




Gemini Omni: Everything We Know About Google's Leaked AI Video Model
Something appeared inside the Gemini app on May 11, 2026 that was not supposed to be there yet: a new model card that read "Create with Gemini Omni — meet our new video model. Remix your videos, edit directly in chat, try templates, and more." Within hours, the AI community was calling it the most significant video AI leak since Sora.
The timing is not subtle. Google I/O 2026 opens on May 19 — eight days from the leak. A consumer-facing UI string appearing in the live Gemini app this close to the annual developer keynote is almost certainly deliberate staging. The only real question is what Gemini Omni actually is and whether its capabilities live up to the hype generated by early testers who got brief access.
Here is every confirmed fact, every reasonable inference, and every honest caveat about Gemini Omni — including how it fits into the competitive video AI landscape that ByteDance, OpenAI, Runway, and others have been rapidly reshaping through
What Is Gemini Omni? The Leak and What It Shows
Gemini Omni is an unreleased Google AI video model that surfaced in the Gemini app's video generation tab on May 11, 2026. The first trace appeared on May 2, when X user @Thomas16937378 spotted a UI string reading "Start with an idea or try a template. Powered by Omni." in the video generation interface — right next to "Toucan," the internal codename for the current Veo 3.1-powered pathway.
By May 11, the leak had expanded. Reddit users began posting screenshots of a full model card inside the Gemini app: "Create with Gemini Omni: meet our new video model. Remix your videos, edit directly in chat, try templates, and more." The description was consumer-facing, written in plain language, and appeared to be part of an A/B test or accidental rollout rather than buried developer code.
Community sleuths also recovered the full model ID: bard_eac_video_generation_omni/bard/v3smm-lora-prod.goat-cr-rev6-xm171555416-at-1200, and confirmed a current 10-second video generation limit for the model in its early state. Based on the Nano Banana playbook — where Google launched an image model at middling quality that was later upgraded to frontier — there are strong signals Omni will ship in tiered Flash and Pro variants, with the early test outputs coming from the Flash tier.
It is also notable that TestingCatalog, the most reliable tracker of Google AI pre-launch leaks, reported that Gemini Omni will be available via API and will function as an Agent — similarly to how Deep Research works in AI Studio. That is a meaningful development signal: Gemini Omni is not just a consumer video tool, it is infrastructure.
To understand the foundation Gemini Omni is building on, our full Google Veo 3.1 review and API guide covers everything about the current state-of-the-art Google video model, including pricing, prompt best practices, and what changed from Veo 3.
How Gemini Omni Works: What Early Testers Reported
The early test outputs that circulated on May 11 gave the AI community its first real signal of what Omni is capable of. The reaction was mixed in a very specific and instructive way: raw generation quality lagged behind the current benchmark leader (ByteDance's Seedance 2.0), but video editing capability was described as unusually strong for a first glimpse.
TestingCatalog summarized the community verdict well: "I won't lie, this is one of the best video models I have seen, maybe not the best, but a really strong performance." Prompt adherence was called out as a particular strength — the model followed complex scene descriptions with unusual accuracy. The exception was one shot with a missing centerpiece in an otherwise well-executed scene.
1. In-Chat Video Editing
The most discussed feature in early outputs was conversational editing. Unlike every other AI video generator on the market, which require you to re-generate an entirely new clip if you want to change something, Gemini Omni reportedly lets you iterate inside the chat: swap objects, change visual elements, modify scenes without re-rendering from scratch.
Specific examples that circulated: swapping objects in anime scenes, removing watermarks from clips, replacing background elements, and changing character clothing through typed chat instructions. This is a fundamentally different workflow from Veo, Seedance, or Sora — and if it holds up at scale, it removes the biggest friction point in AI video production workflows.
2. Text and Math Rendering
One viral example from early testing showed a professor writing out mathematical equations correctly on a chalkboard. This is genuinely hard for AI video models — it requires not just visual coherence (the right shapes) but semantic accuracy (the equations must be mathematically correct and legible). Current models, including Veo 3.1 and Seedance, struggle consistently with readable text in video.
The viral X post from Chetaslua framing the moment: "If this is not the Nano Banana moment of video, what is?" The comparison is apt: Nano Banana was Google's breakthrough for text rendering in images. Omni may be its equivalent for video.
3. Cinematic Motion and Scene Coherence
Early outputs showed stronger-than-expected temporal consistency — the tendency for AI video models to produce flickering objects, warped physics, or incoherent scene transitions between frames. Omni's outputs showed coordinated character motion, realistic camera movement, and dynamic lighting that maintained consistency across the clip. Reviewers noted minor motion artifacts and occasional transition issues, but praised the overall coherence given the model's apparent early stage.
For a concrete picture of how AI video models have been applied in creative production pipelines using Google's stack, the NotebookLM Cinematic Video Overview guide shows how Gemini, Nano Banana Pro, and Veo work together in a three-model pipeline — the architecture that Omni is expected to unify.
The Three Interpretations: Rebrand, New Model, or True Omni-Model?
The community has converged around three plausible interpretations of what Gemini Omni actually is under the hood. None of them can be confirmed until Google speaks at I/O. But each interpretation carries meaningfully different implications for developers and creators.
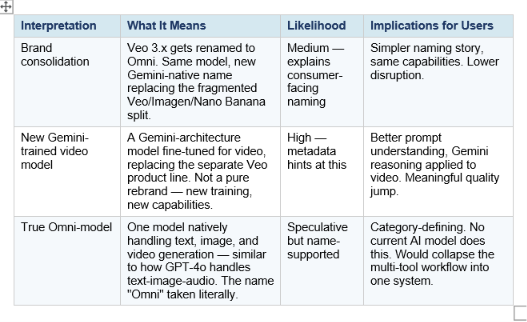
The strongest evidence for Option 2 is the model architecture — metadata suggests Omni is built on a Gemini foundation rather than being a straight Veo version bump. The strongest case for Option 3 is the name itself, combined with the strategic logic: Google's current split approach (Veo for video, Nano Banana for images, Gemini for text) creates friction for users and a harder marketing story than OpenAI's "GPT-4o handles everything" positioning.
My read: Option 2 is the most likely immediate reality, with Option 3 being the longer-term strategic direction the Omni brand signals. Google is almost certainly building toward a unified Gemini omni-model — Nano Banana did it for images, and Omni does it for video — but the first launch is probably a strong Gemini-native video model, not a fully unified system from day one.
Gemini Omni vs the Competition: Veo 3.1, Seedance 2.0, Sora 2, Runway
The AI video generation market has matured dramatically in 2026. Six major models are competing for developer and creator adoption, each with distinct strengths. Here is where Gemini Omni enters and what it needs to beat.
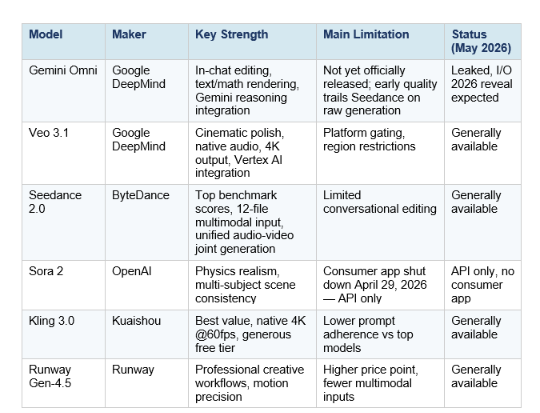
The honest competitive picture: Gemini Omni is entering a market where ByteDance's Seedance 2.0 leads on raw generation benchmarks, Sora 2 leads on physical realism, and Veo 3.1 leads on cinematic polish. Omni's differentiation is not going to come from beating those models on their own terms in the first version. It is going to come from the "omni" part — the ability to reason, edit, and iterate in a conversational loop that no current specialized video model offers.
The Nano Banana parallel is instructive. When Nano Banana launched, it did not immediately beat Midjourney or DALL-E on pure image quality. It led on editing flexibility and text rendering, then caught up on generation quality with subsequent versions. Gemini Omni looks like it is following the same trajectory for video: lead on editing and reasoning, catch up on raw generation fidelity over the following months.
For a full benchmark comparison of the current AI model landscape including Gemini models against GPT, Claude, and Grok, our every AI model compared: best one per task 2026 guide covers the performance data in detail.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
What Google I/O 2026 Will Likely Reveal on May 19
Google I/O 2026 opens May 19 at 10 AM PT at the Shoreline Amphitheatre in Mountain View, with the developer keynote at 1:30 PM PT. Based on the Gemini Omni leak and the broader pre-I/O signal, here is the most likely scenario for what gets announced around video AI.
High probability: Official Gemini Omni launch
A consumer-facing UI string appearing in the live Gemini app eight days before I/O is not an accident. This is how Google stages keynote reveals — surface the product name just long enough for the community to pick it up and build anticipation. Gemini Omni is almost certainly getting main-stage time. The question is how much of what the community has speculated about (true omni-model, unified image+video+text) gets confirmed versus how much remains on the roadmap.
High probability: Gemini 4 announcement
Multiple analysts and leaked session titles point to a next-generation Gemini model reveal at I/O 2026 — potentially with 10 million+ token context, native multimodal generation, and natively integrated agentic capabilities. Gemini 4 and Gemini Omni are likely positioned as complementary reveals: the reasoning model and the creative model, both under the Gemini umbrella.
Medium probability: API and pricing details for Omni
TestingCatalog's reporting indicates Gemini Omni will be available via API. The open question is whether developer API access lands on day one or trails the consumer launch. Google's pattern with Veo was to launch consumer access first and API access weeks to months later. Developers should watch the I/O developer keynote specifically for Vertex AI and Gemini API announcements.
Possible: "Spark Robin" visual model and memory features
Alongside Omni, additional leaks point to a visual model codenamed "Spark Robin" appearing in testing references, as well as a long-term memory feature internally called "Teamfood" for persistent chat context across Gemini sessions. Neither of these has the same evidence base as Omni, but they round out the picture of a major I/O release across Gemini's creative and agentic surfaces.
For context on how Google's image model strategy with Nano Banana evolved — which is the direct parallel to Omni's expected trajectory — the Nano Banana Pro use cases and prompts guide walks through how the image model matured from launch to current capability.
What This Means for Developers and Creators
Whether Gemini Omni turns out to be a true unified model or a strong new Gemini-native video model, the strategic implications are the same: Google is collapsing the fragmented AI creative stack into a single Gemini-branded experience.
For content creators
The current workflow for AI video production is genuinely painful. You prototype a storyboard in one tool, generate still frames in Nano Banana or DALL-E, animate them in Veo or Seedance, add audio separately, and edit everything together in post. Each tool boundary is a friction tax. Gemini Omni's conversational editing promise — change elements inside chat without re-rendering — directly attacks this friction. If it works as described, the creator workflow shifts from a multi-tool pipeline to a single Gemini session.
For developers building on the Gemini API
The API implications are the part the creator coverage is underweighting. TestingCatalog's reporting that Omni will work as an Agent via AI Studio — not just a video endpoint — suggests a fundamentally different integration model from Veo 3.1. Instead of calling a video generation endpoint, developers may be able to build Omni into multi-step agentic workflows where video is generated, evaluated, and iteratively refined within a single agent session.
A caution worth stating: do not lock in production video workflows to Veo 3.1 right now without budgeting for API rename or deprecation. If Omni supersedes Veo's product line, the transition period could require prompt engineering adjustments and endpoint changes. Watch the I/O developer keynote for migration guidance before committing.
For developers who want to experiment with the current Gemini API video stack before Omni launches, the Build Fast with AI gen-ai-experiments cookbook has multimodal generation notebooks covering the Gemini API that provide a hands-on foundation.
For teams building AI-powered media products
Gemini Omni is the clearest signal yet that Google intends to own the full AI creative production stack — image, video, audio, and text — under a single Gemini umbrella. For teams currently using a mix of Google and third-party models (Midjourney for images, Seedance for video, ElevenLabs for audio), the arrival of a unified Gemini model simplifies vendor management, reduces integration complexity, and potentially cuts costs through consolidated billing.
The competitive risk for specialized video platforms — Runway, Pika, Luma — is real but not immediate. First-launch Omni will likely trail them on specific dimensions of generation quality. The risk accelerates if Omni version 2 or 3 matches or exceeds specialized models in quality while maintaining the conversational editing advantage. That is the same trajectory Nano Banana followed in images.
The broader multimodal model strategy context — how Google positions Nano Banana for images against Apple and other competitors — is covered in our Google Nano Banana vs Apple FastVLM comparison. The strategic pattern applies directly to how Omni will compete in video.
Frequently Asked Questions
What is Gemini Omni?
Gemini Omni is an unreleased Google AI video model that leaked inside the Gemini app on May 11, 2026, eight days before Google I/O 2026. According to the leaked description, it is "a new video generation model" that lets users "remix your videos, edit directly in chat, try templates, and more." It is expected to be officially revealed at Google I/O on May 19, 2026.
Is Gemini Omni the same as Veo 4?
Unknown as of the leak. Gemini Omni's model ID metadata suggests it is built on a Gemini foundation rather than a straight Veo version bump. It may be a new Gemini-trained video model that replaces or supplements the Veo product line, or it may be a true unified model handling image, video, and text in one system. Google has not confirmed either interpretation.
When will Gemini Omni launch?
Google I/O 2026 runs May 19–20 and is the most likely official launch window. The consumer-facing UI string appearing inside the live Gemini app eight days before the event is consistent with how Google stages keynote reveals. Broader availability and API access timelines will depend on what Google announces on stage.
Can Gemini Omni edit videos in chat?
Based on early test outputs and the model card description, yes — in-chat video editing is a core feature. Early testers reported removing watermarks, swapping objects, and modifying scenes through typed chat instructions without re-rendering entire clips. This is a significant differentiator from every other current AI video model, which require full re-generation for changes.
How does Gemini Omni compare to Seedance 2.0?
Based on early outputs, Seedance 2.0 leads on raw generation quality — cinematic fidelity, motion realism, and benchmark scores. Gemini Omni's advantage is in conversational editing, text/math rendering in video, and integration with Gemini's reasoning capabilities. The models are likely targeting different use cases at launch, with Omni prioritizing workflow and editability over pure generation quality.
Will Gemini Omni have an API?
Yes, based on TestingCatalog's reporting. Gemini Omni is expected to be available via API and function similarly to Deep Research in AI Studio — as an Agent rather than a simple generation endpoint. Exact API launch timing, pricing, and whether it goes through the Gemini API, Vertex AI, or both have not been confirmed as of the leak.
What Google plan will Gemini Omni require?
Not confirmed yet. Based on the Veo 3.1 precedent, video generation features are typically gated behind Gemini Advanced ($19.99/month) or Google AI Ultra ($249.99/month) plans, with limited access at lower tiers. A tiered Omni model (Flash for lower-cost access, Pro for higher quality) would follow the same pattern as Nano Banana.
What does the "Nano Banana moment" comparison mean?
AI creators compared Gemini Omni to Nano Banana — Google's breakthrough image model — because Nano Banana was the first time an AI image model made text rendering in images reliable, which was a long-standing hard problem. Similarly, Gemini Omni appears to make text and math rendering in video reliable, which is currently a hard unsolved problem for all video models. The "Nano Banana moment for video" framing means Omni may represent the same kind of step-change for video that Nano Banana did for images.
Recommended Blogs
- Google Veo 3.1 Review: Lite vs Fast, Pricing, Prompts & API Guide
- NotebookLM Cinematic Video Overview: Full Guide (2026)
- 20+ Top Nano Banana Pro Use Cases + Gemini 3 AI Prompts
- Google Nano Banana vs Apple FastVLM: Which Vision Model Should You Choose?
- Every AI Model Compared: Best One Per Task (2026)
- Claude AI Complete Guide 2026: Models, Features, and Pricing Explained
References
- 9to5Google — Gemini "Omni" Video Model Shows Up With Some Early Demos
- TestingCatalog — Google's Gemini Omni Video Model Surfaces Ahead of I/O Debut
- TestingCatalog — Google Is Testing New Omni Model for Video Generation
- iWeaver AI — Gemini Omni Video Model at Google IO 2026: Everything We Know
- Oimi AI — Google Gemini Omni Leaked: Everything We Know About Google's Unified AI Model
- WaveSpeed Blog — Google's Mysterious Omni Video Model: What the Gemini UI Leak Tells Us
- RoboRhythms — Google Just Leaked Its Gemini Omni Video Tool Days Before I/O 2026
- Google — Save the Date: Google I/O 2026 is May 19–20
- Android Authority — What to Expect from Google I/O 2026

