




Best AI Models of July 2026: Full Ranking by Use Case, Benchmarks, and Price
July 2026 is the most consequential month for AI model availability in the category's history. On June 12, a US export-control directive forced Anthropic to suspend Claude Fable 5 and Mythos 5 globally, the first time frontier AI models were switched off by regulatory order. On June 26, OpenAI launched GPT-5.6 (Sol, Terra, and Luna) behind a government-managed access list, the first frontier model launch gated by government coordination. On June 30, Anthropic launched Claude Sonnet 5, which became the new default for all Free and Pro users on the same day. And on July 1, the US Commerce Department lifted the export-control directive, restoring Claude Fable 5 to global access 18 days after it went offline. This is the landscape you are navigating in July 2026. The best AI model in the world returned from suspension. A new model family with a government-gated rollout is moving toward general availability. The mid-tier model that replaced Fable 5 during suspension is now cheaper and better than the previous generation's flagship. Open-weight models from China briefly topped coding leaderboards while the proprietary models were restricted. This guide cuts through all of that. We rank every major model across nine use cases, show you the benchmark data that actually matters, give you the honest pricing picture, and tell you exactly which model to use for your specific workflow in July 2026.
1. The State of AI in July 2026: What Just Changed
Four things happened at the end of June and start of July 2026 that every AI practitioner needs to understand before making any model decision:
Claude Fable 5 returned (July 1, 2026). On June 12, a US government export-control directive required Anthropic to suspend Fable 5 and Mythos 5 globally, affecting all users regardless of nationality. On June 30, the US Commerce Department lifted the controls. On July 1, Fable 5 returned to Claude.ai, the Claude Platform API, Claude Code, and Claude Cowork, carrying a tighter safety classifier and stricter export-use conditions. Mythos 5 remains restricted to approved US organizations only. Fable 5 is now the best publicly available model again, but with new behavioral constraints from the updated safety layer.
Claude Sonnet 5 launched and became the new consumer default (June 30, 2026). With Fable 5 suspended during June, Anthropic launched Claude Sonnet 5 as the new default for Free and Pro users. It scores 63.2% on SWE-bench Pro, beats Claude Opus 4.8 on Terminal-Bench 2.1 (80.4% vs 74.6%), and is priced at $2/$10 per million tokens through August 31, 2026. Even with Fable 5 back, Sonnet 5 at $2 input is now the right default for most production workloads that were previously using Opus 4.8.
GPT-5.6 is in limited preview (launched June 26, 2026). OpenAI launched GPT-5.6 Sol, Terra, and Luna with government coordination, restricting initial access to approximately 20 trusted partner organizations. Sol scores 91.9% on TerminalBench 2.1 (Sol Ultra). Terra matches GPT-5.5 at half the price. Luna scores 82.5% on TerminalBench at $1 input. General availability is expected in mid-July 2026.
GLM-5.2 briefly led open-weight coding benchmarks. When Fable 5 was suspended on June 12 and GPT-5.6 was gated, GLM-5.2 (released June 13, MIT license) inherited the top coding benchmark spot for open-weight models: 62.1% on SWE-bench Pro, an Artificial Analysis #1 independent lab ranking, and 1M token context at $1.40/$4.40. It remains the strongest self-hostable coding model available.
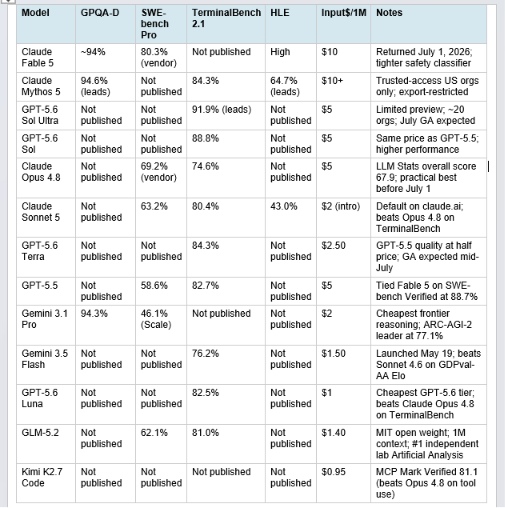
2. Master Benchmark Table: All Models, All Dimensions
All figures below are the most recently published independent or vendor-reported numbers as of July 2, 2026. Where Anthropic's vendor-reported scores differ from Scale's standardized harness, both are noted.
Humanity's Last Exam leader; 2M context; 4-agent council
Important reading note: SWE-bench Pro on Scale's standardized harness is 10 to 20 points lower than vendor-reported scores for the same model. Vendor harnesses are tuned; Scale's harness is identical across models. Both numbers matter; they measure different things. When comparing across models, use Scale SEAL scores for apples-to-apples. When deciding whether a model can handle hard coding tasks, vendor-reported scores with a known harness tell you the ceiling.
3. Best Overall AI Model: July 2026
Winner: Claude Fable 5 (returned July 1, 2026)
Fable 5 is back, and it reclaims the top overall position on the strength of its benchmark profile: 80.3% on SWE-bench Pro (vendor), 95% SWE-bench Verified, and the highest intelligence scores on the Artificial Analysis leaderboard. The updated tighter safety classifier that came with the July 1 return is the most important behavioral change to understand. The model is more likely to refuse borderline requests, more likely to add safety caveats, and has updated export-use terms that teams with international operations need to review before deploying. For most professional domestic use cases: Fable 5 at $10/$50 per million tokens is the strongest model available. For cost-sensitive workflows, Sonnet 5 at $2/$10 intro covers 90% of what Fable 5 does at 80% cheaper. The honest use case for Fable 5 in July 2026 is the top 5 to 10% of tasks that require the absolute capability ceiling: the hardest multi-file code migrations, the most complex reasoning chains, and the highest-stakes agentic operations where correctness genuinely cannot be compromised.
Runner-Up: Claude Sonnet 5 (for most daily workflows)
Before Fable 5 returned, Sonnet 5 was doing the work of a flagship at mid-tier pricing. After July 1, it is still doing that work because $2 per million input tokens through August 31 is a genuinely different economic proposition than $10. Sonnet 5 beats Opus 4.8 on Terminal-Bench 2.1 (80.4% vs 74.6%), ties Fable 5 on GDPval-AA knowledge work, and comes within 6 percentage points of Opus 4.8 on SWE-bench Pro. For detailed benchmarks and the tokenizer-change cost caveat, the Claude Sonnet 5 full review covers every published benchmark and the effort-level cost curve.
4. Best for Coding and Software Engineering

The honest routing logic for coding in July 2026: use Claude Sonnet 5 as your production default. It is cheaper than Opus 4.8, beats it on Terminal-Bench, and covers 80-plus percent of real-world coding tasks at $2 input. Escalate to Fable 5 for the hardest 5 to 10% of tasks where the 17-point SWE-bench Verified gap between Sonnet 5 and Fable 5 actually shows up in output quality. For budget-constrained teams, GLM-5.2 at $1.40 input is the strongest open alternative that can be self-hosted or run on your own infrastructure. For the full head-to-head coding comparison including Kimi K2.7 and GPT-5.6, the GLM-5.2 vs Claude Opus 4.8 vs GPT-5.6 vs Kimi coding comparison covers every dimension in detail.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Best for Reasoning and Research
Reasoning benchmarks in 2026 have diversified from the simple GPQA Diamond into a richer set: Humanity's Last Exam (HLE) for absolute frontier knowledge, GPQA Diamond for PhD-level science, ARC-AGI-2 for novel reasoning that cannot be memorized, and FrontierMath Tier 4 for the hardest mathematical problems available. Each model leads a different benchmark.
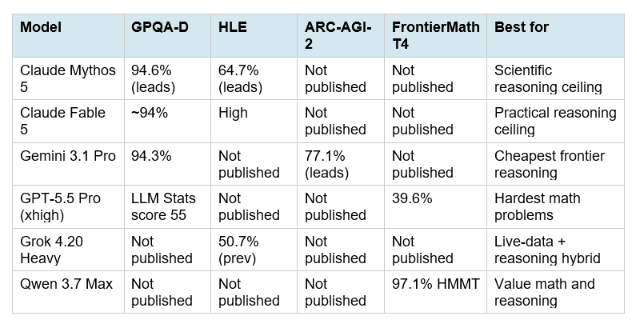
Gemini 3.1 Pro is the recommendation for pure reasoning at an accessible price point. At $2/$12 per million tokens with 94.3% GPQA Diamond, it is the most cost-efficient frontier reasoning model available in July 2026, and the ARC-AGI-2 score of 77.1% demonstrates genuine novel reasoning capacity rather than benchmark memorization. The 20 to 30% higher token generation rate compared to GPT models is the main cost caveat to plan around. For Humanity's Last Exam frontier tasks where the absolute knowledge ceiling matters, Claude Mythos 5 leads at 64.7%, but its access is restricted to approved US organizations only. For teams doing multi-modal reasoning across large document sets, Gemini 3.1 Pro's 1M-token context window at this price point has no equivalent from any other major lab.
6. Best for Writing and Knowledge Work
GDPval-AA v2 is the benchmark that most accurately captures writing and knowledge work performance, measuring AI across 44 professional occupations including software engineers, lawyers, nurses, and financial analysts. Claude Sonnet 5 edges Claude Opus 4.8 on this benchmark (1,618 Elo vs 1,615), and Gemini 3.5 Flash reached 1,656 Elo, edging both Claude models at a lower price.
- Best for long-form documents and drafting: Claude Sonnet 5 or Claude Fable 5. The Claude family produces the most natural prose, handles nuanced tone consistently across long outputs, and can produce 128K output tokens in a single pass. Fable 5's tighter safety classifier is worth knowing about for creative content that is borderline.
- Best for editing and revision: GPT-5.5 or GPT-5.6 Terra (pending GA). OpenAI's Canvas environment is the best AI-assisted editing interface available, and GPT models continue to lead on factual accuracy and hallucination rates for structured, fact-anchored writing like reports and briefs.
- Best for email and professional communication at scale: Gemini 3.5 Flash at $1.50/$9 per million tokens. The May 19, 2026 model with 1,656 GDPval-AA Elo at this price point is the most efficient model for high-volume professional writing that does not require frontier-level reasoning depth.
- Best for multilingual writing: Gemini 3.1 Pro or Kimi K2.7. Gemini's native multilingual training and Kimi's six-language native audio and text support both handle non-English content more reliably than the Anthropic and OpenAI models on non-English-dominant tasks.
7. Best for Agentic and Long-Horizon Tasks
Agentic AI in July 2026 is where the model-vs-system distinction matters most. Every major frontier model performs differently on autonomous multi-step tasks depending on the scaffolding it runs through. The benchmark numbers below are model-level; in production, your agent framework, tool configuration, and context management will shift results significantly. Claude Code with Claude Fable 5 or Opus 4.8 remains the strongest general-purpose agentic coding environment, used by Anthropic's own team to generate 65% of internal product code. Fable 5's dynamic workflow capability, where Claude Code plans a task and fans it out across hundreds of parallel subagents, is the most capable agentic architecture currently available outside of government-controlled research environments. Opus 4.8 supports the same workflow at half the price. GPT-5.6 Sol Ultra's subagent decomposition mode, where Sol dispatches parallel subagents for complex problems, is the direct OpenAI counterpart to Claude's dynamic workflow. At 91.9% on TerminalBench 2.1 Sol Ultra represents the highest published agentic coding benchmark score as of July 2, 2026, though the numbers are vendor-reported and unverified while the model remains in preview. For browser and computer use agents, Claude Sonnet 5 at 81.2% OSWorld and Opus 4.8 at 83.4% OSWorld are the most reliable production options. Sonnet 5's 0.93% prompt-injection attack success rate in browser-use testing (versus 31.5% for Opus 4.8 without safeguards) makes it the safer choice for automated browser workflows operating in less controlled environments. For highest-volume swarm-agent workflows with many parallel tool calls, Kimi K2.7's 300-agent parallel swarm architecture and 81.1% MCP Mark Verified score make it the best tool-call accuracy model at the lowest cost per call.
8. Best Budget and Value Models
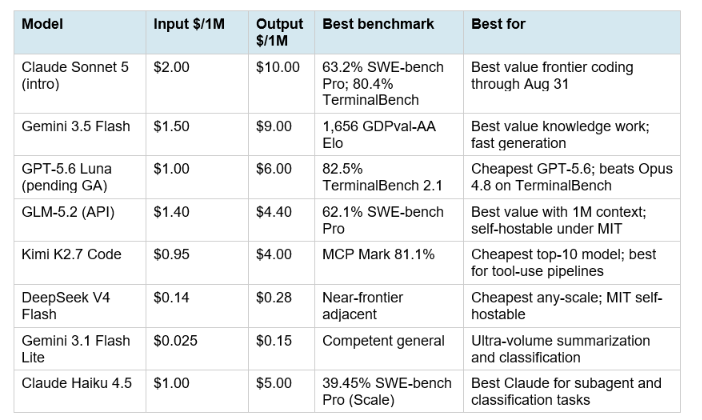
The value framework that actually matters in 2026 is cost per task, not cost per token. A model that uses three times as many tokens to complete the same task is not cheaper because its rate card is lower. Before choosing a budget model, run the same 20 representative prompts from your actual workflow through each candidate and measure total token consumption. Gemini models historically generate 20 to 30% more tokens per task than Claude models on the same prompts, which partially offsets their lower rate card.
9. Best Open-Weight Models
The open-weight category shifted dramatically in June 2026. When Claude Fable 5 was suspended on June 12 and GPT-5.6 launched behind government gates on June 26, open-weight models temporarily led the publicly accessible coding leaderboard for the first time. GLM-5.2 (June 13) and MiniMax M3 (June 1) briefly held the top two spots on SWE-bench Pro among models anyone could actually use.
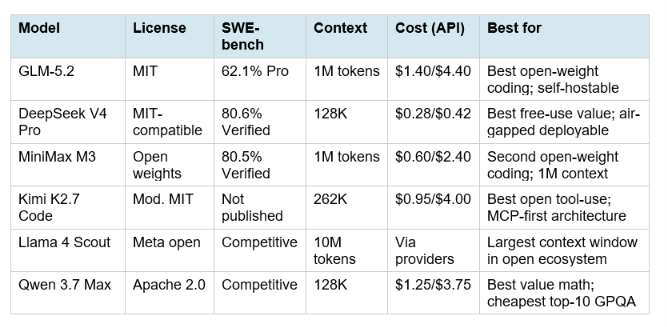
The defining open-weight story of July 2026: the gap between the best open model (GLM-5.2 at 62.1% SWE-bench Pro) and the best closed model (Claude Fable 5 at 80.3% SWE-bench Pro) is now measured in single-digit percentage points on some benchmarks and 18 points on SWE-bench Pro specifically. That 18-point gap is real and meaningful for the hardest production coding tasks. But it is also the smallest that gap has ever been, and GLM-5.2 closing it at MIT license and $1.40 input pricing is the inflection point that the open-source community has been waiting for. For the full GLM-5.2 technical review including the 1M context window, Cursor training data integration, and self-hosting guidance, the GLM-5.2 vs Claude Opus 4.8 vs GPT-5.6 vs Kimi comparison covers every relevant dimension.
10. Best AI for Business and Enterprise
Best Overall Enterprise Model
Claude Fable 5 (now back as of July 1) for maximum quality. Claude Opus 4.8 for the 90% of enterprise workflows that do not need the Fable 5 ceiling at half the price. Both are backed by Anthropic's enterprise data handling, SOC 2 Type II compliance, HIPAA BAA availability, and zero data retention option.
Best for Google-Native Enterprises
Gemini 3.1 Pro via Google Workspace or Vertex AI. The native integrations with Gmail, Docs, Drive, Meet, and BigQuery make Gemini the default choice for organizations already running on Google infrastructure. The pricing at $2/$12 per million tokens for frontier-class reasoning, and the Gemini Enterprise Agent Platform (GEAP) for video and image generation pipelines, make this the most vertically integrated enterprise AI stack available. For video and image generation specifically, the pairing of Nano Banana 2 Lite and Gemini Omni Flash reviewed in the Nano Banana 2 Lite review covers how to build complete image-to-video pipelines within the Google ecosystem.
Best for Cost-Optimized Enterprise
Claude Sonnet 5 at $2/$10 intro through August 31, 2026, then $3/$15 standard. For any enterprise that was running Claude Opus 4.8 at $5/$25 for production workloads that are not in the top-10% hardest task categories, migrating to Sonnet 5 before August 31 is a direct cost reduction with no capability sacrifice on the majority of tasks.
Best for Data-Sovereign or Regulated Industries
For organizations in healthcare, finance, government, or legal where data residency matters: Claude Fable 5 or Opus 4.8 on AWS Bedrock or Google Vertex with appropriate DPA arrangements for EU compliance. For air-gapped or on-premise requirements: GLM-5.2 or DeepSeek V4 Pro (MIT-licensed, self-hostable on your own GPU infrastructure). Mistral Large or Medium 3.5 for EU data residency specifically. Note that GLM-5.2 and Kimi K2.7's hosted API routes data through Chinese infrastructure, so self-hosting the open weights is strongly recommended for regulated industry use cases.
11. What to Expect: Key Models Coming in July 2026
- GPT-5.6 Sol, Terra, and Luna general availability: OpenAI has committed to broad access in the coming weeks from the June 26 launch. Mid-July 2026 is the most likely window. Terra at $2.50/$15 will directly challenge Sonnet 5's introductory pricing. Luna at $1/$6 will redefine the volume tier. Independent benchmarks will follow within days of GA.
- Grok 4.5 public launch: xAI's 1.5T V9 model entered private beta at SpaceX and Tesla on June 28. Based on xAI's monthly release cadence, a July 2026 public launch is the most plausible window. Early internal evals show performance close to Claude Opus 4.8. Independent benchmarks will determine whether that claim holds.
- Gemini 3.5 Pro wider availability: in limited rollout as of mid-June 2026 with a 2M-token context window and frontier-class quality. Broader developer API access is expected in July 2026.
- Claude Sonnet 5 pricing cliff: the introductory $2/$10 pricing ends August 31, 2026, reverting to $3/$15. Teams migrating from Sonnet 4.6 or Opus 4.8 should benchmark their real token consumption before August 31 to confirm cost neutrality after the tokenizer change (which generates up to 1.35x more tokens for the same text).
- GPT-5.6 Sol on Cerebras: OpenAI announced GPT-5.6 Sol deployment on Cerebras infrastructure at up to 750 tokens per second in July 2026. At 10 to 15 times typical frontier model API speeds, this changes the user experience for interactive agentic workflows.
For the full Grok 4.5 technical breakdown including the V9 architecture, Cursor training data integration, and xAI's roadmap through the rest of 2026, the Grok 4.5 review covers everything currently known. For GPT-5.6's Sol/Terra/Luna tier architecture, pricing, and the TerminalBench benchmark data, the GPT-5.6 review has the full analysis.
Frequently Asked Questions
What is the best AI model in July 2026?
Claude Fable 5, which returned to global access on July 1, 2026 after an 18-day government-mandated suspension, is the strongest publicly available AI model in July 2026 for users who need the absolute capability ceiling. For most professional daily workflows, Claude Sonnet 5 at $2/$10 per million tokens intro pricing through August 31, 2026 is the better choice: it beats Claude Opus 4.8 on Terminal-Bench 2.1, ties it on GDPval-AA knowledge work, and costs 60% less. There is no single best model for all use cases; the best model depends on your specific task.
Is Claude Fable 5 available again?
Yes. The US Commerce Department lifted the export-control directive on June 30, 2026, and Anthropic restored Claude Fable 5 to global access on July 1, 2026. The model is available on Claude.ai for Max, Team, and Enterprise plan users, in the Claude Platform API, Claude Code, and Claude Cowork. Fable 5 returned with a tighter safety classifier and updated export-use terms. Claude Mythos 5 remains restricted to approved US organizations under the Glasswing program and is not generally available.
Which AI model is best for coding in July 2026?
For the highest coding ceiling: Claude Fable 5 (80.3% SWE-bench Pro, vendor) returned July 1. For the best value: Claude Sonnet 5 at $2 input intro pricing through August 31, 2026, scoring 63.2% SWE-bench Pro and beating Claude Opus 4.8 on Terminal-Bench 2.1. For open-source self-hosted: GLM-5.2 at 62.1% SWE-bench Pro with MIT license and 1M context at $1.40 input. For swarm-agent tool-use pipelines: Kimi K2.7 Code at $0.95 input with 81.1% MCP Mark Verified.
What is the cheapest frontier AI model in July 2026?
The cheapest among broadly accessible frontier models: GPT-5.6 Luna at $1/$6 per million tokens (pending general availability in mid-July), Kimi K2.7 Code at $0.95/$4.00, Claude Haiku 4.5 at $1/$5, and GLM-5.2 at $1.40/$4.40. For ultra-volume tasks: DeepSeek V4 Flash at $0.14/$0.28 is the cheapest model with near-frontier adjacent performance, self-hostable under MIT. For Claude specifically: Claude Sonnet 5 at $2/$10 intro is the cheapest Claude tier with genuine frontier coding performance through August 31, 2026.
Which AI model has the best reasoning in July 2026?
Reasoning benchmark wins are split across models. Claude Mythos 5 leads on GPQA Diamond (94.6%) and Humanity's Last Exam (64.7%), but is restricted to approved US organizations. Claude Fable 5 is the best reasoning model you can actually access at scale. Gemini 3.1 Pro leads on ARC-AGI-2 (77.1%) and ties Mythos 5 on GPQA Diamond at 94.3%, while being accessible at $2 input. Grok 4.20 led Humanity's Last Exam in its prior generation at 50.7% and remains the best choice for combining live X data with frontier reasoning.
How does Claude Sonnet 5 compare to GPT-5.6 Terra?
Both target the same price-performance tier: Sonnet 5 at $2/$10 intro (rising to $3/$15 in September), Terra at $2.50/$15 pending GA. On Terminal-Bench 2.1, Sonnet 5 scores 80.4% and Terra scores 84.3% (vendor-stated, preview-only, unverified). On SWE-bench, Sonnet 5 has published a 63.2% Pro score; Terra's SWE-bench has not been published by OpenAI. Terra reaches general availability in mid-July; until then, Sonnet 5 is the only one you can actually use.
Which open-source AI model is best in July 2026?
GLM-5.2 (Z.ai, MIT license, released June 13, 2026) is the strongest open-weight coding model in July 2026 at 62.1% SWE-bench Pro, with a 1M-token context window at $1.40/$4.40 via hosted API or fully self-hostable. DeepSeek V4 Pro is the best value model overall at $0.28/$0.42 with 80.6% SWE-bench Verified, MIT-compatible and freely self-hostable. For enterprise air-gapped deployments: either GLM-5.2 or DeepSeek V4 running on your own GPU infrastructure eliminates API data-routing concerns.
What happened to Claude Fable 5 and Mythos in June 2026?
On June 12, 2026, a US government export-control directive required Anthropic to suspend global access to Claude Fable 5 and Mythos 5. Because access cannot be gated by nationality in real time, both models went offline for all users globally. The suspension was the first time frontier AI models were switched off by regulatory order. On June 30, the US Commerce Department lifted the controls. Fable 5 returned to global access on July 1, 2026, with a tighter safety classifier and updated export-use terms. Mythos 5 remains restricted to approved US organizations through the Glasswing program.
Is GPT-5.6 Sol available to the public yet?
As of July 2, 2026, GPT-5.6 Sol, Terra, and Luna are in limited preview accessible to approximately 20 government-approved partner organizations. General availability for ChatGPT users and the public API is expected in mid-July 2026. OpenAI's own language was 'coming weeks' from the June 26, 2026 announcement.
Recommended Blogs
- Best AI Models and Leaderboards Collection: Updated Rankings and Benchmark Data
- Claude Sonnet 5 Review: Benchmarks, Pricing and Is It Worth It? (2026)
- GPT-5.6 Review: Sol, Terra, Luna Features, Benchmarks, and Pricing
- GLM-5.2 vs Claude Opus 4.8 vs GPT-5.6 vs Kimi: Best Coding AI Model (2026)
- Grok 4.5 Review: xAI's 1.5 Trillion Parameter Beta Model Explained
- Nano Banana 2 Lite Review: Fastest AI Image Generator? Benchmarks and Pricing (2026)
Resources & Community
Join our community of 70,000+ AI enthusiasts and learn to build powerful AI applications! Whether you're a beginner or an experienced developer, Build Fast with AI helps you understand and implement AI in your projects.
- Website: buildfastwithai.com
- LinkedIn: Build Fast with AI
- Instagram: @buildfastwithai
- Founder Twitter: @satvikps
- Twitter: @BuildFastWithAI
Agentic AI Launchpad 2026
A structured 6-week cohort program that takes you from AI basics to building and deploying real-world agentic AI systems. Includes live sessions, expert mentorship, project reviews, and a builder community network.
Ready to go from learning to building? Join the next cohort: Agentic AI Launchpad 2026
Free AI Resources
Access free tools, workshops, and micro-learning to keep building:
- AI Workshops: Free resources, upcoming events and past recordings
- Unrot: Learn AI in 5 minutes a day (free micro-learning app)
The AI model leaderboard is repricing and reshuffling every week. Follow @BuildFastWithAI on X to stay ahead of every model launch, benchmark update, pricing change, and access development that matters for your workflow.
References
- Artificial Analysis: LLM Intelligence Index Leaderboard (July 2026)
- LLM Stats: Best AI Models Leaderboard (July 2026)
- AI Release Tracker: Latest AI Model Releases July 2026
- The AI Rankings: Best AI Models in 2026 (Claude Fable 5 return, July 1 update)
- Morph LLM: Best AI Model for Coding (June 2026): 12 Models Ranked
- Fello AI: Best AI Models in June 2026: ChatGPT, Claude, Gemini and Grok
- Brave New Coin: What AI Model Should I Use? The 2026 Guide (July 2026 update)
- LM Council: AI Model Benchmarks July 2026 Interactive Comparison
- Punku AI: AI Comparison 2026 Data Overview (LLM Stats June 3 snapshot)
- ClickRank: LLM Leaderboard 2026: Compare 300+ Top AI Models
- Build Fast with AI: GLM-5.2 vs Claude Opus vs GPT-5.6 vs Kimi Coding Comparison
- Build Fast with AI: Claude Sonnet 5 Full Review (June 30, 2026)
- Build Fast with AI: GPT-5.6 Sol Review (June 26, 2026)

