




GLM-5V-Turbo: Z.ai's Vision Coding Model That Sees Your Code (2026)
I opened X this morning and the top post from Z.ai stopped me mid-scroll: they shipped a vision model that doesn't just understand code. It sees your screen, reads your design draft, watches your bug replay video, and then writes the code to fix it. That's a genuinely different product.
GLM-5V-Turbo is Z.ai's first native multimodal vision coding model, and it launched April 1, 2026. Not a gimmick, not a slight update. A full multimodal architecture built specifically for agentic engineering workflows, with deep integrations into OpenClaw and Claude Code.
The timing matters. Z.ai (formerly Zhipu AI) IPO'd on the Hong Kong Stock Exchange on January 8, 2026 at HK$116.20 per share, valuing the company at HK$52.83 billion. They now serve more than 12,000 enterprise customers and 45 million developers. This isn't a lab experiment. It's a production product from one of China's most serious AI companies.
Here's the full breakdown.
What Is GLM-5V-Turbo?
GLM-5V-Turbo is Z.ai's first native multimodal agent foundation model, built specifically for vision-based coding and agent-driven tasks. It natively handles image, video, and text inputs, and is designed to complete the full loop of perceive, plan, and execute.
That phrase matters. Most vision-language models stop at 'perceive.' They describe what they see. GLM-5V-Turbo is built to close the loop: see a UI mockup, plan the component structure, and execute the code. That's a harder problem, and it's what makes this launch worth paying attention to.
The model supports a 200K context window with a maximum output of 131,072 tokens. You can load extensive technical documentation, lengthy video recordings of software interactions, and full design systems into a single session without hitting limits.
Z.ai positions this as a specialist model, not a generalist. And I think that's the right call. Generalist models that can 'also do vision coding' almost always disappoint on the vision coding part.
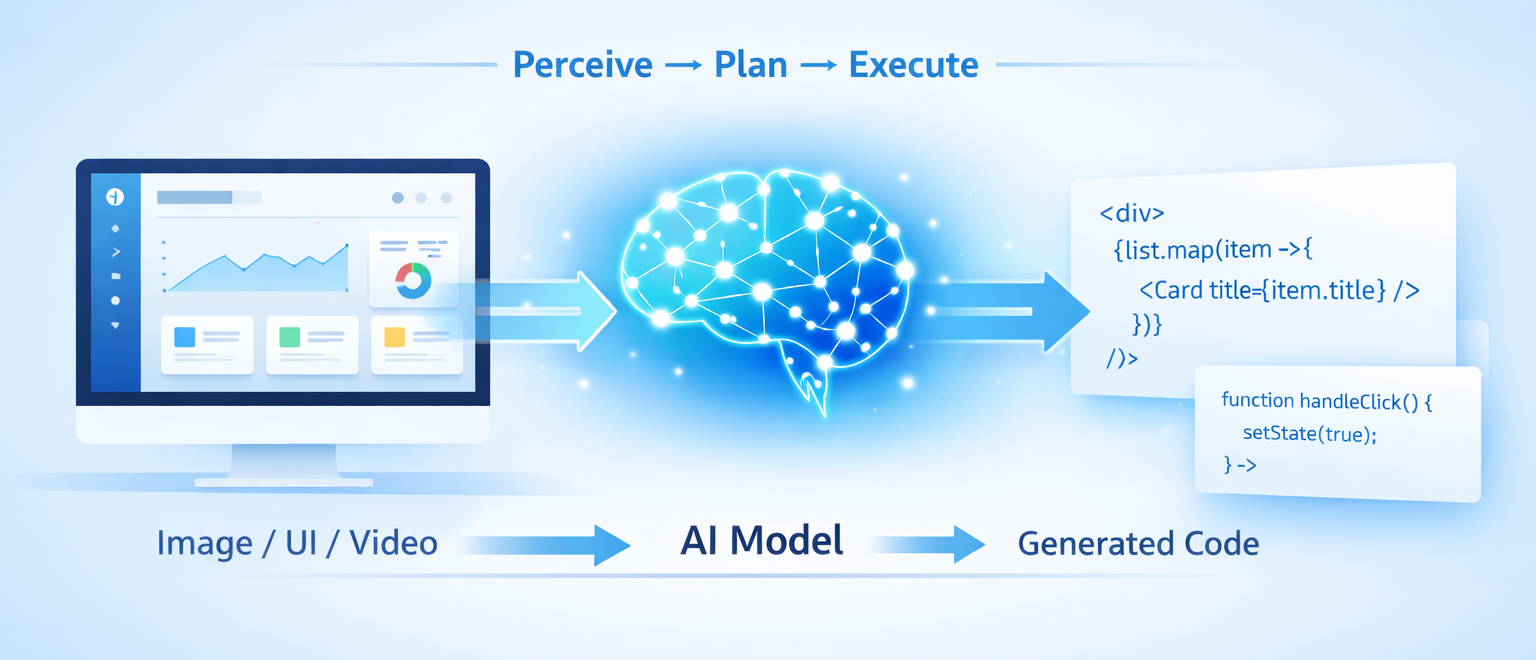
How the Architecture Actually Works
The core technical distinction is Native Multimodal Fusion. Here's what that means in plain terms.
Older vision-language models used a two-step pipeline: first, a vision encoder turned the image into a text description; then, a language model processed that text. The visual information was already degraded before the LLM ever saw it. Fine-grained spatial details, coordinate relationships, layout hierarchy -- all of that got flattened into words.
GLM-5V-Turbo treats multimodal inputs as primary data during training. Images, videos, design drafts, and document layouts are trained on natively, not converted. Two specific architectural choices make this possible:
- CogViT Vision Encoder:
- Processes visual inputs while preserving spatial hierarchies and fine-grained visual details. This is what lets the model identify exact coordinates of UI elements rather than just describing them vaguely.
- MTP (Multi-Token Prediction) Architecture:
- Improves inference efficiency and reasoning, which is critical when outputting long code sequences or navigating complex GUI environments. You want fast, reliable token generation when debugging a production system at 2am.
The 200K context window isn't a marketing number. For agentic engineering workflows, you regularly need to load design specs, existing code, error logs, and video transcripts simultaneously. GLM-5V-Turbo's architecture was built to hold all of that at once.
The 30+ Task RL Training That Solves the See-Saw Problem
The 'see-saw' effect is the most persistent unsolved problem in vision-language model development. Improve the model's visual recognition, and its programming logic degrades. Improve the coding ability, and visual understanding suffers. Most VLMs live somewhere in this uncomfortable middle.
Z.ai's approach: train across 30+ tasks simultaneously using Joint Reinforcement Learning. The model doesn't optimize for one capability at a time. It maintains balance across all of them concurrently.
The tasks span four domains that matter for engineering specifically:
- STEM Reasoning -- maintaining the logical and mathematical foundations required for code
- Visual Grounding -- precisely identifying coordinates and properties of UI elements
- Video Analysis -- interpreting temporal changes, essential for debugging animations and user flows
- Tool Use -- enabling the model to interact with external APIs and software tools
The result is a model that doesn't trade off visual ability for code quality. This is particularly relevant for GUI agents that must see a graphical interface and generate the code or commands to interact with it.
My hot take: joint RL training across 30+ tasks is the most interesting technical detail of this launch. Most labs solve the see-saw problem by just... accepting one side of the tradeoff. Z.ai actually built infrastructure to fight it. Whether the fix holds up at scale will be the question.
OpenClaw and Claude Code: The Deep Integrations
GLM-5V-Turbo isn't a general-purpose model with optional tool support bolted on. It was built for deep adaptation inside two specific agentic ecosystems: OpenClaw and Claude Code.
Why OpenClaw Integration Matters
OpenClaw is an open-source framework for building agents that operate within graphical user interfaces. As I broke down in depth in our post on GLM-5-Turbo's OpenClaw integration, the share of skills in OpenClaw workflows has risen from 26% to 45% in recent months. That growth is exactly why a specialized vision model for OpenClaw makes commercial sense.
GLM-5V-Turbo handles environment deployment, development, and analysis within OpenClaw workflows. Its ability to process design drafts and document layouts is used to automate the setup and manipulation of software environments. You give it a screenshot of the current state, a design doc for the target state, and it plans the execution path.
Claude Code Workflows
The integration with Claude Code is specifically useful for what Z.ai calls 'Claw Scenarios.' A developer provides a screenshot of a bug, or a Figma mockup of a new feature, and GLM-5V-Turbo interprets the visual layout and generates code grounded in the visual evidence. No verbal description required.
This is the workflow I'm most excited about personally. I've spent years translating design screenshots into written specifications before any code gets written. Having a model that reads the screenshot directly and writes the code skips an entire cognitive step that introduces error every single time it happens.
If you've already been running Claude Code in your workflow (I wrote a full breakdown in our Claude Code vs Codex 2026 comparison), GLM-5V-Turbo slots into that ecosystem as the visual perception layer.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Benchmarks: CC-Bench-V2, ZClawBench, and ClawEval
Three benchmarks are central to evaluating GLM-5V-Turbo's performance:

I want to flag something here: ZClawBench and ClawEval are Z.ai's own benchmarks. Self-reported benchmark performance from any AI lab should be treated with appropriate skepticism until external validation happens. That said, Z.ai has a track record worth noting. The GLM-5 base model scored 77.8% on SWE-bench Verified externally, the highest of any open-source model. They have historically backed up their internal numbers.
The more interesting benchmark comparison is how the broader GLM-5 family positions against frontier models. GLM-5.1 (the coding-focused sibling) reached 94.6% of Claude Opus 4.6's score on Z.ai's coding eval, while GLM-5 scored 62.0 on BrowseComp compared to Claude Opus 4.5's 37.0. Context: the BrowseComp gap is significant for web-navigation tasks. For pure vision coding, GLM-5V-Turbo is the specialized answer.
Pricing and API Access
GLM-5V-Turbo is available through Z.ai's API and on OpenRouter with straightforward pricing:
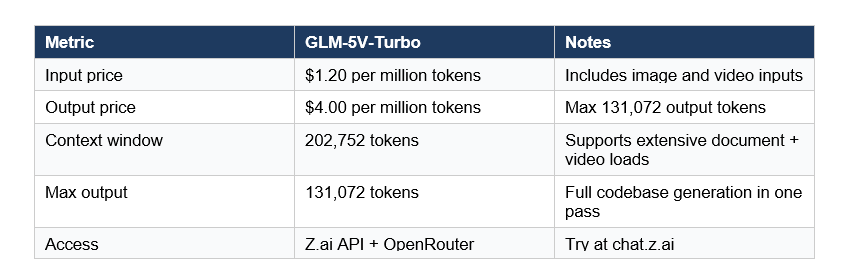
Z.ai also runs a GLM Coding Plan with subscription pricing starting at roughly $9/month. Pro subscribers get early access to new models. If you're running the GLM Coding Plan primarily for text coding tasks, GLM-5V-Turbo adds vision capability without a separate setup.
For comparison: Claude Opus 4.6 charges $5/$25 per million input/output tokens. At $1.20/$4.00, GLM-5V-Turbo is approximately 4x cheaper on input and 6x cheaper on output. For vision-intensive agentic workflows where you're processing many screenshots or design files, that cost gap compounds quickly.
GLM-5V-Turbo vs Other Vision Coding Models
The honest comparison here is harder than it sounds, because 'vision coding model' is a new enough category that direct competitors are limited. Let me be specific about what I'm actually comparing.
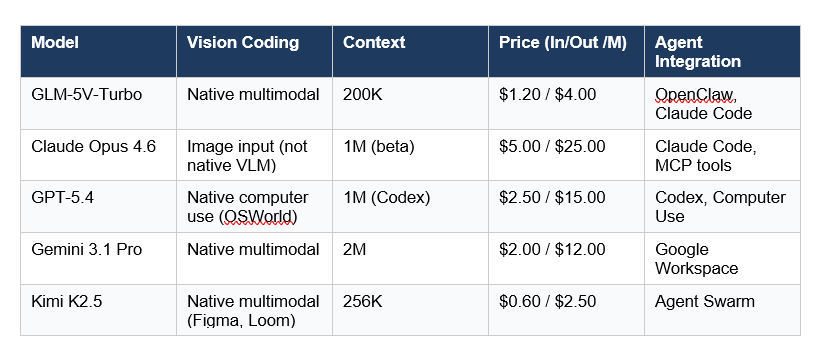
A few things stand out. First, GLM-5V-Turbo is the only model in this list purpose-built specifically for vision coding in agentic workflows. GPT-5.4's computer use is impressive but general; Gemini's multimodal is strong but not coding-focused. Second, the price-to-capability ratio for vision coding tasks specifically is where GLM-5V-Turbo wins.
The Kimi K2.5 comparison is worth noting separately. Kimi's native multimodal approach is similar -- I covered it in our Kimi K2.5 review vs Claude for coding. But GLM-5V-Turbo has the OpenClaw integration advantage for teams already in that ecosystem. And GLM-5V-Turbo's CogViT encoder is specifically tuned for spatial accuracy in GUI tasks, not just general visual understanding.
Contrarian take: the model to actually worry about is the one nobody's comparing against. DeepSeek V4's multimodal architecture is coming, and that price point ($0.28/M input) will make every other comparison irrelevant if the vision coding quality holds up.
Who Should Actually Use GLM-5V-Turbo?
Not everyone. Let me be direct about this.
GLM-5V-Turbo is the right choice if you're building or running agentic workflows that involve visual input -- design-to-code, GUI automation, screenshot-based debugging, or video-grounded development. If your coding workflow is entirely text-based, GLM-5 or GLM-5.1 will serve you better and cost less.
Specifically, I'd recommend testing GLM-5V-Turbo if:
- You're building OpenClaw agents and need the model optimized for that execution environment
- You regularly hand off Figma mockups, design drafts, or UI screenshots to an AI for code generation
- You're debugging visually -- sending error screenshots or bug replay recordings to an AI
- You need 200K context for large documentation plus visual inputs in a single session
- You're already using the GLM Coding Plan and want to add vision capability without a new integration
If you want to explore the broader GLM ecosystem and how it fits against Claude alternatives, I walked through the full picture in our GLM OCR vs GLM-5-Turbo comparison and the GLM-5.1 review vs Claude Opus 4.6.
Want to learn how to build AI agents that use vision models like GLM-5V-Turbo?
Join Build Fast with AI's Gen AI Launchpad -- an 8-week structured program to go
from 0 to 1 in Generative AI.
Register here
Frequently Asked Questions
What is GLM-5V-Turbo?
GLM-5V-Turbo is Z.ai's first native multimodal vision coding model, launched April 1, 2026. It handles image, video, and text inputs natively using a CogViT Vision Encoder and MTP architecture, and is built specifically for agentic engineering workflows in OpenClaw and Claude Code environments. Context window: 200K tokens. Max output: 131,072 tokens.
What is the difference between a GLM and an LLM?
LLM stands for Large Language Model -- any large-scale AI model trained primarily on text. GLM (General Language Model) is Z.ai's specific model family, originating from Tsinghua University research. GLM-5V-Turbo extends the GLM family into vision-language territory by adding native multimodal training, making it a VLM (Vision-Language Model) rather than a text-only LLM.
How much does GLM-5V-Turbo cost?
GLM-5V-Turbo costs $1.20 per million input tokens and $4.00 per million output tokens on OpenRouter as of April 2026. The context window is 202,752 tokens with up to 131,072 output tokens per response. Z.ai also offers GLM Coding Plan subscriptions starting at approximately $9/month for developers who want plan-based access.
What is OpenClaw and why does GLM-5V-Turbo support it?
OpenClaw is an open-source framework for building AI agents that operate within graphical user interfaces. The share of skills in OpenClaw workflows has grown from 26% to 45% in recent months. GLM-5V-Turbo was specifically aligned during training on OpenClaw task patterns, meaning its tool-calling behavior, visual grounding, and multi-step execution are tuned for that environment.
What benchmarks does GLM-5V-Turbo use?
The three primary benchmarks are CC-Bench-V2 (multimodal coding across backend, frontend, and repo-level tasks), ZClawBench (agent performance in OpenClaw-specific scenarios), and ClawEval (multi-step execution and environment interaction). Note that ZClawBench and ClawEval are Z.ai's proprietary benchmarks; independent validation on these specific evals has not yet been published as of April 2026.
How does GLM-5V-Turbo compare to GPT-4V or Claude for vision coding?
GPT-5.4 offers computer use via OSWorld scoring 75%, but this is general computer control rather than specialized vision coding. Claude Opus 4.6 accepts image inputs but is not a native VLM trained from scratch on multimodal data. GLM-5V-Turbo is purpose-built for vision coding with the CogViT encoder trained natively, OpenClaw integration, and a price point of $1.20/$4.00 per million tokens versus Claude's $5/$25.
What is the see-saw effect in vision AI models?
The see-saw effect is the performance trade-off in vision-language models where improving visual recognition causes programming logic quality to degrade, and vice versa. GLM-5V-Turbo addresses this through 30+ Task Joint Reinforcement Learning, simultaneously optimizing across STEM reasoning, visual grounding, video analysis, and tool use rather than optimizing each capability independently.
Is GLM-5V-Turbo open-source?
GLM-5V-Turbo itself is a proprietary API model as of April 2026. The GLM-5 base model (the text-only foundation) is available open-source under the MIT License on Hugging Face at zai-org/GLM-5. Z.ai has not announced an open-source release timeline for the vision model variant.
Recommended Reads
If you found this useful, these posts from Build Fast with AI go deeper on related topics:
GLM OCR vs GLM-5-Turbo: Which AI Model Should You Use? (2026)
Build AI Agents with OpenClaw + Kimi K2.5: Full Guide (2026)
References
- Z.ai Launches GLM-5V-Turbo -- MarkTechPost (April 2026)
- Z.ai Official X Announcement -- @Zai_org (April 2026)
- GLM 5V Turbo -- API Pricing & Providers -- OpenRouter
- Z.ai Developer Documentation -- New Released
- Z.ai Debuts GLM-5 Turbo for Agents -- VentureBeat
- Z.ai Wikipedia -- Company Overview
- zai-org/GLM-5 -- Hugging Face Model Card

