




Attention Mechanism in LLMs Explained (2026): Self-Attention, Flash Attention 4, and Beyond
A paper published in 2017 has now been cited over 173,000 times. That paper is "Attention Is All You Need," and I'd argue it is the single most consequential piece of machine learning research in the last decade. Not because it discovered something radically new. But because it replaced an entire class of neural network architectures, RNNs and LSTMs, with one elegant operation: attention.
Every model you use today, GPT-4, Claude, Gemini, Llama 3, Mistral, DeepSeek, runs on the architecture that paper introduced. The Transformer. And at the center of every Transformer sits the attention mechanism.
Here's what I find interesting: the same mechanism that makes these models so smart is also what makes them so expensive. Standard attention scales quadratically with sequence length. Double your context window and you quadruple your compute costs. This one mathematical fact has driven billions of dollars of engineering work since 2022.
This guide breaks it all down: from how attention actually works at the math level, through multi-head attention, all the way to Flash Attention 4 achieving 1,605 TFLOPs/s on NVIDIA Blackwell GPUs in March 2026. No hand-waving. Actual specifics.
What Is the Attention Mechanism in Deep Learning?
The attention mechanism is a technique that lets a neural network selectively focus on the most relevant parts of an input sequence when producing each output. Instead of treating every word equally, the model learns which words matter most for each prediction.
Before attention existed, recurrent neural networks (RNNs) processed sequences token by token, left to right. The problem: by the time you got to token 512, the model had mostly forgotten token 1. Attention solved this by allowing every token to look at every other token simultaneously, at every layer of the network.
The key insight: relevance is learned, not hardcoded. The model figures out, through training, which relationships matter for which tasks.
In NLP, attention appeared first as an add-on to RNNs (Bahdanau attention, 2014). The Transformer paper made it the entire architecture. That shift is why every major LLM today is a Transformer and not an RNN.
I'd put it this way: attention gave neural networks something like working memory. Not perfect memory. Not infinite memory. But context-aware, task-sensitive memory that scales to thousands of tokens at once.
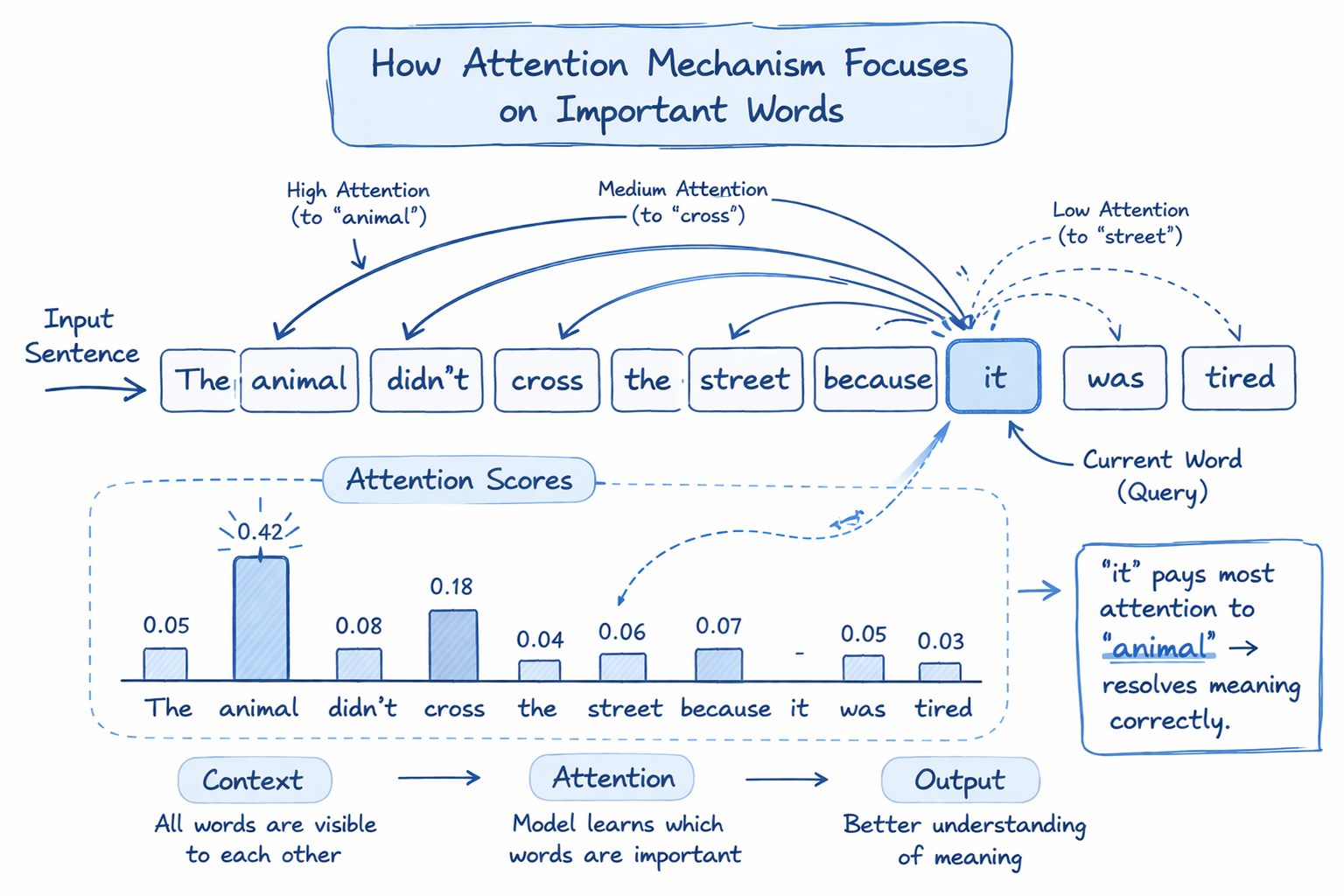
How Self-Attention Works in Transformers (Step by Step)
Self-attention is the specific flavor of attention used inside Transformer models. "Self" means every token attends to every other token in the same sequence, not to a separate encoder output.
Here's the full process, with no steps skipped:
Step 1: Create Query, Key, and Value Vectors
For every token in the sequence, the model multiplies the token's embedding by three separate weight matrices (W_Q, W_K, W_V) to produce three vectors: a Query (what this token is looking for), a Key (what this token offers to others), and a Value (the actual content to pass forward).
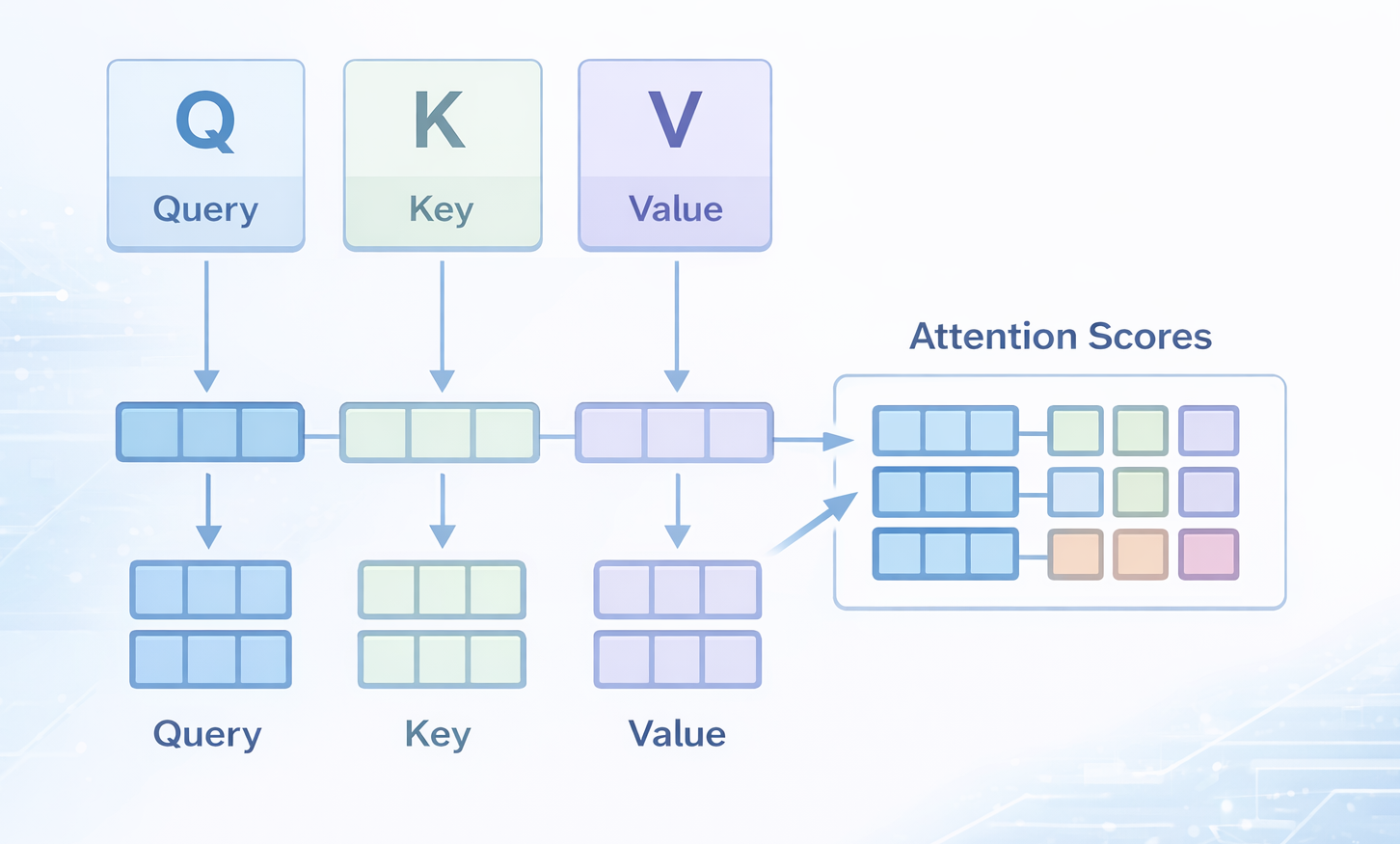
Step 2: Compute Attention Scores
The raw attention score between token A and token B is the dot product of A's Query vector with B's Key vector. This score measures compatibility: how much A should pay attention to B.
Step 3: Scale and Normalize
Raw dot products can get very large when the key dimension is high, pushing softmax into regions with near-zero gradients. The fix: divide every score by the square root of the key dimension (d_k). Then apply softmax to convert the scores into probabilities that sum to 1. The full equation is:
Attention(Q, K, V) = softmax(QKᵀ / √dₖ) × VStep 4: Weighted Sum of Values
The softmax-normalized scores are used to compute a weighted average of all Value vectors. Tokens with high attention scores contribute more to the output. The result is a new representation of each token that is now context-aware.
A concrete example: in the sentence "The animal didn't cross the street because it was too tired," the model needs to resolve that "it" refers to "animal" and not "street." Self-attention handles this by giving the query vector for "it" a high attention score against the key vector for "animal" based on learned semantic relationships. RNNs struggled with exactly this kind of long-range dependency.
The other reason self-attention beat RNNs: parallelization. RNNs process tokens sequentially. Self-attention computes all token-to-token relationships simultaneously, which maps directly to GPU hardware. That is why Transformers could scale from millions to hundreds of billions of parameters while RNNs stalled.
What Is Multi-Head Attention and Why Does It Matter?
Multi-head attention runs the self-attention operation multiple times in parallel, each time with different learned weight matrices. The original Transformer used 8 heads. GPT-3 uses 96.
Single-head attention can only learn one type of relationship per layer. Multi-head attention learns several simultaneously. One head might track syntactic structure (subject-verb agreement). Another might track positional proximity. A third might focus on semantic similarity between content words.
The math: each head independently projects Q, K, V into a lower-dimensional subspace, computes attention, and produces an output. All head outputs are concatenated and passed through a final linear transformation:
MultiHead(Q,K,V) = Concat(head₁,...,headₕ) × W₀The original paper used 8 heads with 64-dimensional key/value projections per head, totaling a 512-dimensional model. In ablation experiments on small models, moving from 4 to 8 heads at 256 dimensions improved validation perplexity by roughly 7%. Gains diminish past 12 heads at that scale, but at GPT-3 scale (96 heads, 128-dimensional subspaces), the diversity of learned representations clearly pays off.
Multi-head attention is used in: GPT-2, GPT-3, BERT, early Llama models, T5, and hundreds of other architectures. It remains the standard. GQA and MLA (discussed below) are modifications of it, not replacements.
The Quadratic Scaling Problem: Why Attention Is Expensive
Standard attention builds an N x N score matrix, where N is the sequence length. For N = 1,024 tokens, that is roughly 1 million entries. For N = 128,000 tokens (the context window of GPT-4 Turbo), it exceeds 16 billion entries. Memory and compute both scale as O(N²).
This quadratic scaling affects two things: the number of floating-point operations (FLOPs) and the amount of GPU memory needed to store the attention matrix. For long-context models, memory is usually the binding constraint.
The hardware mismatch: on an NVIDIA A100 GPU, high-bandwidth memory (HBM) has about 2 TB/s bandwidth, while on-chip SRAM runs at roughly 19 TB/s but holds only about 20 MB. Attention is memory-bound, not compute-bound. The GPU spends more time moving data between memory tiers than doing actual math. This counterintuitive fact is what Flash Attention was built to exploit.
Two lines of optimization emerged from this problem. The first changes the attention pattern: fewer key/value heads (GQA, MQA), restricted windows (sliding window attention), or compressed latents (MLA). The second keeps the full attention computation but makes it hardware-aware: this is Flash Attention.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Flash Attention Explained: Versions 1, 2, 3, and 4
Flash Attention, published by Tri Dao and collaborators at Stanford in May 2022, reframed attention as an I/O problem, not a compute problem. The insight: attention is slow because it writes the full N x N matrix to slow HBM. If you never materialize that matrix, you remove the bottleneck.
Flash Attention 1 (May 2022)
The core algorithm uses two techniques: tiling and recomputation. Instead of computing the full N x N matrix at once, Flash Attention divides Q, K, V into blocks small enough to fit in SRAM. It processes one block of K and V at a time, computing local attention scores on-chip and accumulating the result into the output directly. An online softmax algorithm tracks running max values and exponential sums so the result is mathematically identical to standard attention.
Results: up to 7.6x speedup over PyTorch's standard attention on GPT-2 training. 15% end-to-end wall-clock speedup on BERT-large pretraining. Memory usage dropped from O(N²) to O(N). Models could now train on 16K-token sequences on hardware that previously maxed out at 2-4K.
Flash Attention 2 (July 2023)
Flash Attention 2 improved work partitioning across GPU thread blocks and warps, reduced non-matmul FLOPs, and added parallelism across the sequence length dimension even within a single head. The result: 1.7-3.0x speedup over Flash Attention 1, reaching up to 225 TFLOPs/s on an A100 GPU, which represents 72% model FLOPs utilization.
Flash Attention 3 (July 2024)
Flash Attention 2 only hit about 35% utilization on H100 GPUs because it ignored Hopper-specific hardware features like the Tensor Memory Accelerator (TMA) and asynchronous Tensor Core execution. Flash Attention 3 introduced warp-specialization to overlap computation and data movement, interleaved softmax with block-wise matrix multiplications, and added FP8 support. Outcome: 1.5-2.0x speedup over FA2, reaching up to 740 TFLOPs/s in FP16 and close to 1.2 PFLOPs/s in FP8.
Flash Attention 4 (March 2026)
Flash Attention 4 targets NVIDIA Blackwell GPUs (B200). On Blackwell, tensor core throughput jumped 2.25x versus Hopper, but the special function units for softmax exponential computations did not scale proportionally. FA4 addresses this asymmetry with a 5-stage pipeline, software emulation of exponential functions on CUDA cores, and a conditional online softmax rescaling algorithm that skips roughly 90% of unnecessary rescaling operations.
Results: up to 1,605 TFLOPs/s on B200, representing 71% hardware utilization. That is 1.1-1.3x speedup over NVIDIA's cuDNN kernels and up to 2.7x over Triton implementations.
Flash Attention is now the default backend in vLLM, SGLang, Hugging Face Transformers, TensorRT-LLM, and PyTorch. Using it gives you 2-3x throughput improvement with zero quality impact. If you're running any serious LLM inference and Flash Attention is not enabled, you're leaving performance on the table.
Grouped-Query Attention vs Multi-Query Attention vs MHA
These three architectures differ in how many key and value heads they use relative to query heads. The tradeoff is inference speed versus model quality.
During autoregressive generation (text generation token by token), the model must store key and value vectors for all past tokens in a KV cache. For a model like GPT-3 with 96 heads and long contexts, this cache becomes a major memory bottleneck.

Multi-Query Attention (MQA)
Proposed by Noam Shazeer in 2019, MQA uses one shared key head and one shared value head across all query heads. This slashes KV cache size and speeds up inference significantly, but can hurt model quality because all heads are forced to use the same key-value representation. The Llama 2 team found that even with parameter count held constant by enlarging feedforward layers, MQA still underperformed MHA on benchmarks.
Grouped-Query Attention (GQA)
GQA, introduced by Ainslie et al. in 2023, assigns each group of query heads a shared key-value head. With 32 query heads split into 8 groups, every 4 query heads share one KV head. This significantly reduces KV cache while preserving most of the quality of full MHA. Llama 2 70B uses 8 KV groups. Mistral 7B uses 8 groups. Falcon 40B uses 8 groups. GQA has become the de facto standard for open-source models in 2025-2026.
Multi-Head Latent Attention: DeepSeek's KV Cache Breakthrough
Multi-head latent attention (MLA), introduced in DeepSeek-V2 (May 2024), takes a fundamentally different approach to the KV cache problem. Instead of reducing the number of KV heads, it compresses the full-dimensional key and value vectors into a low-rank latent space before caching.
The architecture uses a down-projection matrix to compress the input into a small latent vector. During attention computation, two up-projection matrices reconstruct full-dimensional keys and values from that latent. Only the compressed latent is stored in the KV cache, not the full-dimensional KV vectors.
The numbers: compared to DeepSeek's 67B dense model using standard MHA, DeepSeek-V2 with MLA reduced KV cache size by 93.3%. More surprisingly, in ablation studies, MLA slightly outperformed MHA on benchmarks. GQA, by contrast, underperformed MHA in the same ablations.
I find this result genuinely surprising. The conventional assumption was that reducing KV cache always costs you model quality. MLA challenges that. The compression-decompression step apparently does not degrade the information content enough to matter, and the model actually benefits from the lower-dimensional latent representations as a form of regularization.
MLA requires a modified implementation of rotary position embeddings (RoPE) because standard RoPE is incompatible with low-rank key compression. DeepSeek solved this with decoupled RoPE. Both DeepSeek-V3 (671B parameters) and DeepSeek-R1 use MLA as their core attention mechanism.
Types of Attention Mechanism: A Comparison Table
Here is a map of the major attention variants you'll encounter in 2026 and what each one is designed to solve:
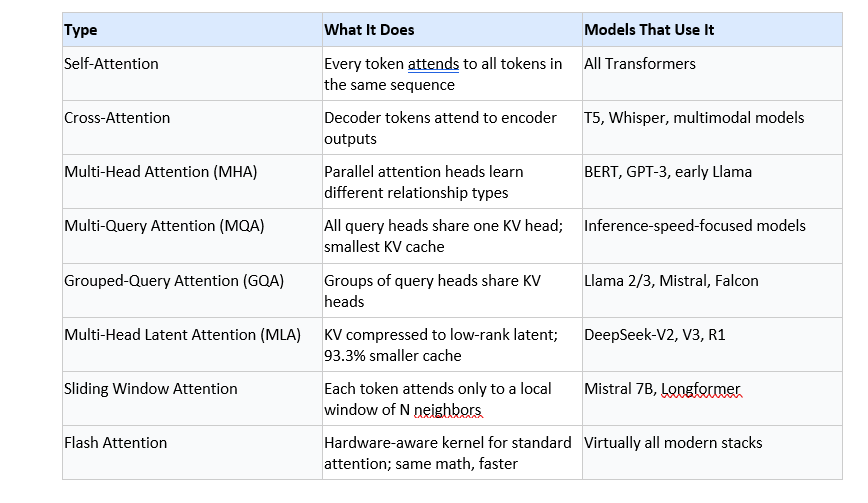
The trajectory is clear: the field is moving toward architectures that shrink or eliminate the KV cache bottleneck while preserving full attention quality. MLA appears to be winning that race in 2026, at least at scale.
Want to build LLM-powered applications and understand architectures like these from the ground up?
Join Build Fast with AI's Gen AI Launchpad, an 8-week structured bootcamp to go from 0 to 1 in Generative AI.
Register here: buildfastwithai.com/genai-course
Frequently Asked Questions
What is the attention mechanism in LLMs?
The attention mechanism is the core operation in every Transformer-based large language model. It lets each token compute relevance scores against every other token in the sequence using learned query, key, and value projections. The scores are normalized with softmax and used to compute a weighted sum of value vectors, producing a context-aware representation. The full equation is: Attention(Q,K,V) = softmax(QK^T / sqrt(d_k)) V.
What is self-attention in a Transformer?
Self-attention is attention where the queries, keys, and values all come from the same sequence rather than a separate encoder. Every token attends to every other token in the same input. Self-attention replaced sequential RNN processing and enabled the parallelization that made it possible to train models with hundreds of billions of parameters on modern GPU clusters.
What is the difference between multi-head attention and self-attention?
Self-attention is the base operation: one set of Q, K, V projections, one attention output. Multi-head attention runs self-attention multiple times in parallel with separate learned weight matrices, then concatenates the results. Each head learns different types of relationships (syntactic, semantic, positional). The original Transformer used 8 heads; GPT-3 uses 96.
How does Flash Attention speed up LLMs?
Flash Attention speeds up attention by eliminating the bottleneck of writing the full N x N attention matrix to slow GPU HBM. It uses tiling to compute attention in blocks that fit in fast on-chip SRAM, and an online softmax algorithm to accumulate exact results without materializing the full matrix. Flash Attention 4 (March 2026) achieves 1,605 TFLOPs/s on NVIDIA B200 GPUs with 71% hardware utilization. It is exact, not approximate.
What is the difference between GQA, MQA, and MHA?
Multi-head attention (MHA) gives every attention head its own unique key and value projections. Multi-query attention (MQA) uses a single shared key/value head for all query heads, minimizing KV cache at some quality cost. Grouped-query attention (GQA) groups query heads and assigns each group a shared KV head, balancing quality and cache efficiency. Llama 2 70B uses 8 KV groups (GQA). It is the standard for 2025-2026 open-source models.
What is multi-head latent attention (MLA) and how does DeepSeek use it?
MLA, introduced in DeepSeek-V2 (May 2024), compresses key and value vectors into a low-dimensional latent representation before caching, then reconstructs them during attention computation. Only the compressed latent is stored. Compared to standard MHA, DeepSeek-V2 achieved a 93.3% reduction in KV cache size. Ablation studies showed MLA slightly outperforming MHA in quality, while GQA underperformed it. Both DeepSeek-V3 and R1 use MLA.
Why does attention scale quadratically?
Standard attention must compute a score between every pair of tokens, producing an N x N matrix where N is the sequence length. Doubling N quadruples the compute and memory cost. For a 128K-token context window, this matrix has over 16 billion entries. This quadratic bottleneck is why context window expansion requires either algorithmic changes (GQA, MLA, sliding window) or hardware-aware kernels (Flash Attention) to be practical.
What are the two main steps of the attention mechanism?
The first step computes attention scores by taking the dot product of query vectors with key vectors, scaling by sqrt(d_k), and applying softmax to get a probability distribution. The second step uses those probabilities to compute a weighted sum of value vectors. Together, these two steps produce a context-aware representation of each token that encodes which other tokens are most relevant for processing that position.
Recommended Reads
If you found this useful, these posts from Build Fast with AI go deeper on related topics:
- What Is Mixture of Experts (MoE)? How It Works (2026)
- What Is RLHF? The Complete Guide to Training LLMs That Actually Work (2026)
- GLM-5.1 Review: Can It Beat Claude Opus 4.6? (2026)
- Google Gemma 4: Best Open AI Model in 2026?
- Qwen 3.6 Plus Preview: 1M Context, Speed & Benchmarks 2026
References
- Attention Is All You Need (Vaswani et al., 2017) - arXiv
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness (2022) - arXiv
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning (2023) - arXiv
- FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision (2024) - arXiv
- FlashAttention-4: Algorithm and Kernel Pipelining Co-Design (Princeton AI Blog, 2026) - Princeton
- GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints (2023) - arXiv
- DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model (2024) - arXiv
- Flash Attention GitHub Repository - Dao-AILab
- The Illustrated Transformer - Jay Alammar
A Visual Guide to Attention Variants in Modern LLMs - Sebastian Raschka (2025)

