifically for screenshot-driven workflows.
9. Best for Startups
For a startup choosing one model to build around, the decision tree comes down to three questions: how much does cost matter relative to absolute capability, do you need self-hosting or data sovereignty, and how mission-critical is the hardest 10% of your coding tasks.
- Choose GLM-5.2 if: you want the strongest open-weight coding model available, need MIT-licensed self-hosting flexibility for compliance or cost reasons, and can tolerate being roughly seven SWE-bench Pro points behind the absolute closed-source ceiling. At $1.40/$4.40 per million tokens with a $18/month flat-rate coding plan option, this is the strongest cost-to-capability ratio in the entire comparison for teams comfortable with a Chinese-developed model.
- Choose Kimi K2.7 if: your workload is tool-call-heavy agentic pipelines rather than raw code generation, and the absolute lowest per-token cost matters more than topping the coding leaderboard. The MCP Mark Verified lead over Claude Opus 4.8 is a genuinely differentiated capability for agent-framework-heavy startups.
- Choose Claude Opus 4.8 if: you are pre-revenue or early-revenue but the cost of a bad merge or a missed bug is higher than the cost of the API bill. Legal tech, fintech, healthtech, and any startup where a coding mistake has compounding downstream cost should weight correctness over price.
- Choose GPT-5.6 Terra (once GA) if: you want GPT-5.5-class quality at half the previous price point, and you are already inside the OpenAI ecosystem for other tooling. Terra is explicitly positioned by OpenAI as the production-default tier, which is the right framing for most startup workloads once it reaches general availability.
Geopolitical and compliance consideration that matters for fundraising and enterprise sales: GLM-5.2 and Kimi K2.7 both route hosted API traffic through Chinese infrastructure, and both companies appear in ongoing US regulatory scrutiny of PRC-origin AI models in critical infrastructure (alongside DeepSeek and MiniMax, per a May 2026 US House inquiry). Self-hosting GLM-5.2's open weights avoids this entirely since the model never leaves your own infrastructure. If you plan to use the hosted Z.ai or Moonshot APIs directly rather than self-hosting, factor this into any enterprise procurement or compliance conversation early, not after a deal is in motion. For the broader context on this risk profile, the Open-Source LLMs collection on Build Fast with AI tracks every major Chinese and Western open-weight release with the same compliance lens applied consistently.
10. Verdict
There is no universal winner in this comparison, and any blog post that tells you otherwise is selling you something. Here is the honest allocation based on everything above. For raw coding ceiling on the hardest, highest-stakes tasks: Claude Opus 4.8. The seven-point SWE-bench Pro lead over GLM-5.2 and the honesty improvements that reduce silent failures are worth the 3 to 6x price premium when correctness genuinely matters more than cost. For the best open-weight model available today: GLM-5.2, without much debate. It is the first open model to make the conversation about closing the gap to frontier closed models a real conversation rather than an aspirational one, at a price point that changes the calculus for any cost-conscious or self-hosting team. For agentic tool-use and swarm-scale pipelines: Kimi K2.7, specifically because of the MCP Mark Verified lead and the lowest cost per token of any model in this comparison that is still genuinely competitive on coding benchmarks. For teams that want to bet on the newest, least-proven but most aggressively priced family: GPT-5.6, once Terra and Sol reach general availability and independent benchmarks confirm the vendor-reported numbers. The pricing structure alone (Sol at GPT-5.5 price with better benchmarks, Terra at half price with equivalent quality) is the most aggressive multi-tier pricing move any lab has made this year.
The single most important takeaway from this entire comparison: the gap between the best open-weight model and the best closed-source model is now measured in single-digit benchmark points, not generations. Six months ago this would have been an unthinkable sentence to write. GLM-5.2 is the proof. For builders ready to put these models into production, the Agentic AI Launchpad 2026 course covers model-agnostic agent architecture, multi-model routing strategies, and how to build evaluation pipelines that test your real workloads rather than relying on published benchmarks alone.
Frequently Asked Questions
What is GLM-5.2 and how does it compare to closed-source models?
GLM-5.2 is Z.ai's (formerly Zhipu AI) open-weight flagship coding model, released June 13, 2026, with 753 billion total parameters (Mixture-of-Experts, approximately 40 billion active per token), a 1 million token context window, and MIT-licensed weights. It scores 62.1% on SWE-bench Pro and 81.0% on Terminal-Bench 2.1, putting it within four points of Claude Opus 4.8 on the latter benchmark and ahead of GPT-5.5 on both. It is the strongest open-weight coding model available as of its release, confirmed by independent analysis house Artificial Analysis.
Is GLM-5.2 better than Claude Opus 4.8 for coding?
On the hardest benchmark (SWE-bench Pro), Claude Opus 4.8 leads at 69.2% versus GLM-5.2's 62.1%, a seven-point gap. On Terminal-Bench 2.1, the gap narrows to four points (85.0% vs 81.0%). On long-horizon task completion (FrontierSWE), GLM-5.2 nearly ties Opus 4.8 (74.4% vs 75.1%). Claude Opus 4.8 remains the stronger model for the hardest, highest-stakes coding tasks. GLM-5.2 is the better choice when cost, self-hosting, or MIT licensing flexibility matter more than closing the final seven points of capability.
How does GLM-5.2 compare to GPT-5.6 Sol and Terra?
GLM-5.2 beats GPT-5.5 decisively on SWE-bench Pro (62.1% vs 58.6%). GPT-5.6 Sol's vendor-reported benchmarks (88.8% to 91.9% on TerminalBench 2.1 with Sol Ultra) would put it ahead of GLM-5.2 if independently confirmed, but GPT-5.6 remains in limited preview to roughly 20 partner organizations as of this writing, so no independent verification exists yet. On price, GLM-5.2 at $1.40/$4.40 per million tokens is meaningfully cheaper than GPT-5.6 Sol at $5.00/$30.00, though Terra at $2.50/$15.00 narrows that gap considerably.
Which is cheaper: GLM-5.2 or Kimi K2.7?
Kimi K2.7 is slightly cheaper on raw per-token pricing at approximately $0.95 input and $4.00 output per million tokens, versus GLM-5.2's $1.40 input and $4.40 output. Kimi K2.7 also offers cached input pricing as low as $0.19 per million tokens for repeated context. GLM-5.2 offers a flat-rate GLM Coding Plan starting around $18 per month as an alternative to metered API pricing. For pure per-token cost, Kimi K2.7 wins narrowly; for coding benchmark ceiling and context window size, GLM-5.2 leads by a clear margin.
What is the best AI model for startups on a budget?
GLM-5.2 offers the strongest cost-to-capability ratio for budget-conscious startups: MIT-licensed self-hosting eliminates per-token costs entirely for teams with their own GPU infrastructure, and the hosted API at $1.40/$4.40 per million tokens with a $18/month flat-rate plan undercuts every closed-source competitor significantly. Kimi K2.7 is the next-best option specifically for tool-call-heavy agentic pipelines where its MCP Mark Verified lead and slightly lower per-token cost matter more than topping coding benchmarks.
Does GLM-5.2 support UI and frontend code generation?
Yes, and it has improved meaningfully over GLM-5.1: GLM-5.2 (Max) now ranks #2 on the LMArena Code Arena Frontend leaderboard, behind only Claude Fable 5 and ahead of Claude Opus 4.7 by 29 points. However, independent testing still finds Claude's Sonnet and Opus family produces cleaner component code with better Tailwind CSS and React idiom adherence for pure frontend work. Kimi K2.7's native multimodal input gives it a specific edge for screenshot-to-code and Figma-to-code workflows that GLM-5.2 does not directly match.
What is GLM-5.2's context window and how does it compare?
GLM-5.2 supports a 1,000,000 token context window, a 5x increase over GLM-5.1's 200,000 tokens. This is the largest confirmed context window in this comparison: it exceeds Claude Opus 4.8's standard 200,000 tokens (1M is available in beta on select platforms) and Kimi K2.7's 262,144 tokens. GPT-5.6's context window has not been officially disclosed as of the limited preview stage.
Is GLM-5.2 safe to use for sensitive or proprietary code?
Self-hosting GLM-5.2's open weights keeps all code on your own infrastructure with no data leaving your environment, which is the safest option for sensitive or proprietary code. Using the hosted Z.ai API routes data through Chinese infrastructure, and Z.ai (along with Kimi developer Moonshot AI) has appeared in ongoing US regulatory scrutiny of PRC-origin AI models in critical infrastructure as of May 2026. For sensitive, regulated, or government work, self-hosting GLM-5.2 or using a Western-hosted alternative like Claude Opus 4.8 is the more conservative choice.
Recommended Blogs
- Open-Source LLMs Collection: Every Major Open-Weight Release Tracked
- GLM-5.1: #1 Open Source AI Model? Full Review (2026)
- Qwen 3.6 Plus vs GLM-5.1 vs Kimi 2.5: Best Chinese AI for Coding 2026
- Kimi K2.7 Code Review 2026: 1T Coding Model Tested
- GPT-5.6 Review: Sol, Terra, Luna Features, Benchmarks, and Pricing
- Best AI for Coding 2026: Nemotron, GPT Codex, and Claude Compared
Resources & Community
Join our community of 70,000+ AI enthusiasts and learn to build powerful AI applications! Whether you're a beginner or an experienced developer, Build Fast with AI helps you understand and implement AI in your projects.
- Website: buildfastwithai.com
- LinkedIn: Build Fast with AI
- Instagram: @buildfastwithai
- Founder Twitter: @satvikps
- Twitter: @BuildFastWithAI
Agentic AI Launchpad 2026
A structured 6-week cohort program that takes you from AI basics to building and deploying real-world agentic AI systems. Includes live sessions, expert mentorship, project reviews, and a builder community network.
Ready to go from learning to building? Join the next cohort: Agentic AI Launchpad 2026
Free AI Resources
Access free tools, workshops, and micro-learning to keep building:
- AI Workshops: Free resources, upcoming events and past recordings
- Unrot: Learn AI in 5 minutes a day (free micro-learning app)
The open-source coding model race is moving faster than any other category in AI right now. Follow @BuildFastWithAI on X to stay ahead of every benchmark drop, pricing change, and model release that matters for your stack.
References
- VentureBeat: Z.ai's Open-Weights GLM-5.2 Beats GPT-5.5
- TrendingTopics: GLM-5.2: China's Zhipu AI Beats Even Google's Top Models
- Avenchat: GLM 5.2 Review: Benchmarks, Coding Performance
- Groundy: GLM-5.2 Benchmarks: What 62.1% SWE-bench Pro and 99.2%
- TechTimes: GLM-5.2 Open Weights Live: Top Coding Benchmark
- The AI Rankings: GLM-5.2: Benchmarks, Pricing and Review
- Tosea.ai: How to Use GLM-5.2: Complete Guide to Zhipu AI's
- Vellum: Claude Opus 4.8 Benchmarks Explained
- Anthropic: Claude Opus 4.8 Official Product Page
- DataCamp: Claude Opus 4.8: Anthropic's More Honest Flagship Model
- OpenAI: Previewing GPT-5.6 Sol
- MarkTechPost: Moonshot AI Releases Kimi K2.7-Code, Reporting +21.8%
- Flowtivity: Kimi K2.7 Review: Benchmarks, Coding, and Local Performance Tested
- Atlas Cloud: Kimi K2.6 vs GLM 5.1 vs Qwen 3.6 Plus vs MiniMax M2.7

