




Claude Sonnet 5 Review: Benchmarks, Pricing, Features, and Is It Worth It?
On June 30, 2026, Anthropic released Claude Sonnet 5, the most agentic Sonnet model ever shipped, and the default model for every Free and Pro user on claude.ai from launch day. The headline numbers: 63.2% on SWE-bench Pro (versus 69.2% for Opus 4.8), 81.2% on OSWorld-Verified (versus 83.4% for Opus 4.8), 84.7% on BrowseComp agentic search, 80.4% on Terminal-Bench 2.1 which actually beats Opus 4.8's 74.6% on that specific benchmark, and 1,618 Elo on GDPval-AA v2 knowledge work which edges Opus 4.8's 1,615. Introductory pricing is $2 per million input tokens and $10 per million output tokens through August 31, 2026, moving to $3/$15 from September onward. Opus 4.8 is $5/$25. This is the first Sonnet that makes Opus 4.8 genuinely optional for most workloads. That is not a marketing line. It is the most accurate description of where the Anthropic model lineup now sits. Sonnet 5 and Opus 4.8 now cover a single cost-performance curve rather than two separate tiers with a large gap between them. For the majority of production coding, agentic task, and knowledge-work use cases, Sonnet 5 at $2 to $3 per million input tokens delivers results that an hour ago required a $5 model to achieve. This review covers every published benchmark in detail, the effort-level cost curve that makes Sonnet 5 the most nuanced Claude model to evaluate, the tokenizer change that affects real-world billing, the safety improvements, what the early adopters are actually saying, and when you should still reach for Opus 4.8 instead.
1. What Is Claude Sonnet 5?
Claude Sonnet 5 is the sixth generation of Anthropic's Sonnet model tier, released June 30, 2026. The Sonnet tier sits between Haiku (fast and cheap) and Opus (maximum capability) in the Claude lineup. For many developers, the agentic era began with Sonnet-class models: Claude Sonnet 3.5, 3.6, and 3.7 were the first models that showed impressive capabilities in coding and tool use. More recently, the clearest gains in agentic capability had moved to Opus-class models. Sonnet 5 narrows that gap significantly. The strategic context matters here: as of the Sonnet 5 launch, Claude Fable 5 and Mythos 5 remain suspended under a US export-control order that went into effect June 12, 2026, with no confirmed return date. That makes Claude Sonnet 5 effectively the best Claude model available to most users right now, with Opus 4.8 as the only higher-capability option still generally accessible. The timing of the Sonnet 5 launch is not accidental. Anthropic is ensuring that the highest-performing generally available model in its lineup is as strong as possible while the top-tier models remain offline.
The model is available under the API model string claude-sonnet-5, which you can use in the Claude Platform API immediately. It is the new default for Free and Pro plans on claude.ai, is available to Max, Team, and Enterprise users, and is live in Claude Code. For the full context of where Sonnet 5 fits alongside Claude Tag, Claude Code, and Anthropic's broader product expansion in 2026, the Claude AI Complete Hub on Build Fast with AI covers every Anthropic model and product update in one place.
2. Benchmark Performance: A Complete Breakdown
Anthropic published a comprehensive benchmark table at launch comparing Sonnet 5, Sonnet 4.6, and Opus 4.8. All figures below are Anthropic's own published numbers as of June 30, 2026.
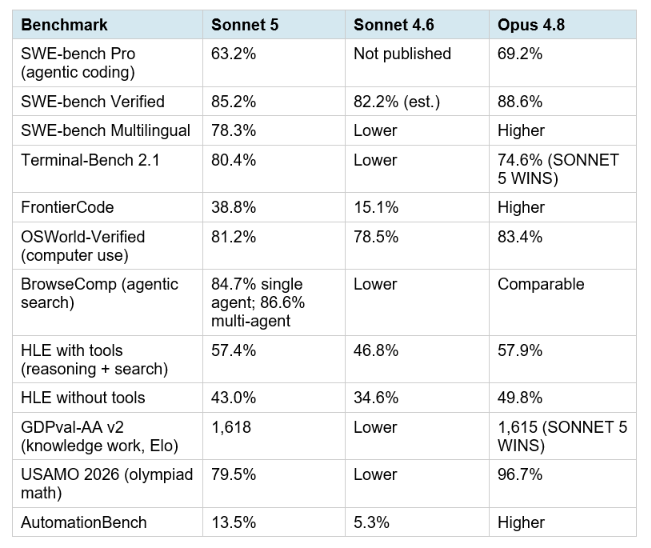
The pattern across the table is consistent and reveals the real story about Sonnet 5. On four of the five top benchmarks, Sonnet 5 lands between Sonnet 4.6 and Opus 4.8, but significantly closer to Opus than to its predecessor. On two benchmarks, it actually beats Opus 4.8 outright: Terminal-Bench 2.1 (80.4% vs 74.6%) and GDPval-AA v2 knowledge work (1,618 Elo vs 1,615 Elo). On HLE with tools, it nearly ties Opus (57.4% vs 57.9%). The number that deserves the most attention for context: FrontierCode improves from 15.1% (Sonnet 4.6) to 38.8% (Sonnet 5), more than doubling on the hardest coding benchmark Anthropic publishes. That is not a marginal quality improvement. That is a generational jump within the same model tier, demonstrating that Sonnet 5 is qualitatively different from Sonnet 4.6, not just a tuning pass on the same architecture.
3. The Effort Level System: How to Think About Cost vs Performance
The most strategically important feature of Claude Sonnet 5 is the effort level system, which exists in previous Opus models but becomes the primary cost-management lever when comparing Sonnet 5 to Opus 4.8. Effort levels in Claude Sonnet 5 run from low through medium, high, max, and x-high (extra high). Higher effort means the model allocates more thinking budget per response, producing more accurate results at higher token cost. Anthropic's published cost-performance curves on BrowseComp and OSWorld-Verified tell the complete story. At x-high effort, Sonnet 5 performs roughly in line with Opus 4.8 at medium-to-high effort on both benchmarks. But the catch is explicit: running Sonnet 5 at x-high can cost more per equivalent accuracy point than running Opus 4.8 at a comparable effort level. The implication is that Sonnet 5 is not always cheaper than Opus 4.8 when accounting for effort. The optimization is at medium effort, where Sonnet 5 provides substantially improved cost efficiency over both Sonnet 4.6 and Opus 4.8 at similar accuracy levels
The practical guidance: for most production agentic workflows where medium effort covers the accuracy requirement, Sonnet 5 is the right default and will cost less than Opus 4.8 at any equivalent effort setting. For the hardest tasks that require x-high effort, run the per-task cost math before assuming Sonnet 5 is the cheaper option. In Claude Code, the /effort command controls this setting. In the API, the effort parameter maps to the same scale.
4. Claude Sonnet 5 Pricing and the Tokenizer Catch
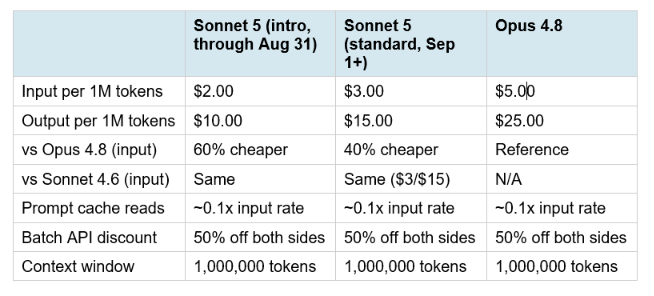
The introductory pricing runs through August 31, 2026. The $3/$15 standard pricing that kicks in on September 1 matches Sonnet 4.6's existing rate card, which Anthropic frames as cost-neutral by design. But the tokenizer change matters and deserves clear explanation. Sonnet 5 uses an updated tokenizer (the same one introduced with Claude Opus 4.7) that changes how text maps to tokens. The same input can produce roughly 1.0 to 1.35 times more tokens under the new tokenizer compared to Sonnet 4.6. That means even though the rate card is identical at $3/$15 per million tokens, your actual per-task cost at standard pricing can be up to 35% higher than Sonnet 4.6 for the same text content. Anthropic set the introductory pricing at $2/$10 specifically to make the transition roughly cost-neutral during the initial adoption window. Teams migrating from Sonnet 4.6 to Sonnet 5 before August 31 should benchmark their real-world token consumption before committing to the switch for cost-sensitive production workloads.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Coding Performance: SWE-bench Pro, Terminal-Bench, FrontierCode
Coding is the dimension that matters most for the developer audience that made the Sonnet model line the default for production AI coding in 2025 and 2026. The headline coding results from the Sonnet 5 launch: SWE-bench Pro at 63.2% is the hardest coding benchmark in this comparison. It uses real actively-maintained repositories with no training-data leakage, the variant that most accurately reflects what the model can do on production codebases. Sonnet 5's 63.2% sits six points behind Opus 4.8's 69.2% and roughly 4.5 points ahead of GLM-5.2's 62.1% (the strongest open-weight coding model as of June 2026). SWE-bench Verified at 85.2% is a meaningful improvement over Sonnet 4.6 on the easier but more commonly quoted benchmark variant.
Terminal-Bench 2.1 is where the most interesting competitive story lives. Sonnet 5 scores 80.4%, beating Opus 4.8's 74.6% by 5.8 points. This is the first time a mid-tier Sonnet model has beaten its Opus sibling on a major coding benchmark, and it directly challenges the previous framing that terminal-agent work required the larger model. For developers running CLI-heavy agentic workflows, orchestrating Docker environments, running database migrations, or executing multi-step shell pipelines autonomously, Sonnet 5's Terminal-Bench 2.1 lead over Opus 4.8 is a genuine competitive claim. FrontierCode at 38.8%, doubling Sonnet 4.6's 15.1%, is the third data point that confirms this is a structurally different model. For context on the competitive landscape where GLM-5.2 and Kimi K2.7 are also pushing SWE-bench Pro scores toward the 60% range at dramatically lower prices, the GLM-5.2 vs Claude Opus vs GPT-5.6 vs Kimi coding comparison covers the full competitive coding benchmark picture as of July 2026.
6. Agentic Performance: BrowseComp, OSWorld, AutomationBench
Agentic performance is where Anthropic made the most deliberate claims in the Sonnet 5 launch and where the improvement over Sonnet 4.6 is most decisive. BrowseComp is Anthropic's primary benchmark for agentic web research: the model has to search the web, find information, and synthesize correct answers over many steps and tool calls. Sonnet 5 scores 84.7% as a single agent and 86.6% in Anthropic's multi-agent setup, run with a 10 million token operating budget and context compaction activating at 200K tokens. The multi-agent figure is within the margin of noise of Opus 4.8's BrowseComp score, which Anthropic describes as 'comparable' rather than meaningfully different. This is the most direct evidence that for research-intensive agentic workflows specifically, Sonnet 5 at $2 to $3 input does genuinely compete with Opus 4.8 at $5 input.
OSWorld-Verified measures computer-use capability, specifically how well the model controls a live desktop environment through screenshot observation and action planning. Sonnet 5 scores 81.2%, up from Sonnet 4.6's revised 78.5% baseline, and close to Opus 4.8's 83.4%. For teams running computer-use agents that need to operate web browsers, fill forms, navigate legacy systems, or execute workflows in real applications, the 2.2-point gap between Sonnet 5 and Opus 4.8 on OSWorld is smaller than the cost difference justifies for most production deployments.
AutomationBench is the honest note. It measures cross-application business automation end to end: completing a workflow that requires multiple API calls, data passes between systems, and correct state management across every step. Sonnet 5 scores 13.5% versus Sonnet 4.6's 5.3%, a real improvement. But 13.5% absolute pass rate also means the model fails 86.5% of the most complex multi-app automation tasks in the benchmark. The benchmark is intentionally strict. The number tells you that cross-application automation at production reliability is still an unsolved problem for all frontier models, not that Sonnet 5 is insufficient for more constrained workflows
7. Professional Work Performance: GDPval, Legal, Finance, Health
Professional knowledge work benchmarks are the dimension where Sonnet 5's case against Opus 4.8 is most surprising. On GDPval-AA v2, which grades AI performance on tasks with direct economic value (professional document creation, analysis, financial modeling, and similar work-like scenarios), Sonnet 5 scores 1,618 Elo, actually higher than Opus 4.8's 1,615. This is a narrow gap almost certainly within methodology noise, but the direction matters: the cheaper model is outperforming or matching the flagship on real-world knowledge work.
Anthropic's system card adds specific domain performance: Sonnet 5 shows improvements on the Legal Agent Benchmark, HealthBench Professional, and Real-World Finance v2 compared to Sonnet 4.6. Early partner feedback from Eve (plaintiff-law firm AI) specifically called out Sonnet 5 as sitting 'on the Pareto frontier for our plaintiff-law tasks' with the 'clearest gains in legal research and analysis.' Pace (insurance workflow automation) reported that 'Sonnet 5 consistently takes the right action and does it quickly, which is what real insurance work demands.'
The pattern across professional domains is consistent: Sonnet 5 has closed the gap to Opus 4.8 on the structured, domain-specific professional work benchmarks more than it has on pure mathematical reasoning (USAMO: 79.5% vs 96.7% for Opus 4.8, still a 17-point gap). For teams doing professional knowledge work where the task is complex judgment and research rather than olympiad-level mathematics, the Sonnet 5 vs Opus 4.8 choice is now primarily an economic question rather than a capability question. For the broader picture of how Claude Tag, Claude Code, and Sonnet 5 together are reshaping enterprise AI workflows, the Claude Tag Slack review covers how Anthropic's agentic product stack is evolving in 2026.
8. Safety Improvements and Cybersecurity Position
Anthropic's pre-deployment safety evaluation found Sonnet 5 is safer than Sonnet 4.6 across all measured dimensions, while being deliberately weaker than Opus 4.8 on cybersecurity-specific tasks.
- Agentic safety: Sonnet 5 is better at refusing malicious requests in agentic contexts and more resistant to prompt-injection hijacking attempts. On browser-use prompt injection specifically, Sonnet 5 shows a 0.93% attack success rate versus 31.5% for Opus 4.8 without safeguards. This is a structural safety improvement for teams running Claude in automated workflows where the model might encounter adversarial input.
- Hallucination and sycophancy: Sonnet 5 shows lower rates of both compared to Sonnet 4.6 on Anthropic's evaluations. The reduction in sycophancy specifically matters for coding workflows where an overly agreeable model will validate incorrect approaches rather than pushing back on flawed plans.
- Behavioral alignment: Sonnet 5 scored lower (safer) overall on Anthropic's automated behavioral audit, which tests cooperation with misuse and deception across a wide range of scenarios. It still shows higher misalignment rates than Opus 4.8 and Mythos Preview on this assessment, which is expected given the capability tier.
- Cybersecurity: Anthropic did not deliberately train Sonnet 5 on cybersecurity tasks. In Firefox 147 exploit development testing, Sonnet 5 never produced a working exploit (0% success). It does show a slightly higher partial-success rate than Sonnet 4.6, which Anthropic attributes to general intelligence improvements rather than specific security training. Cyber safeguards are enabled by default on Sonnet 5 via the Cyber Verification Program.
The cyber safeguards are the same as those in Opus 4.7 and 4.8, which Anthropic notes are less strict than those launched with Fable 5 because the overall cybersecurity risk from Sonnet 5 is assessed as low. For cybersecurity work that requires reduced guardrails, Anthropic explicitly recommends Claude Opus 4.8 rather than Sonnet 5.
9. What Early Access Partners Are Actually Saying
Anthropic published ten partner testimonials at launch from companies that tested Sonnet 5 before public release. The consistent themes across them reveal what the improvement actually feels like in production rather than on benchmarks.
Zimu Li at Augment Code: "Claude Sonnet 5 gives our agents a strong execution layer for multi-step software engineering work. It handles sustained coding, tool use, and debugging well across messy technical contexts, and has been especially useful for workflows where follow-through and technical grounding matter."
Neel Chotai at Rust Engineer: "I asked Claude Sonnet 5 to investigate a bug. Unprompted, it wrote a reproducing test, implemented the fix, then stashed it to confirm the bug came back without the change. All in a single pass."
Dominic Elm at a founding engineering role: "Claude Sonnet 5 is at its best on brownfield code — race conditions, hidden tests, the parts nobody wants to touch. It traces a failure to its actual root cause and ships a durable fix instead of patching the symptom."
Fabian Hedin (Lovable co-founder): "Claude Sonnet 5 gets more done with less. Same output quality, fewer steps to get there. It refuses unsafe requests cleanly and consistently, too."
Ryadh Dahimene at ClickHouse: "Claude Sonnet 5 reasons in tighter steps and gets our users to answers noticeably faster. That speed is a difference our customers feel."
The consistent signal across all ten testimonials: Sonnet 5 completes tasks where Sonnet 4.6 would stall or stop short, checks its own output without being prompted to do so, and maintains accuracy across longer task chains. The brownfield code comment from Dominic Elm and the self-stash behavior from Neel Chotai both describe the same improvement from a different angle: the model reasons about the problem deeply enough to verify its own work rather than just submitting the first plausible-looking answer.
10. Claude Sonnet 5 vs Opus 4.8: When to Choose Which
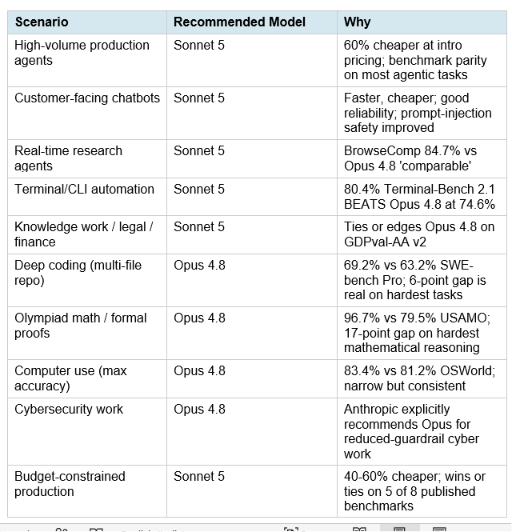
Hot take: if you are running Opus 4.8 for anything other than the three specific scenarios where it clearly outperforms Sonnet 5 (deep multi-file coding at the absolute frontier, olympiad-level mathematics, and cybersecurity research), you are overpaying. The honest cost-performance math after June 30, 2026 is that Sonnet 5 at $2 input through August 31 covers more than two-thirds of production workloads that were previously defaulting to Opus at $5 input.
11. Claude Sonnet 5 vs GPT-5.5 and Gemini 3.5 Flash
Anthropic's system card comparisons at launch used GPT-5.5 and Gemini 3.5 Flash as the primary cross-vendor comparisons (GPT-5.6 had not yet launched on June 30, 2026). The results favor Sonnet 5 overall with some exceptions. On SWE-bench Pro, Sonnet 5 at 63.2% is meaningfully ahead of GPT-5.5 at 58.6% and the vendor-reported figure. On OSWorld-Verified computer use, Sonnet 5 at 81.2% is ahead of GPT-5.5 at 78.7% per Anthropic's system card. On GDPval-AA v2 knowledge work, Sonnet 5 leads by approximately 121 Elo points on Anthropic's evaluation table.
Two areas where the comparison is less clean: GPT-5.5 outperforms Sonnet 5 on Terminal-Bench 2.1 per Anthropic's own cross-vendor comparison table, and Gemini 3.5 Flash scores higher on AutomationBench. These two exceptions track with the consistent finding across the Anthropic lineup that terminal-agent tasks have historically been an area of GPT strength, and that Gemini's architecture gives it specific advantages on structured business-process automation.
On price, Sonnet 5 at $2/$10 intro and $3/$15 standard undercuts GPT-5.5 (priced at $5/$30 per Sol equivalent) and competes aggressively with Gemini 3.5 Flash, which is cheaper but delivers weaker performance on most coding and professional benchmarks. The full competitive coding model landscape including GPT-5.6 Sol, Terra, and Luna (launched four days after Sonnet 5) is covered in the GPT-5.6 Sol review on Build Fast with AI. GPT-5.6 Terra at $2.50/$15 and Luna at $1/$6 will be the more relevant competitive comparison for Sonnet 5 once those models reach general availability.
12. Availability, API, and Migration Guide
Where to Access Claude Sonnet 5
- claude.ai (Free and Pro plans): Sonnet 5 is the new default model from launch day. No action required for existing users.
- claude.ai (Max, Team, Enterprise): Available alongside Opus 4.8; you can select between models.
- Claude Code: Available immediately. Use /model sonnet in a session to switch to Sonnet 5.
- Claude Platform API: Use model string claude-sonnet-5. Live immediately.
- Amazon Bedrock: Available on launch day. Use the claude-sonnet-5 model ID.
- Google Vertex AI: Available on launch day. Note that Cyber Verification Program support on Vertex is coming soon, not live at launch.
- Microsoft Foundry: Available on launch day.
- Third-party integrations: Anthropic confirms Cursor, VS Code, and GitHub Copilot are live at launch.
Python API Quick Start
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-sonnet-5",
max_tokens=1024,
messages=[
{"role": "user", "content": "Find the race condition in worker.py and ship a tested fix."}
],
)
print(message.content[0].text)Migration from Sonnet 4.6
The one-line migration: change your model string from claude-sonnet-4-6 to claude-sonnet-5. Before doing this in production, test these three areas that have the highest risk of behavioral differences: prompts that rely on specific output format behavior (the new tokenizer can affect how the model parses structured inputs), edge cases in tool calling where prompt phrasing was tuned to Sonnet 4.6's specific behavior, and per-task cost baselines (benchmark real token consumption before assuming cost neutrality, since the 1.0 to 1.35x tokenizer multiplier is real and not uniform across content types). For most teams, the migration is safe to do immediately during the introductory pricing window. The safety improvement in prompt-injection resistance is especially valuable for teams running agentic pipelines in less controlled environments.
Frequently Asked Questions
What is Claude Sonnet 5 and when did it launch?
Claude Sonnet 5 is Anthropic's most agentic Sonnet model, launched June 30, 2026. It is the mid-tier model between Haiku 4.5 (fast and cheap) and Opus 4.8 (maximum capability) in Anthropic's lineup. It is the new default model for Free and Pro plans on claude.ai and is available via the Claude Platform API using the model string claude-sonnet-5.
How does Claude Sonnet 5 compare to Claude Opus 4.8?
Sonnet 5 scores 63.2% on SWE-bench Pro (Opus 4.8: 69.2%), 81.2% on OSWorld (Opus: 83.4%), 84.7% on BrowseComp (Opus: comparable), and 80.4% on Terminal-Bench 2.1 (Opus: 74.6%, SONNET 5 WINS). On GDPval-AA v2 knowledge work, Sonnet 5 also edges Opus 4.8 (1,618 vs 1,615 Elo). Opus 4.8 maintains a meaningful lead on SWE-bench Pro (6-point gap), USAMO mathematics (17-point gap), and remains the recommended choice for cybersecurity work. Sonnet 5 costs 40 to 60% less than Opus 4.8 at standard and introductory pricing respectively.
What is Claude Sonnet 5's pricing?
Introductory pricing through August 31, 2026 is $2 per million input tokens and $10 per million output tokens. Standard pricing from September 1, 2026 is $3 per million input tokens and $15 per million output tokens. Both standard and batch pricing apply: prompt cache reads at approximately 10% of input rate, and batch API requests at 50% off both sides. The 1M token context window and 128K output token limit are included at all pricing tiers.
Is Claude Sonnet 5 available for free?
Yes. Claude Sonnet 5 is the default model for Claude's Free plan on claude.ai. Free tier users have access to Sonnet 5 subject to standard message limits and rate controls. The introductory API pricing at $2/$10 per million tokens represents a significant cost reduction for paid API users and is available through August 31, 2026.
What is the Claude Sonnet 5 model ID for the API?
The API model string is claude-sonnet-5. Use this model ID in the Anthropic SDK, the Claude Platform API, Amazon Bedrock, Google Vertex AI, and Microsoft Foundry. The model was live on all platforms from June 30, 2026.
Does Claude Sonnet 5 replace Sonnet 4.6?
Yes, for new production deployments Sonnet 5 is the replacement for Sonnet 4.6. It is better than Sonnet 4.6 on every published benchmark. Sonnet 4.6 remains accessible via the API as claude-sonnet-4-6 for teams that need to maintain existing integrations, but Anthropic frames Sonnet 5 as the direct upgrade. The main migration consideration is the tokenizer change, which can produce up to 1.35x more tokens for the same input text.
What is the effort level system in Claude Sonnet 5?
Claude Sonnet 5 exposes five effort levels: low, medium, high, max, and x-high (extra high). Higher effort means the model allocates more thinking budget, producing more accurate results at higher token cost. At x-high effort, Sonnet 5 performs roughly in line with Opus 4.8 at medium-to-high effort on OSWorld and BrowseComp. The optimal economic operating point is medium effort, where Sonnet 5 provides the best cost efficiency. Running Sonnet 5 at x-high can cost more than Opus 4.8 at comparable accuracy, so effort tuning is now a primary cost lever for production teams.
Is Claude Sonnet 5 better than GPT-5.5?
On the benchmarks Anthropic published at launch: Sonnet 5 leads GPT-5.5 on SWE-bench Pro (63.2% vs 58.6%), OSWorld computer use (81.2% vs 78.7%), and GDPval-AA v2 knowledge work (+121 Elo). GPT-5.5 edges Sonnet 5 on Terminal-Bench 2.1 per Anthropic's cross-vendor table. All figures are Anthropic's own published numbers, not independent third-party verification. Note that GPT-5.6 (Sol, Terra, Luna) launched on June 26, 2026, and is a more relevant competitive comparison than GPT-5.5; GPT-5.6 benchmarks remain vendor-stated and unverified as of the Sonnet 5 launch.
What are the key safety improvements in Claude Sonnet 5?
Sonnet 5 shows better refusal of malicious requests in agentic contexts, improved resistance to prompt-injection attacks (especially in browser-use scenarios where attack success drops from 31.5% to 0.93% vs Opus 4.8 without safeguards), lower hallucination rates, lower sycophancy rates, and lower overall misaligned behavior scores on Anthropic's automated behavioral audit compared to Sonnet 4.6. It did not receive deliberate cybersecurity training and was never able to develop a working Firefox exploit in testing. Cyber safeguards are enabled by default via the Cyber Verification Program.
Recommended Blogs
- Claude AI Complete Hub: Every Anthropic Model and Product Update
- Claude Tag Review: Anthropic's AI Teammate Now Lives Inside Your Slack
- GLM-5.2 vs Claude Opus 4.8 vs GPT-5.6 vs Kimi: Best Coding AI (2026)
- GPT-5.6 Review: Sol, Terra, Luna Features, Benchmarks, and Pricing
- Best AI Models and Leaderboards: Cross-Model Rankings July 2026
- Agentic AI Launchpad 2026: Build Real AI Systems in 6 Weeks
Resources & Community
Join our community of 70,000+ AI enthusiasts and learn to build powerful AI applications! Whether you're a beginner or an experienced developer, Build Fast with AI helps you understand and implement AI in your projects.
- Website: buildfastwithai.com
- LinkedIn: Build Fast with AI
- Instagram: @buildfastwithai
- Founder Twitter: @satvikps
- Twitter: @BuildFastWithAI
Agentic AI Launchpad 2026
A structured 6-week cohort program that takes you from AI basics to building and deploying real-world agentic AI systems. Includes live sessions, expert mentorship, project reviews, and a builder community network.
Ready to go from learning to building? Join the next cohort: Agentic AI Launchpad 2026
Free AI Resources
Access free tools, workshops, and micro-learning to keep building:
- AI Workshops: Free resources, upcoming events and past recordings
- Unrot: Learn AI in 5 minutes a day (free micro-learning app)
Anthropic is shipping faster than ever in 2026. Follow @BuildFastWithAI on X to stay ahead of every model release, pricing change, and benchmark update that matters for builders and developers.
References
- Anthropic: Introducing Claude Sonnet 5 (official announcement, June 30, 2026)
- Anthropic: Claude Sonnet 5 System Card (full safety and benchmark evaluations)
- Codersera: Claude Sonnet 5 Benchmarks, Pricing and How It Compares
- DataCamp: Claude Sonnet 5: Features, Benchmarks, and Pricing
- Kingy AI: Claude Sonnet 5: Benchmarks, Specs, Pricing and Everything New
- MarkTechPost: Anthropic Claude Sonnet 5 vs Sonnet 4.6 vs Opus 4.8: Agentic Coding Benchmarks and Cost-Performance Tradeoffs Compared
- llm-stats.com: Claude Sonnet 5 vs Claude Opus 4.8: The Complete Comparison
- aimadetools.com: Claude Sonnet 5: Complete Guide to Benchmarks, Pricing, and Features (2026)
- modemguides.com: Claude Sonnet 5: Price, Benchmarks, and the Catch
coursiv.io: Claude Sonnet 5: Release Date, Pricing, API and Benchmarks

