




Gemini 3.5 Flash vs GPT-5.5 vs Claude vs DeepSeek: Best AI After Google IO 2026
A Flash-tier model just beat Pro-tier flagships on coding and agentic benchmarks. That is not supposed to happen. Gemini 3.5 Flash launched on May 19, 2026 at Google IO 2026, and within 24 hours the developer community was running it against GPT-5.5, Claude Sonnet 4.6, and DeepSeek V4 to see if the benchmark story held up in real workloads.
This is the comprehensive head-to-head you need to make a production routing decision today. We cover four comparison matchups: Gemini 3.5 Flash vs GPT-5.5, vs Claude Sonnet 4.6, vs Gemini 3.5 Pro (what to expect), and vs DeepSeek V4 on cost. If you want the standalone review of what Gemini 3.5 Flash is before reading the comparisons, start with the full Gemini 3.5 Flash benchmarks, pricing, and API guide — then come back here for the competitor analysis.
1. The Models at a Glance: Who We Are Comparing and Why
Five models are in this comparison. Three are Pro-tier flagships. One is a mid-tier workhorse. One is the model we are benchmarking against all of them. Here is why each one belongs in this analysis
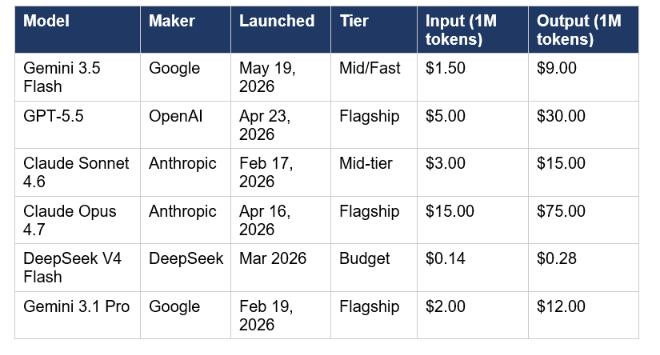
The tier mismatch is real and you should not ignore it. Gemini 3.5 Flash is not a Pro-tier model. Comparing it directly against GPT-5.5 and Opus 4.7 is a tier-mismatched fight where Flash should lose on raw capability. The fact that it wins on several critical benchmarks anyway is precisely what makes this comparison worth writing. For the prior-generation version of this comparison, the Claude Sonnet 4.6 vs GPT-5.5 vs Gemini 3.1 Pro three-way analysis covers what the pre-IO 2026 leaderboard looked like before Gemini 3.5 Flash changed the routing calculus.
2. Master Benchmark Table: All Models, All Key Tests
Every number in this table is sourced from official vendor benchmark pages or Artificial Analysis, BenchLM, or LLM Stats third-party independent evaluations published within 48 hours of Gemini 3.5 Flash's launch on May 19, 2026. Bold marks the field leader per row.
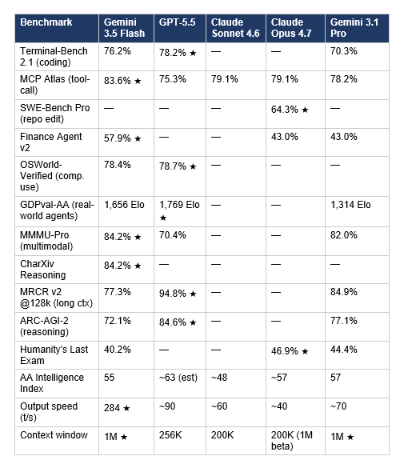
Three patterns jump out. First, GPT-5.5 leads on everything that requires deep reasoning: ARC-AGI-2, long-context retrieval, GDPval-AA Elo. Second, Gemini 3.5 Flash dominates multimodal (MMMU-Pro 84.2%, the highest score recorded according to Artificial Analysis) and MCP-orchestrated tool-use. Third, Claude Opus 4.7 is the only model that leads the hardest software engineering benchmark (SWE-Bench Pro 64.3%). None of these models is a universal winner. The routing question is which one wins on the specific benchmark your production workload resembles. For the full model landscape beyond these five, see the May 2026 AI model leaderboard at Build Fast with AI which covers 20+ models including Grok 4.3, Mistral Large 3, and the DeepSeek V4 family.
3. Gemini 3.5 Flash vs GPT-5.5: Speed, Cost, and Agentic Power
Gemini 3.5 Flash is the stronger model for MCP-orchestrated multi-tool workflows. GPT-5.5 wins on reasoning depth, long-context retrieval, and computer use. Depending on what you build, the right answer could be either model — and the cost math makes that decision consequential.
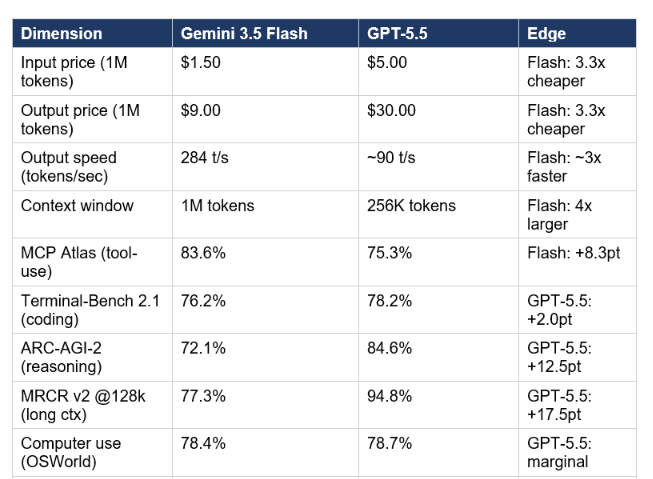
Gemini 3.5 Flash vs GPT-5.5: Speed, Cost, and Agentic Power
The cost math is the headline: GPT-5.5 costs 3.3x more per token on both input and output. At 289 tokens per second, Gemini 3.5 Flash is approximately 3x faster in throughput. For high-volume agentic pipelines where you run thousands of tool-call loops daily, this is not a minor optimization. In Antigravity 2.0, Google ran 93 parallel subagents processing 15,000+ requests in 12 hours for under $1,000. The same workload on GPT-5.5 at 3.3x cost would run over $3,300.
My routing decision: pick GPT-5.5 when the task involves reasoning over long documents (MRCR v2 at 128k is a 17.5-point gap that is not noise), complex multi-hop reasoning (ARC-AGI-2 +12.5pt), or requires airtight computer use. Pick Gemini 3.5 Flash when you are running MCP-orchestrated tool chains at volume, need multimodal grounding, or are cost-constrained on output tokens. This is not a close call on MCP Atlas — 8.3 points at scale is meaningful.
Hot take: GPT-5.5's ARC-AGI-2 score of 84.6% versus Flash's 72.1% is the benchmark that matters least for most production systems. The gap on MCP Atlas matters more for anyone building agents. Benchmarks that test synthetic reasoning problems systematically overweight the flagship advantage on real engineering workloads.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
4. Gemini 3.5 Flash vs Claude Sonnet 4.6: Best Coding AI?
Gemini 3.5 Flash beats Claude Sonnet 4.6 on 5 of the 7 shared benchmarks and costs 2x less on input. Claude Sonnet 4.6 holds the edge on production software engineering tasks where code correctness is non-negotiable and on GPQA-style reasoning.
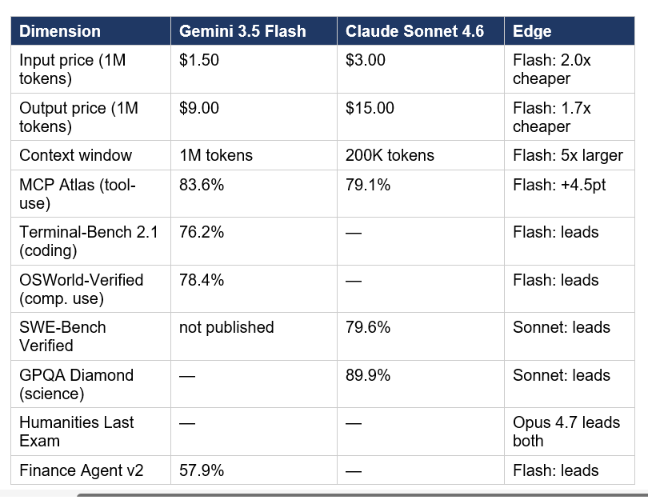
The coding comparison is the most nuanced in this entire article. On agentic benchmarks (MCP Atlas, Terminal-Bench 2.1), Gemini 3.5 Flash leads. On production software engineering benchmarks where the model edits real repositories (SWE-Bench Verified 79.6%), Claude Sonnet 4.6 holds an advantage. Why does Sonnet 4.6 not publish a Terminal-Bench 2.1 or Finance Agent v2 number? Because those benchmarks measure MCP tool-call loops, and Anthropic has been benchmarking Sonnet 4.6 on its own SWE-Bench-adjacent evals that emphasize code correctness over orchestration efficiency. The two models are optimized for different definitions of "coding." Flash is faster and cheaper at coordinating multi-step tool chains. Sonnet 4.6 is more reliable at editing production codebases and is the default model in Claude Code for that reason. If you are running agentic loops at scale, Flash wins on economics. If your AI is reviewing a PR that goes into a production repo, Sonnet 4.6's 79.6% SWE-Bench Verified score matters more than Flash's MCP Atlas lead. For hands-on projects showing both models in agentic workflows, the gen-ai-experiments cookbook repo has Python notebooks covering MCP agent patterns with both Gemini and Claude APIs.
5. Gemini 3.5 Flash vs DeepSeek V4: Cheapest AI API Showdown
DeepSeek V4 Flash is the cheapest production AI API in May 2026 — at $0.14 input / $0.28 output per million tokens, it undercuts Gemini 3.5 Flash by roughly 10x on input and 30x on output. That makes this the most lopsided cost comparison in this article. The question is whether the quality gap justifies the price gap for high-volume applications.
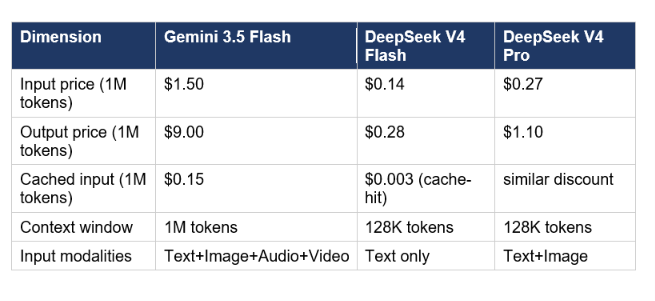
DeepSeek V4 Flash is not a multimodal model. It processes text only. If your pipeline handles images, audio, or video input, Gemini 3.5 Flash has no direct DeepSeek equivalent — the only comparison is DeepSeek V4 Pro, which still lacks audio and video input. For pure text-to-text agentic pipelines at scale, the economics of DeepSeek are hard to ignore: $0.003 per million cached input tokens versus Gemini Flash's $0.15. On a pipeline that recycles long system prompts across thousands of calls, DeepSeek's cache-hit pricing changes the total cost calculation dramatically.
The critical limitation: DeepSeek V4 Flash is a 128K context model versus Gemini 3.5 Flash's 1M. For financial document analysis, long-codebase review, or anything that needs to hold a full document in context, this is not a tier difference — it is a category difference. You cannot replicate a 1M-context use case by chunking into 128K windows without fundamentally changing your architecture and increasing error rates on long-range dependency tasks.
My honest recommendation: if your workload is high-volume text generation — summarization, classification, translation, short-form content — and you do not need multimodal inputs or context windows over 50K tokens, DeepSeek V4 Flash is the rational API choice in 2026. If you need multimodality, long context, or Google Workspace integrations, Gemini 3.5 Flash is worth the 10x premium.
6. Gemini 3.5 Flash vs Gemini 3.1 Pro: What Actually Changed
Gemini 3.5 Flash beats Gemini 3.1 Pro on coding and agentic benchmarks while costing 25% less on input. That is an inversion of the historical Pro-Flash hierarchy, and it is the result of a deliberate architectural shift, not a fluke benchmark resul
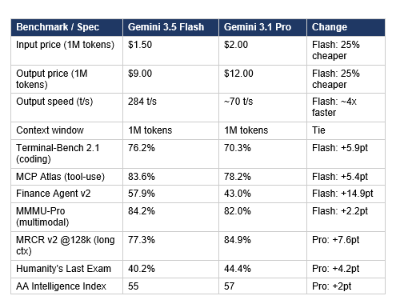
The pattern is clear: Gemini 3.5 Flash wins on everything agentic and multimodal, and loses on everything that requires deep knowledge retrieval or complex reasoning over long documents. The 14.9-point gap on Finance Agent v2 is not incremental improvement — it is a tier change on MCP-driven financial workflows. The 7.6-point gap on MRCR v2 at 128k favoring 3.1 Pro is equally real: if your workload is needle-in-haystack retrieval over long enterprise documents, the previous flagship is still the stronger model for that specific job. For developers running the Google AI Studio vibe coding environment who need to decide between these two for their builds, the complete Google AI Studio development guide covers how both models behave inside the Antigravity 2.0 harness and which tasks warrant the Pro tier.
7. Gemini 3.5 Flash vs Gemini 3.5 Pro: Should You Wait?
Gemini 3.5 Pro was confirmed at Google IO 2026 and is targeting a June 2026 release. No benchmarks, spec sheet, or pricing have been published yet. Here is what we can reason about based on the Pro-Flash pattern across previous Gemini generations and what Google has signaled.
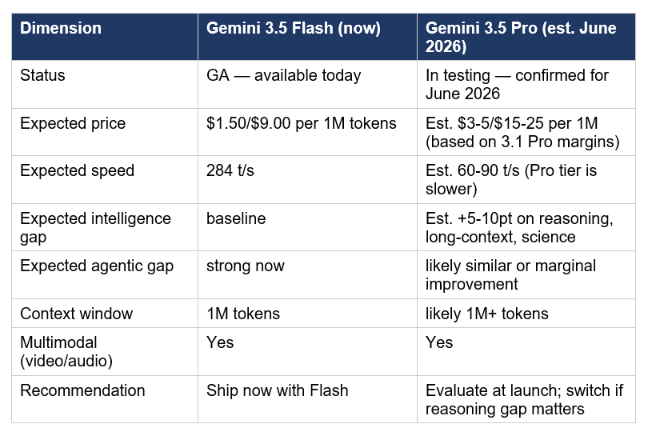
My honest position: do not wait for Pro if your use case maps to what Flash already wins. The I/O audience audibly reacted when Pichai announced Pro was still a month away — which tells you the developer community expected it at the keynote. Google shipped Flash first specifically because Gemini Spark, Antigravity 2.0, and every consumer agent they launched at IO runs on Flash. It is not a placeholder.
The one use case where waiting makes sense: if your workload is genuinely demanding on long-context retrieval, scientific reasoning, or Humanity's Last Exam-style knowledge depth, Flash has documented gaps against the Pro tier. Gemini 3.5 Pro will close those gaps. Everything else — MCP tool chains, multimodal grounding, cost-sensitive agentic pipelines — is Flash territory today.
8. Production Routing Guide: Which Model for Which Job
After running every benchmark in this article, here is the decision framework I would use for production routing as of May 20, 2026. These are not theoretical preferences — they are based on which model leads the specific benchmark that most closely resembles each workload type
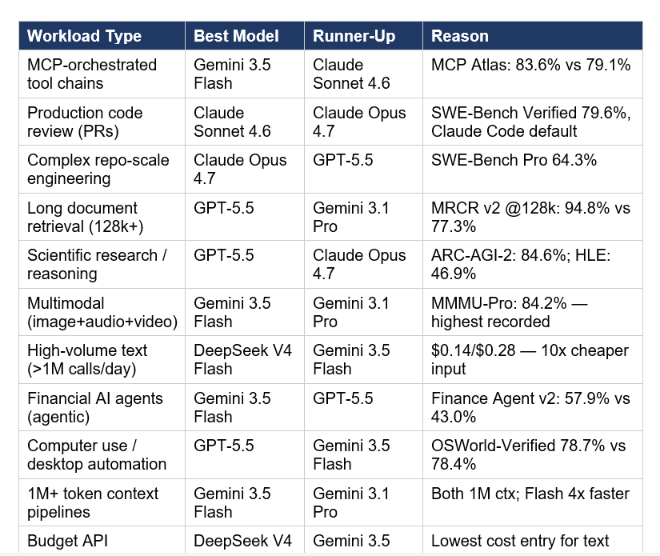
The one routing mistake I see most often: developers pick one model for everything because switching feels complex. Given the cost gap between Gemini 3.5 Flash ($1.50 input) and GPT-5.5 ($5.00 input), routing even 30% of non-reasoning workloads to Flash cuts total API spend by a meaningful fraction at scale. The Gemini API and OpenAI API both follow the same completion pattern, which means a fallback router is 20 lines of Python. For a step-by-step implementation of multi-model routing with the Gemini API, the Gemini Deep Research API Python tutorial shows the exact SDK patterns and the thinking_level migration required when moving from the gemini-3-flash-preview endpoint to gemini-3.5-flash.
Frequently Asked Questions
Is Gemini 3.5 Flash better than GPT-5.5?
On MCP Atlas (multi-step tool-use), Gemini 3.5 Flash leads at 83.6% vs GPT-5.5's 75.3% — an 8.3-point gap. On ARC-AGI-2 (reasoning) and MRCR v2 at 128k (long-context retrieval), GPT-5.5 leads by 12.5 and 17.5 points respectively. Gemini 3.5 Flash is the better model for agentic tool-call workflows. GPT-5.5 is the better model for reasoning and long-document retrieval. Flash costs 3.3x less per token on both input and output.
Is Gemini 3.5 Flash better than Gemini 3.1 Pro?
Yes on coding and agentic benchmarks — Terminal-Bench 2.1 (76.2% vs 70.3%), MCP Atlas (83.6% vs 78.2%), Finance Agent v2 (57.9% vs 43.0%). No on long-context retrieval — MRCR v2 at 128k is 77.3% vs 84.9% in Pro's favor. Flash also costs 25% less per token and runs approximately 4x faster. For most agentic production workloads launched after Google IO 2026, Flash is the stronger default choice.
How does Gemini 3.5 Flash compare to Claude Sonnet 4.6 for coding?
Gemini 3.5 Flash leads Claude Sonnet 4.6 on MCP Atlas (83.6% vs 79.1%), Terminal-Bench 2.1, Finance Agent v2, and costs 2x less on input ($1.50 vs $3.00/M tokens). Claude Sonnet 4.6 leads on SWE-Bench Verified (79.6%) and is the default model for Claude Code. Flash is better for high-volume agentic tool chains. Sonnet 4.6 is better for production code review that must be correct on the first pass.
Is GPT-5.5 out and how much does it cost?
Yes — GPT-5.5 launched April 23, 2026 and is available via the OpenAI API. Pricing is $5.00 per million input tokens and $30.00 per million output tokens — 3.3x more expensive than Gemini 3.5 Flash on both legs. GPT-5.5 leads on ARC-AGI-2 (84.6%), MRCR v2 at 128k (94.8%), and GDPval-AA (1,769 Elo). It is the strongest reasoning model available as of May 2026.
What is the cheapest AI API for coding in 2026?
DeepSeek V4 Flash is the cheapest production AI API in May 2026 at $0.14 input / $0.28 output per million tokens — roughly 10x cheaper than Gemini 3.5 Flash on input. For pure text-to-text workloads without multimodal requirements and under 128K context, it is the rational budget choice. Gemini 3.5 Flash is the cheapest production-grade multimodal API that supports text, image, audio, and video input.
Should I use Gemini 3.5 Flash or wait for Gemini 3.5 Pro?
Use Gemini 3.5 Flash now for agentic, coding, and multimodal workloads. Wait for Pro if your use case requires strong long-context retrieval, scientific reasoning, or benchmark performance comparable to Humanity's Last Exam-style knowledge tasks — areas where Flash has documented gaps against the previous Pro tier. Gemini 3.5 Pro is confirmed for June 2026 with no specific date.
Which AI model is best for agents in 2026?
For MCP-orchestrated multi-step tool chains: Gemini 3.5 Flash (MCP Atlas 83.6%, Finance Agent v2 57.9%). For terminal-native coding agents: GPT-5.5 (Terminal-Bench 2.1 78.2%). For Claude Code-based engineering agents: Claude Sonnet 4.6 (SWE-Bench Verified 79.6%). The right answer depends entirely on what your agent orchestrates. There is no universal winner in May 2026.
How much faster is Gemini 3.5 Flash than other AI models?
Gemini 3.5 Flash generates approximately 284 tokens per second via the Google API — roughly 3x faster than GPT-5.5 (approximately 90 t/s) and approximately 4.7x faster than Claude Sonnet 4.6 (approximately 60 t/s). In Antigravity 2.0, Google demonstrated Flash running 93 parallel subagents processing 15,000+ requests in 12 hours for under $1,000.
Recommended Blogs
- Gemini 3.5 Flash Review: Benchmarks, Price & API (2026)
- Best AI Models May 2026 Leaderboard: GPT-5.5, Claude Opus 4.7, DeepSeek V4
- Claude Sonnet 4.6 vs GPT-5.5 vs Gemini 3.1 Pro: Best All-Rounder in 2026?
- Google I/O 2026: Gemini 3.5 Flash, Spark & Agentic AI
- Gemini Deep Research API: Full Python Tutorial (2026)
- Google AI Studio Vibe Coding: Full Guide (2026)
- Gemini in Google Workspace: Every Feature Explained (2026)
References
- Google DeepMind — Gemini 3.5 Flash Official Benchmark Table (May 19, 2026)
- Artificial Analysis — Gemini 3.5 Flash Intelligence, Performance & Price Analysis
- BenchLM — Gemini 3.5 Flash vs GPT-5.5: AI Benchmark Comparison 2026
- LLM Stats — Claude Sonnet 4.6 vs Gemini 3.5 Flash Comparison
- Digital Applied — Gemini 3.5 Flash vs GPT-5.5 vs Opus 4.7: Agentic Coding
- WaveSpeed — Gemini 3.5 Flash Shipped: Flash-Tier Model Leads Agent Benchmarks
- DevTk.AI — AI API Pricing Comparison: 40+ Models Side-by-Side (May 2026)
DevToolPicks — Gemini 3.5 Flash vs Claude Sonnet 4.6 for Indie Hackers 2026

