




On June 22, 2026, OpenAI did something that moves Daybreak from a discovery platform into a remediation platform: they released the full version of GPT-5.5-Cyber, shipped a Codex Security plugin, launched a Cyber Partner Program with over 20 security vendors, and announced Patch the Planet, a program to fix vulnerabilities in critical open-source infrastructure at scale. GPT-5.5-Cyber scores 85.6% on CyberGym, the highest single-model result on that benchmark to date, against 81.8% for the standard GPT-5.5, 79.0% for GPT-5.4, and 73.1% for Claude Opus 4.7. This is not an incremental product update. It is OpenAI's attempt to establish itself as the AI lab that governments and security teams trust with the most sensitive defensive work on the planet. Whether that bet pays off depends on questions the benchmarks alone cannot answer.
1. What Is OpenAI Daybreak?
OpenAI Daybreak is a cybersecurity platform first launched on May 11, 2026, the same day Google's Threat Intelligence Group confirmed the first recorded case of attackers using AI to build a zero-day exploit. The timing was not accidental. The core idea behind Daybreak is that the same AI capabilities now accelerating attacks need to be deployed at scale on the defense side, or the gap between attacker speed and defender speed grows wider every quarter. The June 22, 2026 expansion adds three components: the full GPT-5.5-Cyber model for verified defenders, a Codex Security plugin embedded directly in developer workflows, and Patch the Planet, a structured program to fix vulnerabilities in widely used open-source projects. Sam Altman described the initiative clearly on launch day: "GPT-5.5-Cyber is here. Patch the Planet and Codex Security will help solve security problems instead of just finding them." That shift from finding to fixing is the operative word in this release.
For full background on the broader OpenAI model stack that underpins Daybreak, our GPT-5.5 review with benchmark data and pricing covers the base model's performance profile in detail.
2. What Is GPT-5.5-Cyber? Capabilities and Access Model
GPT-5.5-Cyber is a fine-tuned variant of GPT-5.5, specifically trained for advanced authorized cybersecurity work. It has a lower refusal boundary than the standard model for legitimate security tasks, enabling capabilities that the base model does not expose: binary reverse engineering, deep codebase reachability analysis, exploit path tracing, vulnerability validation, patch development, and evidence preparation for human review. It is not a general-access model. OpenAI has been explicit that GPT-5.5-Cyber is available in limited release to what the company calls verified or trusted defenders, meaning vetted security vendors, government agencies, academic researchers, and enterprise security teams operating under OpenAI's Trusted Access for Cyber program. Individual members accessing GPT-5.5-Cyber are required to enable phishing-resistant authentication. This is OpenAI treating the highest-capability tier less like a consumer product and more like privileged access to critical infrastructure tooling.
What GPT-5.5-Cyber is designed to do, in concrete terms:
- Trace vulnerable code from entry point to root cause across large, complex codebases
- Determine whether a vulnerability is actually reachable and exploitable in a specific deployment context
- Gather and package validation evidence for human security review
- Develop remediation patches for identified vulnerabilities
- Prepare structured reports in formats like SARIF and CodeQL for integration with existing vulnerability management systems
The model is intentionally scoped to authorized defensive work. OpenAI's framing: the refusal boundary is calibrated for defenders whose work requires advanced cyber capabilities paired with verification, monitoring, and scoped controls. If you are not a verified defender, you access security capabilities through the standard GPT-5.5 tier inside Codex Security, which is itself quite powerful but with a higher refusal boundary for dual-use tasks. For context on where this fits in the broader AI coding ecosystem, the best AI for coding 2026 comparison covers GPT-5.5 alongside Claude Opus and NVIDIA Nemotron with independent benchmark data.
3. CyberGym and Benchmark Performance: What the Numbers Actually Mean
CyberGym is an internal OpenAI benchmark that measures whether an AI agent can reproduce known software vulnerabilities in controlled testing environments. It is not the same as finding novel vulnerabilities in production systems, and the distinction matters.
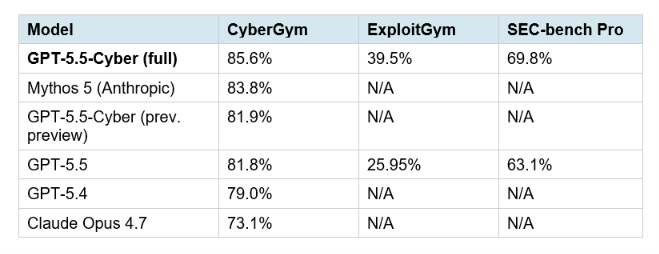
The 3.8-point improvement on CyberGym from the previous GPT-5.5-Cyber preview to the full release is meaningful. On ExploitGym, the improvement is sharper: 39.5% versus 25.95% for GPT-5.5, a 13.5-point gap that reflects meaningfully deeper capability for finding real exploit paths rather than just reproducing known vulnerability patterns.
The caveat worth stating plainly: CyberGym is an internal OpenAI benchmark. It measures whether the model can reproduce known vulnerabilities in test environments, not whether it can find novel zero-days in production systems. The real-world analog comes from Patch the Planet's initial five-day sprint, which surfaced hundreds of real issues across 19 open-source projects. XBOW data published by third-party researchers shows a 4x improvement in vulnerability-finding completeness across two GPT-5.5 model generations, which is the more meaningful metric for practitioners. For those tracking the full AI model leaderboard where these cyber benchmarks now sit alongside coding and reasoning scores, the Best AI Models June 2026 ranked leaderboard has the updated comparison.
Hot take: CyberGym topping is a useful signal, but the Patch the Planet results tell you more. Hundreds of real issues surfaced and dozens of patches merged in a five-day sprint across 19 open-source projects is not a benchmark number. It is a production result. That is what I would weight more heavily when evaluating whether this technology is actually ready for real security wor
4. Codex Security Plugin: From Finding Bugs to Landing Fixes
The Codex Security plugin is the part of this launch that matters most for the largest number of developers. It is not restricted to verified defenders. Any developer using Codex can now scan their codebase, a selected folder, or a specific recent commit, and receive a structured vulnerability report with severity ratings, affected code locations, validation evidence, and remediation guidance. The plugin does not just flag issues. It traces attack paths, builds threat models, validates whether a finding is real and reachable, generates patches, and exports results in SARIF and CodeQL formats compatible with existing vulnerability management pipelines. The numbers since the March research preview are not trivial: over 30 million commits scanned, across more than 30,000 codebases. Human reviewers have manually confirmed more than 70,000 findings as fixed. Over 500,000 findings have been automatically determined to be resolved.
Critically, no code is automatically modified. The plugin proposes patches for human review. Teams can revalidate after merging to confirm the vulnerability is resolved. The human-in-the-loop requirement is deliberate and correct. For security work at this sensitivity level, automated approval would be a serious mistake, and OpenAI appears to understand this.
For developers who want to understand how Codex's agentic architecture works under the hood before adopting Codex Security in production, the gen-ai-experiments multi-agent workflow cookbook has working notebooks on agentic orchestration patterns directly relevant to how Codex Security operates as an autonomous scanning agent.
My view: Codex Security is the most practically significant part of this launch for most development teams. GPT-5.5-Cyber is for specialist security work. Codex Security is for every team that ships software and wants to stop leaving known vulnerabilities in production codebases for months at a time. That is almost every team.
5. Patch the Planet: Open-Source Security at Machine Speed
Patch the Planet is OpenAI's attempt to apply Daybreak's capabilities to the software that underpins global infrastructure: the open-source projects everyone uses but few organizations have the resources to audit properly. OpenAI built Patch the Planet in partnership with Trail of Bits and HackerOne, pairing AI-assisted vulnerability research with human expert review. The workflow covers fuzzing, variant analysis, and differential testing, with every finding reviewed by human experts before patches are proposed to project maintainers. The initial five-day sprint across multiple open-source projects surfaced hundreds of security issues and merged dozens of patches. More than 30 open-source projects have committed to participate, including cURL, Python, Go, Sigstore, and pyca/cryptography. These are not obscure libraries. cURL handles HTTP requests across billions of devices. Python is the runtime for a substantial portion of the world's scientific and financial computing. A vulnerability in pyca/cryptography affects every application using Python's standard cryptographic primitives.
The strategic framing matters here. Patch the Planet is OpenAI positioning itself as infrastructure-grade security for the open-source ecosystem, which is a direct response to Anthropic's Claude Mythos finding and patching 271 vulnerabilities in Firefox as part of Project Glasswing. Both labs have reached the same conclusion: cybersecurity is the use case where frontier AI capability is most immediately valuable and most politically defensible. The lab that governments trust with this work gains a durable advantage in access, influence, and regulatory goodwill that compounds over time.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
6. Daybreak Cyber Partner Program
The Daybreak Cyber Partner Program launched alongside the June 22 expansion with a roster that reads like a map of enterprise security infrastructure. The named partners include Accenture, Akamai, Check Point, Cisco, Cloudflare, CrowdStrike, IBM, and Palo Alto Networks, among others from the original May launch: SentinelOne, Snyk, Semgrep, Rapid7, Qualys, Fortinet, Oracle, Zscaler, Okta, Netskope, and Gen Digital. Each of these partners is building products on top of OpenAI's cyber capabilities to secure their own customers. The framing from Anthony Grieco, Cisco's chief security and trust officer, was both enthusiastic and carefully hedged: 'a powerful force multiplier for defenders,' but 'speed cannot be traded for trust.' That tension between capability and reliability is the right tension to acknowledge. OpenAI has also expanded government partnerships with agencies in the US, Australia, Canada, France, Germany, Japan, South Korea, and EU institutions including ENISA.
Importantly, several of these partner names, including CrowdStrike and Cloudflare, were the same companies whose stocks dropped when Anthropic launched Claude Code Security in February 2026. The fact that they are now Daybreak partners rather than threatened competitors is a significant strategic repositioning. For the bigger picture on how the AI coding and security tool ecosystem is evolving, our Claude AI 2026 complete guide covering Claude Code Security and its impact has the full context.
7. Daybreak vs Anthropic Glasswing: The Honest Comparison
These two programs are the most direct competitive clash in enterprise AI right now. Here is the factual breakdown:
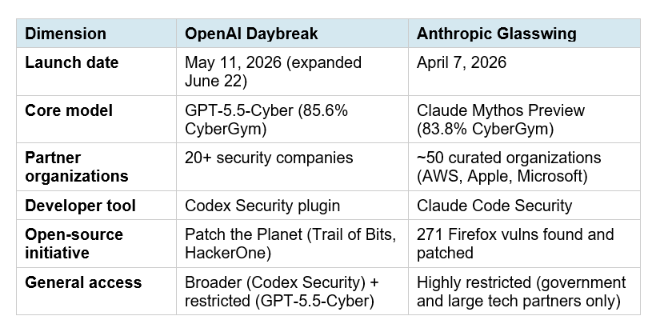
The honest analysis: Glasswing has the stronger raw capability story. Claude Mythos Preview is a model so capable on cybersecurity tasks that it is currently under national-security export controls. Daybreak is the more productized and accessible platform. GPT-5.5-Cyber leads on CyberGym (85.6% vs 83.8%), but Mythos is export-controlled for a reason, and those controls are a data point about capability ceiling, not just a policy decision.
Where Daybreak clearly wins: ecosystem breadth. 20+ security vendor partners, government agency relationships across seven countries, a Codex Security plugin available to all Codex users, and Patch the Planet addressing open-source infrastructure. Anthropic's Glasswing is more curated and restricted. Daybreak is more distributed and accessible. Different strategies. Neither is wrong. The question is which strategy produces better security outcomes in practice.
8. Who Should Care About This Launch?
This is not a launch for everyone, and it is worth being specific about who it actually matters for.
- Security engineers and penetration testers at verified organizations: GPT-5.5-Cyber is directly relevant. Apply to Trusted Access for Cyber through OpenAI's website if your organization qualifies.
- Software development teams shipping production code: Codex Security is relevant now. It is available inside Codex without special access requirements and can scan your existing codebase for known vulnerabilities automatically.
- Open-source project maintainers: Patch the Planet is specifically designed to bring AI-assisted vulnerability discovery to projects that cannot afford dedicated security teams. If you maintain cURL, Python, Go, Sigstore, or similar projects, check the Patch the Planet program page.
- Enterprise security leaders evaluating AI tools: The Daybreak partner program means your existing security vendors (CrowdStrike, Palo Alto, Cisco, Cloudflare) are likely building Daybreak integration into tools you already use.
- Developers building security tooling: The Cyber Partner Program is open for applications. If you are building a security product and want access to GPT-5.5-Cyber capabilities for your platform, this is the relevant entry point.
If you are a developer curious about building AI-assisted security tooling without a Trusted Access for Cyber account, the OpenAI Daybreak cybersecurity platform explained guide covers what the standard GPT-5.5 API exposes for security applications and what requires the higher access tier.
9. Honest Criticisms and Open Questions
Every AI launch deserves scrutiny. Here is what is genuinely unclear or worth pushing back on.
First, CyberGym is an OpenAI benchmark. Every number in that table above was reported by OpenAI. Independent third-party verification on the cyber-specific benchmarks is minimal compared to general coding and reasoning benchmarks. Until independent researchers can reproduce the 85.6% CyberGym score in a neutral environment, treat it as a direction indicator rather than a hard capability floor.
Second, the 30 million commits scanned figure sounds impressive but says nothing about what percentage of real vulnerabilities were found versus missed. False negative rate, not just finding volume, is the relevant metric for security tools. OpenAI has not published miss rate data from Codex Security at scale.
Third, the ExploitGym score of 39.5% deserves attention alongside the CyberGym headline. ExploitGym measures whether the model can find real exploit paths, a harder and more attacker-relevant task. At 39.5%, GPT-5.5-Cyber is meaningfully better than GPT-5.5 at 25.95%, but 39.5% also means the model fails to find working exploits in 60.5% of tested scenarios. For defenders who need comprehensive coverage, that miss rate matters.
Fourth, there is a dual-use tension that OpenAI acknowledges but has not fully resolved. The same capabilities that make GPT-5.5-Cyber useful for defenders also make it potentially useful for attackers who gain unauthorized access to it. The phishing-resistant authentication requirement for individual members is a meaningful control. The deeper question is whether the vetting process for Trusted Access for Cyber is rigorous enough to prevent misuse at scale as access expands over time
Frequently Asked Questions
What is GPT-5.5-Cyber and how is it different from GPT-5.5?
GPT-5.5-Cyber is a fine-tuned variant of GPT-5.5 trained specifically for authorized defensive cybersecurity work. It has a lower refusal threshold for security tasks, enabling binary reverse engineering, deep reachability analysis, exploit path tracing, and evidence preparation. It scores 85.6% on CyberGym versus 81.8% for standard GPT-5.5 and 39.5% on ExploitGym versus 25.95% for GPT-5.5. It is available only to verified defenders through OpenAI's Trusted Access for Cyber program.
What is OpenAI Daybreak?
OpenAI Daybreak is a cybersecurity platform launched May 11, 2026 and expanded June 22, 2026. It combines GPT-5.5-Cyber and the Codex Security plugin to help security teams and developers find, validate, and fix software vulnerabilities. The June 22 expansion added the full GPT-5.5-Cyber model, the Codex Security plugin for all Codex users, the Daybreak Cyber Partner Program with 20+ security vendors, and Patch the Planet for open-source security work.
What is the CyberGym benchmark?
CyberGym is an internal OpenAI benchmark that measures whether an AI agent can reproduce known software vulnerabilities in controlled testing environments. It is used to compare cybersecurity-specific model performance across different GPT versions. GPT-5.5-Cyber scores 85.6%, the current highest published single-model score, ahead of Mythos 5 at 83.8% and standard GPT-5.5 at 81.8%.
What does the Codex Security plugin do?
The Codex Security plugin integrates vulnerability detection directly into Codex workflows. It can scan an entire codebase, a specific folder, or a recent commit. It builds threat models, traces attack paths, determines code reachability, validates findings, generates remediation patches, and exports results in SARIF and CodeQL formats. All patches require human approval before any code change is merged. Since the March research preview, it has scanned over 30 million commits across 30,000+ codebases and confirmed over 70,000 manual fixes.
What is Patch the Planet?
Patch the Planet is OpenAI's initiative to apply AI-assisted vulnerability discovery and patching to critical open-source software. Built with Trail of Bits and HackerOne, it pairs AI scanning with human expert review. More than 30 projects including cURL, Python, Go, Sigstore, and pyca/cryptography have committed to participate. An initial five-day sprint surfaced hundreds of security issues and merged dozens of patches across 19 open-source projects.
How does OpenAI Daybreak compare to Anthropic Glasswing?
Glasswing (launched April 7, 2026) is more restricted, deploying Claude Mythos Preview to roughly 50 curated organizations including AWS, Apple, and Microsoft, and has achieved headline results including 271 Firefox vulnerabilities found and patched. Daybreak is more broadly accessible through its Codex Security plugin and has a larger partner network of 20+ security companies plus government agency relationships across seven countries. Glasswing appears to have stronger raw model capability; Daybreak is the more productized and distributed platform.
Who can access GPT-5.5-Cyber?
GPT-5.5-Cyber is available in limited release to verified defenders through OpenAI's Trusted Access for Cyber program. This includes vetted security vendors, government agencies, enterprise security teams, and academic researchers conducting authorized cybersecurity work. General API or ChatGPT access to GPT-5.5-Cyber is not available. Individual members accessing GPT-5.5-Cyber are required to enable phishing-resistant account security.
Is GPT-5.5-Cyber safe? How does OpenAI prevent misuse?
OpenAI has implemented a tiered access model with phishing-resistant authentication requirements, organizational verification for Trusted Access for Cyber membership, and monitoring and scoped controls on what GPT-5.5-Cyber can be used for. The model is designed specifically for authorized defensive tasks. OpenAI acknowledges the dual-use tension explicitly and has structured access restrictions as a response to it, though independent assessment of how effective these controls are over time is not yet available.
Recommended Blogs
- OpenAI Daybreak: The AI Cybersecurity Platform Explained (May 2026)
- GPT-5.5 Review: Benchmarks, Pricing and vs Claude 2026
- Claude AI 2026: Models, Features, Desktop and More (includes Claude Code Security)
- Best AI Models June 2026: Full Ranked Leaderboard
- Best AI for Coding 2026: Nemotron vs GPT-5.3 vs Opus 4.6
- GPT-5-Codex: OpenAI's Agentic Coding Model for Autonomous Software Development
Resources & Community
Join our community of 70,000+ AI enthusiasts and learn to build powerful AI applications! Whether you're a beginner or an experienced developer, Build Fast with AI helps you understand and implement AI in your projects.
- Website — buildfastwithai.com
- LinkedIn — Build Fast with AI
- Instagram — @buildfastwithai
- Founder Twitter — @satvikps
- Twitter — @BuildFastWithAI
Agentic AI Launchpad 2026
A structured 6-week cohort program that takes you from AI basics to building and deploying real-world agentic AI systems. Includes live sessions, expert mentorship, project reviews, and a builder community network.
Ready to go from learning to building? Join the next cohort → Agentic AI Launchpad 2026
Free AI Resources
Access free tools, workshops, and micro-learning to keep building:
- AI Workshops — Free resources, upcoming events & past recordings
- Unrot — Learn AI in 5 minutes a day (free micro-learning app)
AI cybersecurity is moving faster than most security teams realize. Follow @BuildFastWithAI on X to stay ahead of every launch, benchmark update, and access change that matters.
References
- OpenAI — Daybreak: Securing the World (June 22, 2026)
- Axios — OpenAI Rolls Out More Capable Version of Cyber Model
- MLQ News — OpenAI Launches GPT-5.5-Cyber and Patch the Planet
- Testing Catalog — OpenAI Launches New Security Tools and Updates GPT-5.5-Cyber
- Kingy AI — OpenAI Daybreak Explained: Inside GPT-5.5-Cyber, Codex Security and the New Frontier of AI Cyber Defense
- IT Brief Asia — OpenAI Expands Daybreak with Patching Tools and Partners
- TechTimes — OpenAI Launches Daybreak the Same Day Google Confirmed the First AI-Built Zero-Day Attack
- Investing.com — OpenAI Expands Daybreak with GPT-5.5-Cyber and Codex Security

