




GPT-5.6 Review: Sol, Terra, and Luna Explained (OpenAI June 2026)
On June 26, 2026, OpenAI announced its most significant model release since GPT-5.5: not one model, but a family of three, each aimed at a different point on the cost-capability curve. GPT-5.6 Sol is the flagship, described by OpenAI as a step function improvement over GPT-5.5 for frontier agentic work in coding, biology, and cybersecurity. Sol Ultra, a compute-intensive high-effort variant, scores 91.9% on TerminalBench 2.1, ahead of Claude Mythos 5 at 84.3% and Fable 5 at 83.4%. On ExploitBench, Sol matches Mythos Preview using only a third of the output tokens. GPT-5.6 Terra matches GPT-5.5 quality at half the price. GPT-5.6 Luna is the fastest and cheapest tier, strong enough that it ties Claude Mythos 5 at 84.3% on TerminalBench 2.1 at just $1 per million input tokens. The catch: at the U.S. government's request, GPT-5.6 launched as a limited preview to approximately 20 trusted partner organizations through the API and Codex. General availability for ChatGPT users and API developers is promised in the coming weeks, making this the first OpenAI model launch where government coordination directly shaped the rollout timeline. This review covers every announced detail: the tier system, the naming logic, the benchmark performance, the new reasoning modes, the pricing, the safety model, and what teams should do before and after public launch.
1. The New Naming System: What Sol, Terra, and Luna Mean
GPT-5.6 introduces a naming convention that OpenAI plans to carry forward as a permanent architecture for the model family. The generation number (5.6) identifies which training generation and capability baseline the models come from. The tier name (Sol, Terra, or Luna) identifies the capability class and will advance on its own cadence independently of the generation number. OpenAI's framing: the Sun (Sol) is the most powerful, Earth (Terra) is balanced and habitable for everyday work, and the Moon (Luna) is the fastest and lightest. The practical implication for developers: you choose a tier name for a job category and a generation number for the training epoch. When GPT-5.7 arrives, Sol 5.7 will be the new flagship, but Terra 5.6 may still be the right choice for many production workloads if the cost-quality fit is better.
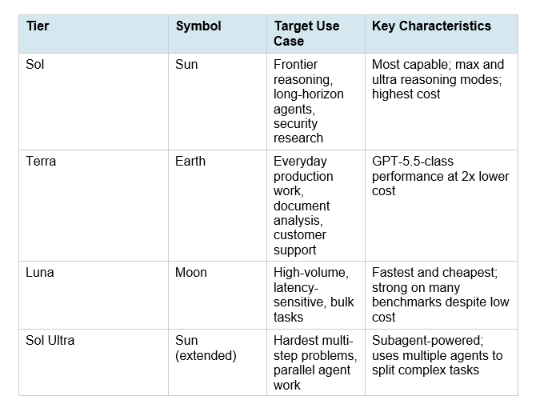
Hot take: this tier architecture is the most important structural change in OpenAI's product lineup since GPT-4. Having three durable capability lanes that advance independently solves the problem of model proliferation where every release generates confusing mini, nano, turbo, and pro variants. Developer workflows can now map jobs to tiers rather than betting on the latest model version. Sol for hard agents. Terra for production defaults. Luna for volume. That routing logic survives the next five releases.
2. GPT-5.6 Sol: Flagship Capabilities and Benchmarks
Sol is OpenAI's most capable model to date, designed for the hardest problems: long-horizon agentic coding, advanced security research, and frontier scientific reasoning. OpenAI describes it as a step function improvement over GPT-5.5, not an incremental polish. The three capability areas OpenAI emphasizes most in the Sol announcement are coding, cybersecurity, and biology. In each area, Sol does not just score higher than GPT-5.5. It does so while using fewer output tokens, which means it is both more capable and more cost-efficient on the tasks it was specifically designed for. The efficiency claim matters more than the benchmark number. A model that achieves the same result with one-third the output tokens has a fundamentally different total cost of ownership in production agentic workflows where output token consumption drives the majority of the API bill.
Sol launches at the same pricing as GPT-5.5: $5 per million input tokens and $30 per million output tokens. The fact that OpenAI did not raise the price on the flagship is itself a strategic signal. As the ExplainX analysis put it: "Sol at GPT-5.5 list price is notable: flagship upgrade without a headline price hike on the top tier." That pricing is pressure on Anthropic's Claude Fable 5, which lists at $10 per million input and $50 per million output.
3. Sol Ultra: The Subagent Mode Explained
Sol Ultra is not a separate model. It is a compute-intensive high-effort reasoning mode of Sol that deploys multiple subagents in parallel to split complex work across tasks. OpenAI describes it as going beyond the capabilities of a single agent by leveraging subagents to accelerate complex work.
The practical architecture: when Sol Ultra handles a request, it does not process it in a single linear reasoning pass. It decomposes the problem into parallel workstreams, delegates each to a subagent, monitors their outputs, and synthesizes the results into a final answer. For long-horizon coding tasks that span multiple files, multiple tests, and multiple reasoning steps, this subagent decomposition is why Sol Ultra scores higher than plain Sol on TerminalBench 2.1 (91.9% vs 88.8%).
Sol also introduces two new reasoning effort levels in addition to Ultra. The max reasoning effort setting gives Sol the most time to reason deeply before producing an output, useful for single-thread hard problems. Ultra mode activates the subagent architecture for problems that benefit from parallelism. For developers building autonomous coding agents, the orchestration patterns covered in the gen-ai-experiments multi-agent workflow notebooks apply directly to how Sol Ultra's subagent decomposition works, and the notebooks have working implementations of agent routing, verification gates, and cost control that carry over from GPT-5.5 agent architectures.
4. GPT-5.6 Terra: GPT-5.5 Quality at Half the Price
Terra is the everyday production model in the GPT-5.6 family. OpenAI's positioning is explicit: Terra has competitive performance to GPT-5.5 while being 2x cheaper. For teams currently running GPT-5.5 for standard production workloads, document analysis, customer support automation, internal tools, and similar tasks, Terra is the migration path.
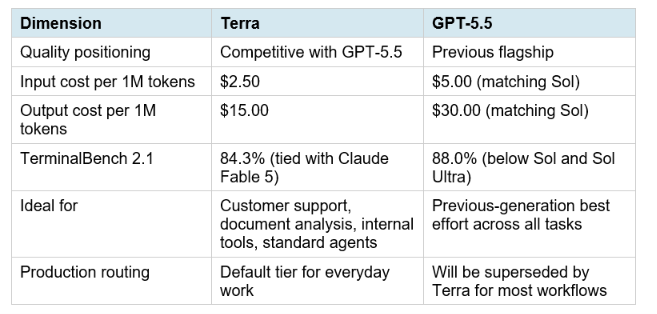
Terra's 84.3% TerminalBench score, tying Claude Fable 5, at half the GPT-5.5 price is the most practically significant number in this launch for most API developers. It means the economic case for staying on GPT-5.5 for production work evaporates at Terra general availability. For teams currently paying $5 per million input tokens for GPT-5.5, Terra at $2.50 input with equivalent performance is a direct cost reduction requiring no quality tradeoff. For developers building on top of OpenAI's stack, the GPT and OpenAI Ecosystem collection on Build Fast with AI covers every OpenAI model update, pricing change, and API feature as it ships.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. GPT-5.6 Luna: The Volume Tier
Luna is described as fast and affordable, designed for high-volume, latency-sensitive, and budget-conscious workloads. At $1 per million input tokens and $6 per million output tokens, it is OpenAI's cheapest model in the 5.6 family.
The benchmark result that makes Luna interesting is not its cost. It is that Luna scores 84.3% on TerminalBench 2.1, tying Claude Mythos 5 and Claude Fable 5 on that specific benchmark at a fraction of their price. This is unusual. A budget-tier model in a new family typically underperforms the previous flagship across most benchmarks. Luna's 84.3% TerminalBench score means it is not a stripped-down model. It is a speed-optimized model that happens to achieve competitive performance on the benchmark that most directly measures agentic coding capability.
For production teams running large agent fleets where per-task cost dominates the economics, Luna at $1 per million input and $6 per million output competes directly with Claude Haiku, Gemini 3.5 Flash, and DeepSeek V3.5 as the volume tier. Once Luna is generally available, that comparison will be the primary evaluation benchmark for high-volume AI infrastructure teams.
6. Coding Performance: TerminalBench 2.1 Results
TerminalBench 2.1 is OpenAI's primary coding benchmark for this release. It evaluates complex command-line workflows requiring planning, iteration, and tool coordination in scientific computing terminal environments. It is a harder version of the original Terminal-Bench that GPT-5.5 topped at 88.0%.
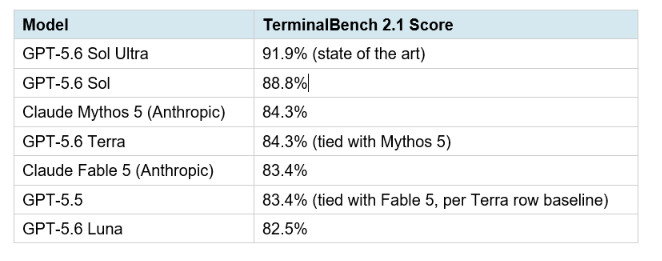
The headline reads: Sol Ultra is now the top-scoring model on TerminalBench 2.1. But the number that matters most for enterprise buyers is Luna at 82.5%, ahead of Claude Opus 4.8 at 78.9% and Gemini 3.1 Pro at 70.7%, at $1 per million input tokens. If that benchmark performance holds under independent testing, Luna becomes the default choice for any cost-sensitive agent pipeline that currently runs on Opus 4.8 or Gemini Pro.
Important caveat: all benchmark figures above are from OpenAI's own preview announcement on June 26, 2026. No independent third-party verification of GPT-5.6 benchmarks exists yet, because the model is not publicly accessible. The numbers are plausible given the progression from GPT-5.5 and consistent with multiple sources reporting the same figures, but they should be treated as vendor-stated until independently verified at general availability. For developers wanting to benchmark these models against their own real-world tasks when access opens, the Best AI Models and Leaderboards collection tracks independent benchmark results and leaderboard updates as they publish.
7. Cybersecurity Capabilities: ExploitBench and Safeguards
Cybersecurity is the dimension of this launch that attracted the most regulatory attention, and for understandable reasons. GPT-5.6 Sol is described by OpenAI as its most capable model yet for cybersecurity, specifically for long-horizon security tasks including vulnerability research and exploitation analysis.
The two cybersecurity benchmarks cited:
- ExploitBench: GPT-5.6 Sol is competitive with Anthropic's Mythos Preview on this benchmark while using only approximately one-third of the output tokens. This is the efficiency claim OpenAI uses to argue Sol is a materially better value than Mythos for security research workflows, not merely equivalent in raw capability.
- ExploitGym (UC Berkeley, in collaboration with OpenAI and other labs): all three GPT-5.6 models show strong improvements in cyber capabilities as reasoning time scales up. This scaling behavior suggests the models' security research capability continues to improve with additional compute, which is relevant for agentic security workflows that run extended reasoning sessions.
OpenAI's stated framing: GPT-5.6 Sol is better at helping people find and fix vulnerabilities than at reliably carrying out end-to-end attacks. Under OpenAI's Preparedness Framework, Sol, Terra, and Luna are all rated High capability in cybersecurity, but none cross the Critical threshold. In testing against Chromium and Firefox, Sol identified bugs and exploitation primitives but did not autonomously produce a functional full-chain exploit. The safety stack includes: model-level training to refuse prohibited cyber assistance including jailbreak attempts; real-time cyber and biology misuse classifiers that evaluate output as it is generated and can pause generation for review by a larger reasoning model; account-level review that tracks flagged activity across historical conversations to distinguish persistent malicious behavior from legitimate dual-use security research; and 94.8% recall on biology evaluations and 81.6% recall on cybersecurity evaluations per the system card. For context on how this positions against Anthropic's Daybreak and GPT-5.5-Cyber programs, the GPT-5.5-Cyber and OpenAI Daybreak expansion review on Build Fast with AI covers the cybersecurity capability arc leading into this release.
8. Biology Capabilities: GeneBench v1
Biology is the third primary capability domain highlighted in the GPT-5.6 announcement. On GeneBench v1, which evaluates long-horizon genomics and quantitative-biology analyses, Sol achieves stronger results than GPT-5.5 while using fewer tokens.
The system card reports 68.4% on the Human Pathogen Capabilities test (SecureBio), approximately nine points above GPT-5.5. This score is what the system card notes as being above the 80th-percentile expert performance threshold of 36.4%, at 48.0% for the protocol benchmarking component. The biology gains are specifically what the system card flags as drawing regulatory attention alongside the cybersecurity scores.
OpenAI's framing of the biology capabilities is careful: GeneBench evaluates whether AI can assist with legitimate genomics research, including tasks like predicting whether an AAV capsid variant will package successfully, which reduces trial-and-error in viral-vector engineering. These are dual-use capabilities: valuable for drug development and gene therapy research, but relevant to biosecurity risk assessment as well. The layered safety stack applies to biology outputs using the same classifier architecture as cybersecurity, with 94.8% monitored recall on biology evaluation sets.
9. Pricing: Full Breakdown Across All Three Tiers
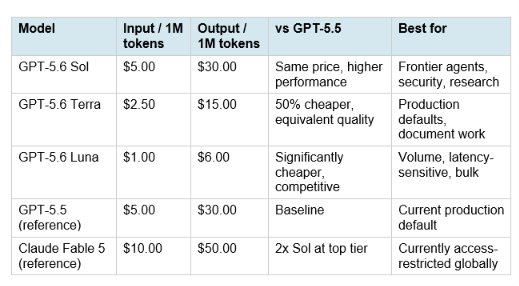
The pricing architecture applies deliberate competitive pressure. Sol at the same price as GPT-5.5 and twice as cheap as Fable 5 positions OpenAI's flagship against Anthropic's at half the cost. Terra at $2.50 input is pressure on Google's Gemini Pro pricing tier. Luna at $1 input competes with Haiku, Gemini Flash, and DeepSeek V3.5 as the cheapest capable tier in any top-tier model family. This is not incremental pricing evolution. It is a coordinated multi-tier price move that changes the value calculation at every point on the cost curve simultaneousl
10. The New Caching System and Cerebras Partnership
GPT-5.6 introduces meaningful changes to prompt caching that directly affect the total cost of production agentic workflows. Three changes in the new caching architecture: first, explicit cache breakpoints let developers control exactly where the cache boundary sits within a prompt, enabling predictable reuse of system prompts and codebase context across many turns. Second, a 30-minute minimum cache life ensures caches persist long enough to plan around in production, eliminating the uncertainty in earlier caching behavior where cache hits were unpredictable. Third, the pricing model for caching changes: cache writes are billed at 1.25x the model's uncached input rate, while cache reads continue to receive the 90% cached-input discount. For agent workflows that reuse large system prompts and codebase context across many turns, these caching changes can reduce effective input-token cost by 90% or more on cached content.
The Cerebras partnership is a separate infrastructure announcement: OpenAI is launching GPT-5.6 Sol on Cerebras at up to 750 tokens per second in July 2026, initially for select customers as capacity expands. 750 tokens per second is approximately 10 to 15 times faster than typical public API speeds for frontier models, which changes the user experience for interactive agents. The latency gap between AI response time and human reading speed narrows at 750 tps, enabling interactive agentic workflows that feel genuinely real-time rather than requiring the user to wait for generation. For developers building production AI pipelines on top of the OpenAI stack, the AI Automation and No-Code collection covers how to integrate OpenAI model updates into n8n and Make.com workflows as new tiers and pricing become available.
11. GPT-5.6 vs Claude Fable 5, Mythos 5, and Gemini 3.5 Pro
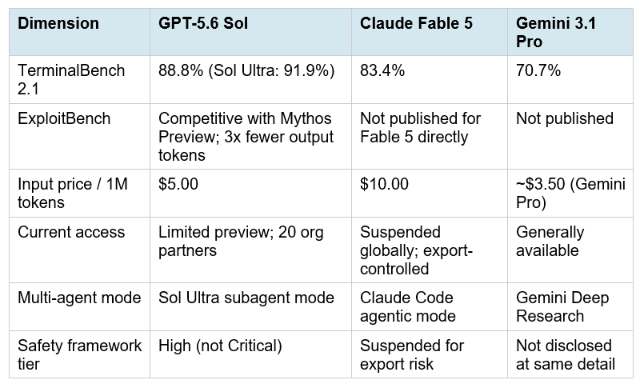
The honest framing: GPT-5.6 Sol leads the coding benchmark leaderboard on TerminalBench 2.1 and the cybersecurity efficiency benchmark on ExploitBench as of the preview announcement. Claude Fable 5 is not currently publicly accessible due to export controls, so real-world head-to-head comparison is impossible until Fable is restored. Gemini 3.1 Pro is significantly cheaper than Fable 5 but substantially behind on TerminalBench 2.1 at 70.7%. The practical situation in late June 2026 is that GPT-5.6 is the only generally pending release in the frontier tier that is moving toward broad access, while Anthropic's most capable models remain access-restricted.
12. The Government-Gated Rollout Explained
The most unusual aspect of the GPT-5.6 launch is not the model itself. It is the rollout structure. At the U.S. government's request, OpenAI is releasing GPT-5.6 as a limited preview to approximately 20 trusted partner organizations whose participation has been shared with and approved by the government, before moving to broader availability. OpenAI previewed the capabilities of GPT-5.6 Sol, Terra, and Luna to the White House and relevant federal agencies for approximately a month before launch, including in meetings CEO Sam Altman had with the White House in early June 2026. The government requested a staggered rollout for additional evaluation before broader access. OpenAI's response was compliance combined with explicit public disagreement: the company published a blog post stating, "We don't believe this kind of government access process should become the long-term default. It keeps the best tools from users, developers, enterprises, cyber defenders, and global partners who need them."
The context: this follows a similar pattern with Anthropic's Fable 5 and Mythos 5, which were placed under national-security export controls on June 12, 2026. The GPT-5.6 situation differs in one important way: Anthropic's models were restricted after launch, while OpenAI coordinated the restriction into the launch design before release. That distinction is significant for how the government-AI industry relationship evolves. OpenAI says it is working with the Administration to develop a Cyber Executive Order framework and a repeatable process for future model releases. The implication is that the ad-hoc preview coordination is a temporary arrangement while that formal framework is built. For enterprise teams evaluating GPT-5.6, the key question is not when the 20-partner window ends, but what the standard process looks like for future frontier models once the framework is established. This is the new normal for frontier AI releases from U.S. labs.
13. Who Should Care About GPT-5.6 and When
Now (during limited preview)
- Security researchers and vetted organizations: if your organization is among the 20 preview partners, begin evaluating Sol on your real security research workflows, not just benchmarks. Measure output token consumption on your actual tasks. The efficiency claim is the real headline.
- All developers: read the system card, understand the tier architecture, and begin planning your routing strategy for when Terra reaches general availability. The Terra migration from GPT-5.5 has a clear economic case that does not require evaluation at launch.
- Cost-sensitive teams currently on GPT-5.5: Terra's 50% price reduction at equivalent performance is the single most actionable planning item from this launch. Model your Terra savings now so you are ready to migrate on day one of general availability.
At General Availability (coming weeks, estimated early to mid July 2026)
- Agentic coding teams: benchmark Sol and Sol Ultra against your current Claude Fable 5 or GPT-5.5 agent deployment. Measure total output token consumption, not just benchmark scores. The efficiency claim across three times fewer tokens on security tasks is where the real cost story is.
- Production API teams: migrate from GPT-5.5 to Terra. Start with low-risk workloads, validate quality parity, then expand. The 50% cost reduction is available without quality sacrifice.
- Volume/infrastructure teams: evaluate Luna against your current Haiku, Gemini Flash, or DeepSeek V3.5 deployment. Luna at $1/$6 with 82.5% TerminalBench competes on different dimensions than a typical cheapest-tier model.
Luna's Cerebras Partnership (July 2026)
When Sol launches on Cerebras at up to 750 tokens per second in July, that speed tier is relevant for interactive agent products where generation latency is a user-experience constraint. Evaluate Cerebras-hosted Sol for interactive coding and agent workflows where the current frontier model latency creates noticeable friction. For builders who want to start building agentic AI systems that take advantage of the new tier architecture, the Agentic AI Launchpad 2026 course covers multi-agent orchestration, tool use, OpenAI API integration, and production deployment patterns across a structured 6-week curriculum.
Frequently Asked Questions
What is GPT-5.6 and what are Sol, Terra, and Luna?
GPT-5.6 is OpenAI's next-generation frontier model family, announced June 26, 2026. It ships as three tiers: Sol (flagship, most capable), Terra (balanced everyday model at half the GPT-5.5 price), and Luna (fastest and cheapest, designed for high-volume work). Sol also has an extended compute mode called Sol Ultra that deploys multiple subagents in parallel for complex tasks. The naming convention uses the generation number (5.6) and a durable tier name (Sol/Terra/Luna) that advances independently.
How does GPT-5.6 Sol compare to Claude Fable 5 and Mythos 5?
On TerminalBench 2.1, GPT-5.6 Sol Ultra scores 91.9%, ahead of Claude Mythos 5 at 84.3% and Fable 5 at 83.4%. On ExploitBench, Sol is competitive with Mythos Preview while using approximately one-third the output tokens. Sol is priced at $5/$30 per million tokens, compared to Fable 5 at $10/$50. Claude Fable 5 is currently suspended globally under export controls and not publicly accessible as of late June 2026. All GPT-5.6 benchmark figures are vendor-stated from the June 26, 2026 preview announcement and have not yet been independently verified.
What is GPT-5.6 Ultra mode and how does it work?
Sol Ultra is a compute-intensive high-effort reasoning mode of GPT-5.6 Sol that goes beyond the capabilities of a single agent by deploying multiple subagents in parallel to split complex work. Rather than processing a request in a single linear reasoning pass, Sol Ultra decomposes the problem, delegates to parallel subagents, monitors their outputs, and synthesizes the results. This is why Sol Ultra scores 91.9% on TerminalBench 2.1 versus Sol's 88.8%. Sol also has a max reasoning effort mode that gives the model more time to reason deeply without activating the full subagent architecture.
What is the GPT-5.6 pricing?
Per million tokens: Sol is $5 input and $30 output (same as GPT-5.5). Terra is $2.50 input and $15 output (50% cheaper than GPT-5.5). Luna is $1 input and $6 output. Sol Ultra is a reasoning mode of Sol rather than a separate pricing tier. Prompt caching reads receive a 90% cached-input discount, with cache writes billed at 1.25x the uncached input rate. A 30-minute minimum cache life is guaranteed for production reliability.
Why is GPT-5.6 only available to 20 organizations at launch?
At the request of the U.S. government, OpenAI started with a limited preview for approximately 20 trusted partner organizations whose participation was shared with and approved by the government. This follows GPT-5.6 capabilities being previewed with White House officials for approximately one month before launch, including meetings CEO Sam Altman had with the White House in early June 2026. OpenAI complied with the request while publicly stating it does not believe this kind of government access process should become the long-term default. General availability for ChatGPT users and API developers is planned for the coming weeks, estimated early to mid July 2026.
When will GPT-5.6 be available in ChatGPT and the public API?
OpenAI has not given a firm date, describing broader access as coming in the coming weeks from the June 26, 2026 preview. Based on the Mythos 5 precedent (approximately 15 days from suspension to partial restoration), the most likely timeline is: early to mid July 2026 for ChatGPT Plus and Pro subscriber access; mid to late July 2026 for full API general availability. Sol Ultra availability to a broad audience may follow. Monitor openai.com/index for official announcements.
Is GPT-5.6 safe? What safeguards does OpenAI use?
OpenAI's safety stack for GPT-5.6 includes: model-level training to refuse prohibited assistance including jailbreak attempts; real-time classifiers for cyber and biology misuse that evaluate output during generation and can pause for review by a larger reasoning model; account-level review that tracks flagged activity across historical conversations; and 94.8% recall on biology evaluations and 81.6% recall on cybersecurity evaluations per the published system card. Under OpenAI's Preparedness Framework, all three tiers are rated High capability in cybersecurity and biology, but none reach the Critical threshold. In testing, Sol identified bugs and exploitation primitives but did not autonomously execute full-chain exploits against hardened targets.
What is the Cerebras partnership with GPT-5.6?
OpenAI is launching GPT-5.6 Sol on Cerebras hardware at up to 750 tokens per second in July 2026, initially for select customers as capacity expands. This is approximately 10 to 15 times faster than typical public API serving speeds for frontier models. The Cerebras deployment targets interactive agent products where generation latency creates user experience friction, enabling genuinely real-time agentic interactions rather than waiting for generation to complete.
Recommended Blogs
- GPT and OpenAI Ecosystem Collection: Every OpenAI Model Release and Feature Update
- GPT-5.5-Cyber and OpenAI Daybreak Expansion Review: Cybersecurity Capabilities
- GPT-5.5 Review: Features, Benchmarks, and Agentic Coding Performance
- Best AI Models and Leaderboards: Cross-Model Rankings July 2026
- Best AI for Coding 2026: GPT Codex, Claude Code, and Gemini Compared
- Agentic AI Launchpad 2026: Build Real AI Systems in 6 Weeks
Resources & Community
Join our community of 70,000+ AI enthusiasts and learn to build powerful AI applications! Whether you're a beginner or an experienced developer, Build Fast with AI helps you understand and implement AI in your projects.
- Website: buildfastwithai.com
- LinkedIn: Build Fast with AI
- Instagram: @buildfastwithai
- Founder Twitter: @satvikps
- Twitter: @BuildFastWithAI
Agentic AI Launchpad 2026
A structured 6-week cohort program that takes you from AI basics to building and deploying real-world agentic AI systems. Includes live sessions, expert mentorship, project reviews, and a builder community network.
Ready to go from learning to building? Join the next cohort: Agentic AI Launchpad 2026
Free AI Resources
Access free tools, workshops, and micro-learning to keep building:
- AI Workshops: Free resources, upcoming events and past recordings
- Unrot: Learn AI in 5 minutes a day (free micro-learning app)
OpenAI is releasing frontier models faster than ever. Follow @BuildFastWithAI on X to stay ahead of every model launch, pricing change, and benchmark update that matters for your work.
References
- OpenAI: Previewing GPT-5.6 Sol (official announcement, June 26, 2026)
- OpenAI: GPT-5.6 Preview System Card (deployment safety hub)
- Axios: OpenAI Releases Powerful New GPT-5.6 Model Under Restrictions (June 26, 2026)
- VentureBeat: OpenAI Unveils GPT-5.6 Sol, Terra and Luna Models (June 26, 2026)
- DataCamp: GPT-5.6 Sol, Terra, and Luna: OpenAI's Next-Gen Model Family
- 9to5Mac: OpenAI Upgrading ChatGPT and Codex with New GPT-5.6 Models in Limited Release
- Thurrott: OpenAI Launches Next-Gen GPT-5.6 Models in Limited Preview
- Lushbinary: GPT-5.6 Sol, Terra and Luna Developer Guide: Benchmarks and Pricing
- ExplainX: GPT-5.6 Sol, Terra, Luna: Preview, Pricing and Benchmarks (2026)
- Codersera: GPT-5.6 Sol, Terra, and Luna Developer Preview Guide (2026)
- Andrew.ooo: What Is GPT-5.6? Sol, Terra, Luna Explained (June 2026)
- Let's Data Science: OpenAI Unveils GPT-5.6 Sol, Terra and Luna (June 28, 2026)

