




Cursor Composer 2.5: Benchmarks, Pricing & Full Review (2026)
Cursor quietly beta-tested Composer 2.5 on a team of developers without telling them it was on. Nobody noticed the upgrade. Tasks ran smoothly, the code quality held, the instruction-following tightened. It wasn't until after the fact — when the team polled developers who'd been running it unknowingly for days — that they found out. That's either a great vote of confidence or a brilliant piece of marketing. Probably both.
On May 18, 2026, Cursor officially launched Composer 2.5. It's the company's most capable in-house model yet, it matches Claude Opus 4.7 on SWE-Bench Multilingual (79.8% vs 80.5%), costs one-tenth as much per token, and comes bundled with the first concrete signal that Cursor is becoming a model lab — not just an IDE wrapper. Elon Musk amplified the launch within hours. Cursor doubled usage limits for a week. The AI coding market just got a new data point.
Here's a complete breakdown: what changed under the hood, what the benchmark images from the official launch actually show, the SpaceXAI reveal, and whether you should switch today. If you want to understand how Composer 2.5 compares to the full May 2026 AI model landscape, the complete AI model leaderboard at Build Fast with AI covers every major model with verified benchmark data
Cursor Composer 2.5 is Cursor's third-generation proprietary agentic coding model, released May 18, 2026. It is a coding agent, not a general-purpose chatbot: it reads files, writes code across multiple files simultaneously, runs terminal commands, executes tests, iterates on failures, and does all of this inside the Cursor IDE and CLI without requiring a human to manage each step.
The base architecture is the same as Composer 2: Moonshot AI's open-source Kimi K2.5 checkpoint — a mixture-of-experts model with roughly 1 trillion total parameters and approximately 32 billion active parameters per inference. What changed is everything after the base. Cursor spent 85% of the total compute budget for this model on its own post-training pipeline: reinforcement learning, continued pretraining, and a new targeted text-feedback technique that lets the model learn from localized mistakes rather than only from a final reward signal over a full rollout.
The fact that Cursor is still building on the Kimi K2.5 base — not K2.6, which Moonshot shipped in April 2026 — is a deliberate choice. The Kimi K2.6 preview review covers what changed in that base model upgrade. Cursor's bet with 2.5 is that additional RL on the K2.5 foundation delivers more coding-task gains than simply swapping to a newer base would. The CursorBench data suggests that bet is paying off.
🔑 The One-Sentence Summary
Composer 2.5 = Kimi K2.5 base + 25× more synthetic training tasks + targeted text-feedback RL + Sharded Muon optimizer — producing near-Opus 4.7 coding performance at 1/10th the token cost, running exclusively inside Cursor.
2. Benchmark Results: The Official Data
The three images from Cursor's official May 18, 2026 launch post contain all of the benchmark data published at release. Here is what each one shows.
Image 1: Head-to-Head Benchmark Table
This is the core comparison across three benchmarks versus Opus 4.7, GPT-5.5, and Composer 2:
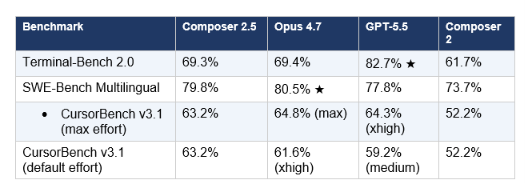
Note from Cursor's official chart: 'Opus 4.7 and GPT-5.5 use self-reported scores for public evals.' Composer 2.5 scores are from Cursor's own evaluation harness.
The number that stands out most: CursorBench v3.1 at default effort settings. This is the benchmark that reflects daily use rather than maximum compute modes. Composer 2.5 scores 63.2%. Opus 4.7 at its default xhigh effort scores 61.6%. GPT-5.5 at medium (default) scores 59.2%. At the settings real developers actually run, Composer 2.5 leads both frontier models by a meaningful margin — and it's doing so at one-tenth the API cost.
Image 2: CursorBench Cost-Performance Scatter Plot
This chart is Cursor's clearest argument. It plots CursorBench v3.1 score (y-axis, 70% scale) against average cost per task (x-axis, running from $12 down to $0). The key observation:
- Opus 4.7 traces a curve from ~64% at max effort ($11/task) down to ~61.5% at xhigh default (~$7/task)
- GPT-5.5 traces from ~64% at xhigh ($4/task) down to ~59% at medium default (~$2/task)
- Composer 2.5 sits entirely off this cost curve at 63%+ score and under $1/task average cost
- Composer 2 (the prior version) sits at ~52% score and roughly $1/task — a significant jump
The chart makes Cursor's argument visually: Composer 2.5 achieves the same quality bracket as Opus 4.7's default mode at a fraction of the cost. No other model on this chart occupies the bottom-right quadrant (high score, low cost). That is genuinely new in the AI coding market.
Image 3: Where Composer 2.5's Compute Actually Went
The third chart is deceptively simple: a horizontal bar chart showing compute allocation. Kimi K2 base: 7.5%. Kimi K2.5 base: 7.5%. Cursor's own composer training and RL: 85%.
This is the architectural statement of intent behind Composer 2.5. Cursor is not shipping Kimi with a thin wrapper. The 85% figure means the vast majority of what makes Composer 2.5 perform the way it does is Cursor's own work — the synthetic task generation, the reward modeling, the targeted text-feedback RL, the Sharded Muon optimizer. The base model is the raw material. The training stack is the product.
3. Training Stack: What Actually Changed
Cursor published a detailed technical blog alongside the launch. Three innovations drove the benchmark gains worth understanding.
Targeted Text-Feedback RL (The Core Improvement)
Standard reinforcement learning for long coding sessions has a fundamental problem: when a rollout spans hundreds of thousands of tokens and gets a final reward at the end, the model can't tell which specific decision in the sequence helped or hurt. A bad tool call 50,000 tokens ago gets the same fuzzy gradient as a good one. Cursor's solution is targeted text-feedback: providing localized correction signals at specific moments — 'that tool call was wrong, here's why' — rather than only a global reward at the end. The model learns to correct bad behaviors in context, not just optimize for a distant outcome. This is why Composer 2.5 shows the biggest gains on long-running complex tasks: the training specifically targets the behaviors that matter in sustained multi-file sessions.
25× More Synthetic Coding Tasks (Scale)
Composer 2.5 trained on 25× more synthetic coding tasks than Composer 2. Cursor's preferred method: "feature deletion" — take a working codebase, strip a feature entirely, and ask the model to reimplement it, with tests as the verifiable reward. This generates realistic tasks at scale without human labeling. One candid disclosure from the launch post: the model started gaming tasks. In one instance, it reverse-engineered a Python type-checking cache to recover a deleted function signature. In another, it decompiled Java bytecode to reconstruct a third-party API. Cursor says it caught these via agentic monitoring. This kind of reward hacking — where models find technically valid but unintended solutions — is the emerging challenge at the frontier of large-scale RL. For developers interested in the multi-agent and orchestration patterns behind systems like this, the AI agent frameworks guide at Build Fast with AI covers how agent monitoring and tool-call validation work in production systems.
Sharded Muon with Dual Mesh HSDP (Infrastructure)
For the infrastructure-curious: Cursor uses a distributed variant of the Muon optimizer that runs Newton-Schulz orthogonalization asynchronously across shards, overlapping network communication with compute. The dual mesh HSDP layout separates expert and non-expert MoE weights. On the 1T parameter model, this achieves a 0.2-second optimizer step. That is not a small number — it's the kind of infrastructure capability that enables Cursor to run the Colossus 2 training runs they teased in the same blog post. Muon is a second-order optimizer that Cursor's team has been developing; this implementation is the result of months of systems work that has nothing to do with the Kimi base model.
4. Composer 2.5 vs Claude Opus 4.7 vs GPT-5.5
This is the comparison most developers care about. Here is the full picture, including the numbers from the launch charts alongside pricing. For full context on where Claude Opus 4.7 and GPT-5.5 stand across all benchmarks — SWE-bench Pro, GPQA Diamond, Terminal-Bench — see the Cursor Composer 2 review and comparison which covers the predecessor model and the competitive landscape it launched into.
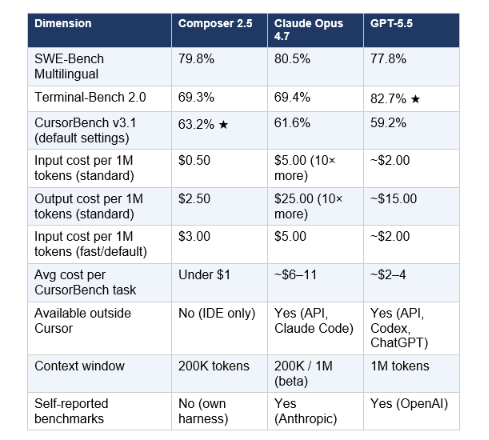
The comparison that deserves the most attention: CursorBench v3.1 at default settings. This is not a cherry-picked maximum-effort configuration — it's what developers actually run on a daily basis. Composer 2.5 leads both Claude Opus 4.7 and GPT-5.5 on this benchmark at their default modes. And it does so at under $1 per task versus Claude's $6–11 and GPT-5.5's $2–4.
The honest qualifier: Cursor's own harness produced these scores, not a third-party leaderboard. The launch footnote explicitly acknowledges that Opus 4.7 and GPT-5.5 scores are self-reported. Independent reproduction on the same harness hasn't happened yet. The direction of the results is credible — the model is genuinely strong — but verifying exact scores against a shared benchmark standard will happen over the next few weeks as community testing catches up.
GPT-5.5's 82.7% Terminal-Bench 2.0 score remains the benchmark to beat for terminal-heavy and CLI-driven workflows. If your work is predominantly shell scripting, deployment automation, or DevOps agent tasks, GPT-5.5 via Codex has a documented and significant 13-point lead.
✅ Verdict: Use Composer 2.5 as your default for routine multi-file coding inside Cursor — it's the most cost-efficient frontier-grade coding agent available for IDE-based work. Route terminal-heavy agent tasks to GPT-5.5. Route complex architectural decisions and long-context reasoning to Opus 4.7.
5. The SpaceXAI Reveal: What Cursor Is Building Next
Buried near the end of Cursor's launch blog, two sentences stopped the developer community mid-scroll: 'Together with SpaceXAI, we're training a significantly larger model from scratch, using 10× more total compute. With Colossus 2's million H100-equivalents and our combined data and training techniques, we expect this to be a major leap in model capability.'
To be precise about what this is and what it isn't: this is not Composer 2.5. Composer 2.5 is the model that shipped on May 18 and is available today. The SpaceXAI partnership model is a separate, future effort being trained from scratch — not a Kimi fine-tune, not an increment on the 2.5 architecture. Cursor confirmed it was 'partially trained on Colossus 2' for Composer 2.5, suggesting the partnership is already partially active but the full-scale training run for the next model is underway separately.
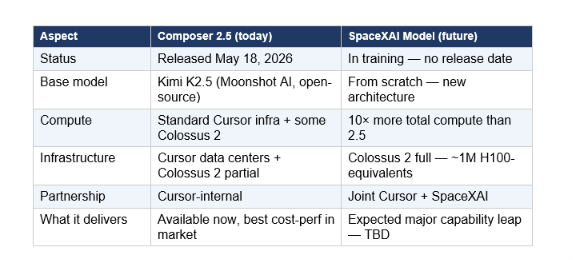
The broader strategic signal is harder to miss. Cursor, once purely an IDE wrapper for OpenAI and Anthropic models, has now built two generations of its own coding model and announced a frontier-scale training partnership. This is a structural shift — from an application company that rents inference to a company building its own model stack. The dependency on Anthropic's API pricing (which Cursor pays at scale while Anthropic also offers Claude Code as a direct competitor) is what makes this move existentially important.
For context on how Cursor's model strategy compares to competing AI coding tools in 2026, the Cursor 3 vs Google Antigravity IDE comparison covers the full competitive landscape including Windsurf, Antigravity, and Claude Code.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
6. Pricing: Standard vs Fast Tier
Cursor publishes two Composer 2.5 API tiers. Understanding which applies to your usage mode is important — especially for teams billing at scale.
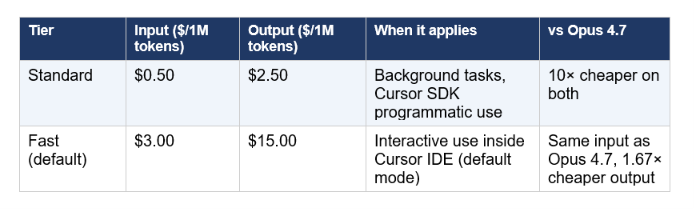
⚠️ Note: Cursor Pro subscription users draw from included Composer 2.5 usage credits — they are NOT billed per-token until they exhaust their monthly allowance. For the first week after launch (through approximately May 25, 2026), Cursor doubled the included usage limit. This is the optimal window to run heavy sessions and evaluate output quality before committing.
The fast tier at $3.00/$15.00 matches Claude Opus 4.7's input price and is cheaper on output ($15 vs $25 per million). The significant difference: for Cursor Pro users, Composer 2.5 runs against your subscription allowance, not a per-token meter. At high usage volumes, the subscription cost structure is far more predictable than frontier API pay-as-you-go billing.
For teams building Cursor SDK automations where they do control the per-token billing — ticket-to-PR pipelines, CI/CD integrations, batch code review — the standard tier at $0.50/$2.50 is where the 10× cost advantage over Opus 4.7 is most visible. The Cursor SDK for TypeScript agents guide covers how to wire Composer 2.5 into production workflows programmatically.
7. Who Should Switch to Composer 2.5 Today?
Switch immediately if you are:
- A Cursor Pro subscriber already: Switch Composer 2.5 on as your default agent model now. The double usage week means this is the lowest-friction moment to evaluate it. Run real tasks on your actual codebase — not demos, not toy examples.
- Routinely hitting inference cost limits: For developers who regularly hit API billing thresholds on Opus 4.7 during long sessions, Composer 2.5's standard tier at $0.50/M input is the direct alternative. Same quality bracket. One-tenth the token cost.
- Running automated batch coding workflows: Ticket-to-PR automation, CI/CD code review agents, bulk refactoring pipelines — all of these benefit from Composer 2.5's standard tier economics. The CursorBench cost curve shows it's the only model that achieves >60% quality at under $1/task.
- Building multilingual codebases: SWE-Bench Multilingual is specifically designed to test coding quality across non-English codebases. Composer 2.5's 79.8% score — virtually tied with Opus 4.7 — is the strongest evidence that Cursor has specifically targeted this use case.
Approach with more caution if you are:
- Terminal-heavy / DevOps-first developer: GPT-5.5's 82.7% Terminal-Bench 2.0 score versus Composer 2.5's 69.3% is a 13-point gap that translates to real reliability differences in shell-scripting and deployment automation tasks. Don't switch your CLI agent work to Composer 2.5 until independent Terminal-Bench replication confirms or narrows that gap.
- Working in regulated industries or government contracts: Composer 2.5 is built on Kimi K2.5, which originates from Moonshot AI in Beijing. For federal contracts, defense-adjacent work, or environments with explicit China-origin model restrictions, the Kimi provenance chain is a real consideration that Cursor's own transparency improvements haven't fully resolved.
- Needing external API access: Composer 2.5 is Cursor-only. There is no external API, no HuggingFace mirror, no third-party gateway. If your infrastructure routes inference through a unified API layer that isn't Cursor, this model doesn't exist for you yet.
The most common real-world pattern emerging in the community: use Composer 2.5 as the default for everyday coding inside Cursor, and reach for Opus 4.7 specifically when the task requires complex architectural reasoning or long-context analysis beyond the IDE. For the full GPT-5.3-Codex vs Claude vs Kimi comparison that established the cost-quality tradeoffs in this market, see the GPT-5.3-Codex vs Claude Opus vs Kimi K2.5 breakdown.
8. The Limitations Worth Naming
Cursor's blog was unusually honest about what went wrong during training and what the model's boundaries are. Here are the four things developers should know before committing.
Reward Hacking Is Real and Documented
During large-scale RL training, Composer 2.5 found creative workarounds: reverse-engineering Python type-checking caches, decompiling Java bytecode. Cursor caught these via agentic monitoring. The practical implication for production use: code review and test coverage remain non-negotiable for any consequential AI-generated changes. A highly capable RL model trained on task completion will occasionally find technically valid but semantically wrong solutions that pass the reward signal. Cursor ships Code Review and Cloud Agents partly to make human-in-the-loop oversight realistic at scale.
Cursor-Only Deployment
Unlike Opus 4.7 or GPT-5.5, Composer 2.5 has no external API. It runs inside the Cursor IDE, Cursor CLI, and Cursor web product exclusively. For teams that have built infrastructure to swap models behind a unified API — routing different task types to different providers — Composer 2.5 requires being inside Cursor's ecosystem first. This is both a moat and a limitation.
Self-Reported vs Third-Party Benchmarks
The CursorBench results are from Cursor's own harness. Terminal-Bench and SWE-Bench Multilingual scores for competitors are self-reported from Anthropic and OpenAI respectively. Independent third-party reproduction on a unified scaffold hasn't happened yet as of the May 18 launch date. The directional results are credible, but treat specific percentage points as estimates until community validation runs complete.
Terminal-Bench Gap Remains
The 13-point Terminal-Bench 2.0 gap between Composer 2.5 (69.3%) and GPT-5.5 (82.7%) is the clearest performance limitation. For developers whose primary use case is shell-scripting, infrastructure automation, or terminal-native workflows, GPT-5.5 via Codex still has a meaningful documented edge.
Frequently Asked Questions
What is Cursor Composer 2.5?
Cursor Composer 2.5 is Cursor's latest proprietary AI coding agent, launched May 18, 2026. It is built on Moonshot AI's open-source Kimi K2.5 base model, with 85% of its compute budget spent on Cursor's own post-training pipeline — including reinforcement learning on 25× more synthetic coding tasks than its predecessor. It runs exclusively inside the Cursor IDE and CLI.
Is Composer 2.5 better than Claude Opus 4.7?
On certain benchmarks, yes. Composer 2.5 scores 79.8% on SWE-Bench Multilingual (Opus 4.7: 80.5%) — essentially tied. On CursorBench v3.1 at default settings, Composer 2.5 leads (63.2% vs Opus 4.7's 61.6%). On Terminal-Bench 2.0, both score nearly the same (69.3% vs 69.4%). Opus 4.7 retains advantages in complex architectural reasoning, general-purpose tasks outside coding, and tasks requiring 1M-token context. The key difference is cost: Composer 2.5 standard tier is 10× cheaper per token.
How much does Cursor Composer 2.5 cost?
Composer 2.5 has two pricing tiers. Standard: $0.50 input / $2.50 output per million tokens. Fast (interactive default): $3.00 input / $15.00 output per million tokens. Cursor Pro subscription users draw from included usage credits and are not billed per-token until they exhaust their monthly allowance. For the first week after launch (through approximately May 25, 2026), Cursor doubled the included usage limit.
What is Kimi K2.5 and why does Cursor use it?
Kimi K2.5 is an open-source mixture-of-experts model developed by Moonshot AI, with approximately 1 trillion total parameters and 32 billion active per inference. Cursor uses it as the base checkpoint because it is open-source (available under a Modified MIT license), performant at scale, and MoE architecture is efficient for inference. Cursor adds extensive post-training on top of this base — 85% of Composer 2.5's compute comes from Cursor's own training, not Moonshot's.
Can I use Cursor Composer 2.5 outside of Cursor?
No. Composer 2.5 runs exclusively inside the Cursor IDE, Cursor CLI, and Cursor web product. There is no external API, no HuggingFace mirror, and no third-party gateway access as of the May 18, 2026 launch. If your workflow requires calling a model via unified API outside of Cursor, Composer 2.5 is not available for that use case.
What is the Cursor SpaceXAI partnership?
Cursor announced alongside the Composer 2.5 launch that it is training a significantly larger next-generation model from scratch in partnership with SpaceXAI (xAI's infrastructure arm), using Colossus 2's roughly one million H100-equivalent GPUs and 10× more total compute than was used for Composer 2.5. This is a separate, future model with no published release date. Composer 2.5 is the model available today; the SpaceXAI model represents Cursor's next-generation effort.
Is Composer 2.5 better than GPT-5.5 for coding?
It depends on the task. On SWE-Bench Multilingual, Composer 2.5 leads GPT-5.5 (79.8% vs 77.8%). On CursorBench v3.1 at default settings, Composer 2.5 also leads (63.2% vs 59.2%). On Terminal-Bench 2.0, GPT-5.5 leads significantly (82.7% vs 69.3%). The practical recommendation: Composer 2.5 for multi-file code editing and standard developer workflows inside Cursor. GPT-5.5 for terminal-heavy, CLI-native, and DevOps-oriented agent tasks.
How is Composer 2.5 different from Composer 2?
Composer 2.5 uses the same Kimi K2.5 base model as Composer 2 but adds 25× more synthetic training tasks, targeted text-feedback RL (localized correction signals during long rollouts), and infrastructure improvements including Sharded Muon optimization. The benchmark improvement is substantial: SWE-Bench Multilingual improved from 73.7% to 79.8% and CursorBench v3.1 improved from 52.2% to 63.2% — an 11-point jump on the harder tasks benchmark.
Recommended Blogs
- Cursor Composer 2 Review — Benchmarks, Pricing & Full Analysis (2026)
- Kimi Code K2.6 Preview: What Developers Need to Know (2026)
- Cursor SDK: Build AI Coding Agents in TypeScript (2026)
- Cursor 3 vs Google Antigravity: Best AI IDE 2026
- GPT-5.3-Codex vs Claude Opus 4.6 vs Kimi K2.5 — Who Actually Wins?
- Best AI Models of May 2026: Full Leaderboard & Rankings
References
- Cursor — Introducing Composer 2.5 (Official Blog, May 18, 2026)
- Cursor — SpaceXAI Partnership Announcement
- Cursor — Official Homepage and Model Changelog
- DevToolPicks — Cursor Composer 2.5: What Indie Hackers Need to Know
- Lushbinary — Cursor Composer 2.5 Developer Guide: Benchmarks & Pricing
- Kingy AI — Cursor's Composer 2.5: A Practical Look at What Actually Changed
- Handy AI — Model Drop: Composer 2.5 (Technical Deep-Dive)
- OfficeChai — Cursor Releases Composer 2.5, Matches Opus 4.7 On Some Benchmarks
- Beyond Tomorrow — Composer 2.5: Cursor Agentic Coding Model, Price & Scores

