




What Is RLHF and How Does It Make LLMs Actually Useful?
GPT-3 was released in 2020. It could write essays, generate code, and complete almost any text prompt you gave it. But it was also wildly unpredictable. Ask it a question and it might give you a brilliant answer, a completely fabricated one, or just continue your prompt as if it were a Wikipedia article. It was powerful but not useful in the way a product needs to be.
Then in late 2022, OpenAI released ChatGPT. Same underlying architecture. Same fundamental capabilities. But ChatGPT could follow instructions, hold a conversation, refuse harmful requests, and stay on topic. It became the fastest-growing consumer application in history, reaching 100 million users in two months. The difference between GPT-3 and ChatGPT wasn't more parameters or more training data. It was RLHF, Reinforcement Learning from Human Feedback.
RLHF is the technique that transformed raw language models from impressive text predictors into the conversational AI systems that hundreds of millions of people use daily. It's the reason ChatGPT, Claude, and Gemini feel helpful rather than chaotic. And running it at the scale of frontier models is one of the most logistically complex operations in AI. Let's break down exactly how it works and what it takes to do it for real.
Why Pretraining Alone Isn't Enough
A pretrained LLM is fundamentally a next-token prediction machine. It's been trained on trillions of tokens of internet text to predict what word comes next in a sequence. This gives it vast knowledge and fluent language generation, but it creates a critical gap: the model has no concept of what a "good" response is.
Ask a pretrained model "What is the capital of France?" and it might respond with "Paris" or it might continue the sentence as if it's writing a geography quiz: "What is the capital of France? A) Paris B) Lyon C) Marseille." Both are valid text completions, but only one is what a user actually wants.
The problem gets worse with complex tasks. A pretrained model doesn't know when to be concise versus detailed. It doesn't understand that fabricating a medical diagnosis is dangerous. It doesn't grasp that a coding question expects executable code, not a discussion about programming philosophy. These are all subjective qualities that are easy for humans to judge but nearly impossible to define mathematically as a loss function.
Traditional supervised fine-tuning (SFT) helps by training the model on examples of ideal prompt-response pairs written by humans. But SFT has limits. You can only show the model what good looks like, never what bad looks like. And for many tasks, there's no single "correct" answer. A response can be helpful in many different ways, and SFT struggles to capture that nuance.
This is where RLHF enters the picture. Instead of trying to define "good" mathematically, RLHF lets humans judge model outputs directly and trains the model to produce more of what humans prefer.
How RLHF Works Step by Step
The RLHF pipeline has three distinct stages, each building on the previous one. Understanding each stage is essential for grasping both the power and the complexity of the technique.
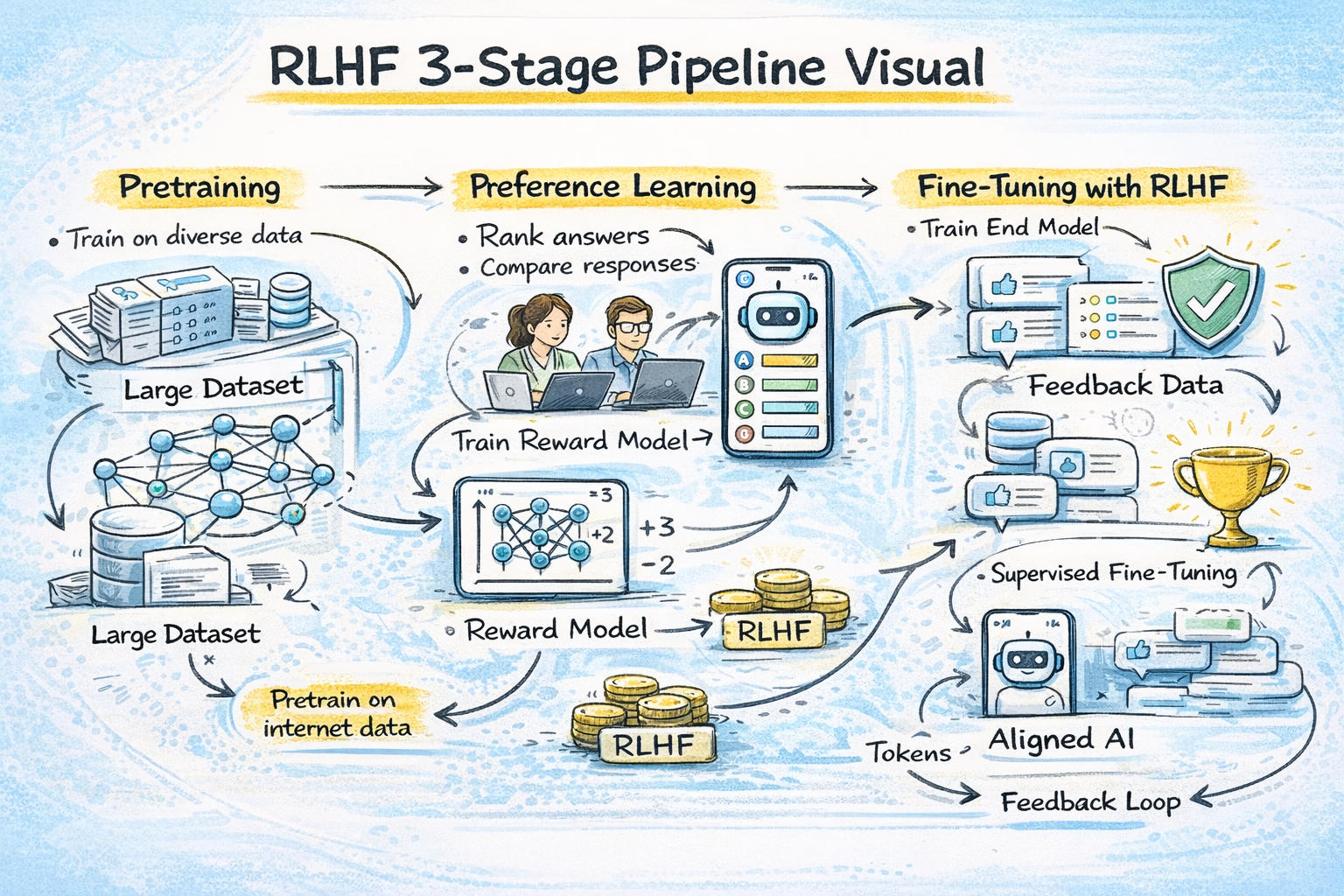
Stage 1: Supervised Fine-Tuning (SFT). Before applying RL, the model needs a starting point that can follow instructions at a basic level. A team of human annotators writes high-quality responses to a curated set of prompts. These prompt-response pairs are used to fine-tune the pretrained model using standard supervised learning. For InstructGPT, OpenAI used roughly 13,000 human-written demonstrations for this stage. Anthropic used transformer models from 10 million to 52 billion parameters. This SFT model becomes the foundation for everything that follows.
Stage 2: Reward Model Training. This is the most distinctive part of RLHF. Instead of defining a mathematical reward function (which would be impractical for something as subjective as "helpfulness"), you train a separate neural network to predict what humans would prefer.
Here's how it works: the SFT model generates multiple responses to the same prompt. Human annotators then rank these responses from best to worst. These rankings are converted into pairwise comparisons (Response A is better than Response B) and used to train a reward model. The reward model learns to assign a scalar score to any given prompt-response pair that reflects how much humans would like it.
For InstructGPT, OpenAI used roughly 50,000 labeled preference comparisons. Each prompt had 4 to 9 candidate responses, forming between 6 and 36 pairwise comparisons per prompt, yielding 300K to 1.8M training examples. Anthropic's Constitutional AI process used 318K comparisons in total, with 135K generated by humans and 183K generated by AI.
The reward model is typically initialized from the SFT model itself. The intuition is that the reward model needs to understand language at least as well as the model it's evaluating. If the reward model is weaker than the policy model, it can't reliably score the outputs.
Stage 3: RL Fine-Tuning with PPO. This is where the actual reinforcement learning happens. The SFT model (now called the "policy") generates responses to prompts. The reward model scores each response. Then Proximal Policy Optimization (PPO), an RL algorithm, adjusts the policy to produce responses that receive higher reward scores.
There's a critical constraint: you don't want the model to change too much from its SFT starting point. Without this constraint, the model might learn to "game" the reward model by producing outputs that score high but are actually degenerate. To prevent this, RLHF adds a KL divergence penalty that penalizes the model for deviating too far from the original SFT distribution. This keeps the model from losing the general capabilities it learned during pretraining and SFT.
The PPO training loop is iterative: generate responses, score them, compute the policy gradient, update the model, repeat. Each iteration improves the model's alignment with human preferences as captured by the reward model.
The Logistics of RLHF at Scale
Running RLHF on a research model is one thing. Running it on a frontier model with hundreds of billions of parameters is a completely different engineering challenge. The logistics are staggering, and this is where most of the cost and complexity actually lives.
The four-model problem. PPO-based RLHF requires keeping four separate large models in GPU memory simultaneously: the policy model (the LLM being trained), the reference model (a frozen copy of the SFT model for computing the KL penalty), the reward model, and the critic/value model (used by PPO to estimate advantages). For a 70B parameter model, each copy requires roughly 140 GB in FP16. That's 560 GB just for model weights, before accounting for activations, optimizer states, or KV caches. This means you need distributed training across dozens or hundreds of GPUs even for a single RLHF training run.
Human annotation is the bottleneck. Every RLHF iteration requires high-quality human preference data. Generating well-written demonstration responses for SFT requires hiring skilled writers, not crowdworkers. OpenAI employed a team of about 40 contractors for InstructGPT's annotation work. At production scale, companies like Scale AI and Surge AI provide thousands of trained annotators. The cost is substantial: high-quality human annotation for RLHF runs approximately $100 per expert comparison for complex tasks, and expert annotation rates can exceed $40 per hour. For frontier models requiring hundreds of thousands of comparisons, the annotation budget alone can reach millions of dollars.
Annotator consistency is a real problem. Different humans have different preferences. One annotator might value brevity while another values detail. One might prioritize factual accuracy while another values engaging tone. This inter-annotator disagreement introduces noise into the reward model training. Production RLHF systems use multiple annotators per comparison, carefully designed annotation guidelines, and statistical aggregation methods (like Elo ratings) to manage this variance. But it remains a fundamental limitation: human judgment is noisy, and the reward model can only be as good as the data it's trained on.
Reward hacking is a constant risk. The policy model can learn to exploit weaknesses in the reward model rather than genuinely improving. For example, models might learn that longer responses score higher (because annotators sometimes equate length with thoroughness) and start padding responses with unnecessary text. Or models might learn that confident-sounding language scores well, even when the content is wrong. John Schulman (co-creator of PPO) has noted that while RLHF was supposed to help with hallucination, the InstructGPT paper showed it actually made hallucination slightly worse, because the model learned to sound more confident. Mitigating reward hacking requires careful reward model design, regularization, and iterative evaluation.
Training instability at scale. PPO is notoriously sensitive to hyperparameters, and this sensitivity amplifies at large scale. Learning rates, KL penalty coefficients, batch sizes, and clip ratios all need careful tuning. The "Secrets of RLHF in Large Language Models" paper documented advanced techniques needed to stabilize PPO training: normalizing and clipping rewards based on historical statistics, initializing the critic model from the reward model, using global gradient clipping, and adding pretrain language model loss to reduce "alignment tax" (the degradation of general capabilities during RLHF). Without these tricks, PPO training at scale frequently diverges or produces degenerate outputs.
Distributed orchestration is complex. RLHF training isn't just running one forward pass and one backward pass. Each iteration requires: generating responses from the policy (inference), scoring them with the reward model (inference), computing advantages with the critic (inference), and updating the policy and critic (training). These four operations have different compute profiles and need to be orchestrated across a GPU cluster. Frameworks like OpenRLHF (built on Ray + vLLM) and TRL (from Hugging Face) have been developed specifically to handle this orchestration, distributing the actor, critic, reward model, and reference model across separate GPU groups.
Beyond RLHF: DPO, GRPO, and RLVR
The complexity and cost of PPO-based RLHF motivated the development of simpler alternatives. The field has evolved rapidly, and the standard RLHF recipe from 2022 looks very different from what frontier labs use in 2026.
Direct Preference Optimization (DPO), introduced by Stanford researchers in 2023, eliminates the reward model entirely. Instead of training a separate reward model and then running RL, DPO reformulates the problem as a supervised classification task. It trains the model directly on preference pairs using a contrastive loss that increases the probability margin between preferred and rejected responses. DPO is simpler to implement, requires less GPU memory (no reward model or critic), and is more stable to train. SimPO, an extension, outperforms DPO by 6.4 points on AlpacaEval 2 and 7.5 points on Arena-Hard.
Group Relative Policy Optimization (GRPO), introduced by DeepSeek, has become the dominant RL algorithm for training reasoning models. GRPO's key innovation is eliminating the separate critic model that PPO requires. For each prompt, GRPO generates a group of multiple responses (typically 8-64), scores them all with a reward model, and computes advantages by comparing each response's reward against the group mean and standard deviation. This reduces memory requirements by roughly 50% compared to PPO since you no longer need a full critic model. A recent theoretical analysis showed that GRPO's policy gradient is provably optimal within a broad class of policy gradient methods, not just a practical hack. GRPO is now used in DeepSeek R1, Nemotron 3 Super, and numerous other production models.
Reinforcement Learning with Verifiable Rewards (RLVR) represents the biggest paradigm shift. Instead of relying on human preference labels or learned reward models, RLVR trains models on tasks where correctness can be automatically verified, like math problems (check the answer) and code (run unit tests). The reward signal is binary and perfect: the answer is correct or it isn't. DeepSeek R1 demonstrated that pure RLVR with GRPO, applied directly to a base model without any supervised fine-tuning, could produce emergent reasoning capabilities including self-verification and extended chain-of-thought reasoning. Because verifiable rewards are less prone to reward hacking, RLVR training can run much longer than traditional RLHF without collapsing. This is how reasoning models achieve their impressive math and coding capabilities.
The modern post-training stack in 2026 is modular. SFT teaches instruction-following format. Preference optimization (DPO/SimPO/KTO) handles alignment with human preferences. RL with verifiable rewards (GRPO/DAPO) builds reasoning capabilities. Each stage addresses a different aspect of model behavior, and the combination produces models that are helpful, safe, and capable of complex reasoning. As Sebastian Raschka summarized: LLM development in 2025-2026 was "essentially dominated by reasoning models using RLVR and GRPO."
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Why RLHF Still Matters
Despite the evolution toward DPO, GRPO, and RLVR, classical RLHF hasn't disappeared. It remains essential for aligning models on open-ended tasks where there's no verifiable ground truth, things like tone, helpfulness, cultural sensitivity, and creative quality. You can't write a unit test for "was this response empathetic?"
DeepSeek R1's final training stage used both RLVR (for reasoning tasks) and traditional RLHF with neural reward models (for general helpfulness and harmlessness). They used separate reward models for each criterion: helpfulness was scored based only on the final answer, while harmlessness was evaluated on the entire reasoning chain. This hybrid approach is likely what most frontier labs use today.
The OpenAI GPT-4 technical report showed that RLHF doubled accuracy on adversarial questions. Even more striking, OpenAI noted that labelers preferred outputs from the 1.3B parameter InstructGPT model over the 175B parameter GPT-3. A smaller model with RLHF beat a model 135x its size without it. That result alone justified the technique's central role in modern AI.
RLHF also has a practical advantage that's often overlooked: it's more data-efficient than pretraining. You don't need trillions of tokens. InstructGPT used around 50,000 preference comparisons. Anthropic's dataset contained roughly 318K comparisons. Compared to the trillions of tokens and hundreds of millions of dollars required for pretraining, RLHF delivers outsized improvements for a relatively modest investment in human annotation.
Want to understand LLM training end-to-end and build AI systems yourself?
Join Build Fast with AI's Gen AI Launchpad, an 8-week structured bootcamp to go from 0 to 1 in Generative AI.
Register here: buildfastwithai.com/genai-course
Frequently Asked Questions
What is RLHF in simple terms?
RLHF (Reinforcement Learning from Human Feedback) is a training technique that teaches LLMs to generate responses that humans prefer. Instead of defining "good" mathematically, humans rank model outputs, a reward model learns to predict those rankings, and then reinforcement learning optimizes the LLM to produce higher-scoring responses. It's what transformed GPT-3 into ChatGPT.
Why can't you just use supervised fine-tuning instead of RLHF?
Supervised fine-tuning (SFT) only shows the model examples of good responses, never bad ones. It also struggles with tasks where there's no single "correct" answer. RLHF captures nuanced preferences by letting humans compare different responses, providing both positive and negative signals. OpenAI showed that a 1.3B model with RLHF outperformed a 175B model with only SFT, demonstrating that alignment matters more than raw size for usability.
What is the difference between PPO, DPO, and GRPO?
PPO (Proximal Policy Optimization) is the original RL algorithm used in RLHF, requiring four models in memory simultaneously. DPO (Direct Preference Optimization) eliminates the reward model entirely, training directly on preference pairs as a classification task. GRPO (Group Relative Policy Optimization) removes the critic model from PPO by comparing multiple responses within a group, reducing memory by roughly 50%. GRPO is now the dominant algorithm for training reasoning models.
How much does RLHF cost for a frontier model?
The total cost includes human annotation (potentially millions of dollars for hundreds of thousands of expert comparisons at ~$100 per complex comparison), compute for running PPO across four model copies (requiring hundreds of GPUs for 70B+ models), and iterative evaluation. The annotation alone for a production RLHF pipeline can cost $1-5 million depending on scale and task complexity.
What is RLVR and how is it different from RLHF?
RLVR (Reinforcement Learning with Verifiable Rewards) uses automatically verifiable rewards instead of human preference labels. For math problems, the reward is whether the answer is correct. For code, it's whether the code passes tests. DeepSeek R1 showed that RLVR with GRPO can produce emergent reasoning abilities without any human feedback, making it cheaper and more scalable than traditional RLHF for reasoning tasks.
References
Training Language Models to Follow Instructions with Human Feedback (InstructGPT) - arXiv (Ouyang et al., OpenAI)
Illustrating Reinforcement Learning from Human Feedback (RLHF) - Hugging Face Blog
RLHF: Reinforcement Learning from Human Feedback - Huyenchip
Secrets of RLHF in Large Language Models Part I: PPO - arXiv
RLHF 101: A Technical Tutorial - CMU Machine Learning Blog
Group Relative Policy Optimization (GRPO) - Cameron R. Wolfe
Post-Training in 2026: GRPO, DAPO, RLVR and Beyond - LLM Stats
The State of LLMs 2025 - Sebastian Raschka
InstructGPT and RLHF: Aligning Language Models with Human Preferences - Michael Brenndoerfer
Reinforcement Learning from Human Feedback - Wikipedia

