




Claude Fable 5 vs Claude Sonnet 5: Which Model Should You Actually Use? (July 2026)
Between June 30 and July 1, 2026, Anthropic completed the most consequential 24-hour period in the Claude family's history. Sonnet 5 launched on June 30, the same day export controls on Fable 5 were lifted. Fable 5 returned on July 1. For the first time, both models are simultaneously available, and the question everyone is asking is the same: do you pay five times more for Fable 5, or is Sonnet 5 enough? The answer is not the same for every team. Fable 5 leads Sonnet 5 on SWE-bench Pro by 17 points (80.3% vs 63.2%), and on SWE-bench Verified by nearly 10 points (95% vs 85.2%). Those are real capability gaps on the hardest coding tasks. But Sonnet 5 beats Fable 5 on Terminal-Bench 2.1 (80.4% vs not published for Fable 5, with Opus 4.8 at 74.6% as the reference point), edges it on GDPval-AA knowledge work (1,618 vs 1,615 Elo), and ties it on Humanity's Last Exam with tools. And it does all of this at $2 per million input tokens through August 31, versus Fable 5's $10. This comparison covers every published benchmark where both models have scores, the real cost picture after the tokenizer change, what effort levels do to the cost math, where Fable 5's capability gap actually shows up in production, and the exact routing logic you should apply today.
1. The Quick Verdict
Before the detail: if you need one clear decision per use case, here it is.
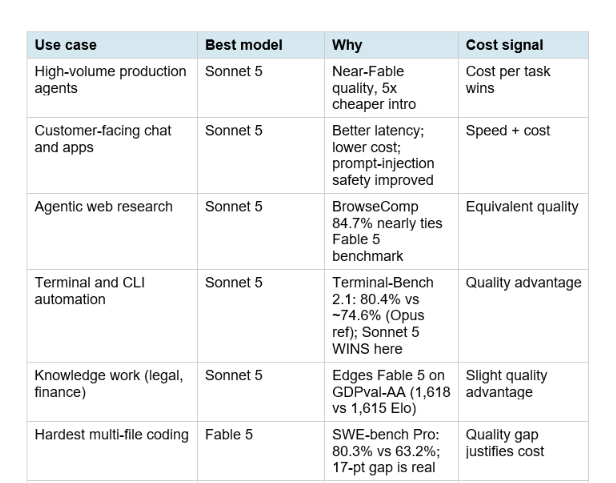
Hot take: the right answer for most teams is Sonnet 5 at medium effort for 80 to 90% of traffic, with Fable 5 reserved for a specifically identified 10 to 20% of tasks where the 17-point SWE-bench Pro gap shows up in production output quality. The mistake both ways: defaulting to Fable 5 for everything (paying 5x for tasks where Sonnet 5 is equivalent) or defaulting to Sonnet 5 for everything (accepting meaningful quality degradation on hard coding tasks that Fable 5 genuinely handles better).
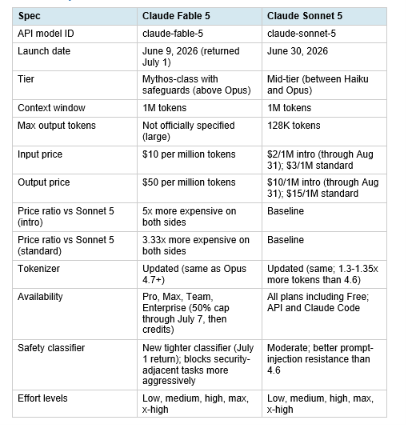
2. Model Specs at a Glance
3. Benchmark Head-to-Head: Every Published Score
All figures are from Anthropic's published system cards, official launch posts, or third-party sources clearly labeled. The Fable 5 benchmarks are from the original June 9 launch (the underlying model is unchanged since return on July 1). The Sonnet 5 benchmarks are from the June 30 launch.
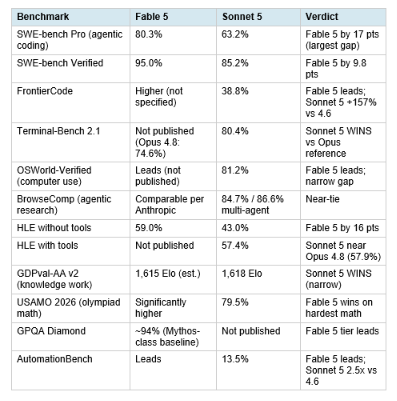
Reading the table: Fable 5 leads on everything measuring raw capability ceiling (SWE-bench Pro, Verified, HLE without tools, USAMO math). Sonnet 5 leads or ties on everything measuring production workflow output quality (Terminal-Bench 2.1, GDPval-AA, BrowseComp, HLE with tools). This split is the key insight for routing decisions: the capability gap is largest on the tasks where the model has to reason deeply without external tools, and smallest or reversed on the tasks where the model uses tools and agents to achieve its goals.
For the full Sonnet 5 benchmark breakdown with every published benchmark and the effort-level cost curve, the Claude Sonnet 5 full review on Build Fast with AI covers every number in detail. For the original Fable 5 benchmark profile from the June 9 launch before the ban, the Claude Fable 5 review has the full reference set.
4. The Pricing Reality: More Than the Rate Card
The rate card shows Fable 5 at 5x Sonnet 5 during the introductory window and 3.33x at standard pricing. But the real cost per task is more nuanced, and two factors can flip the calculation in ways that matter: the tokenizer change and the effort level you run each model at.
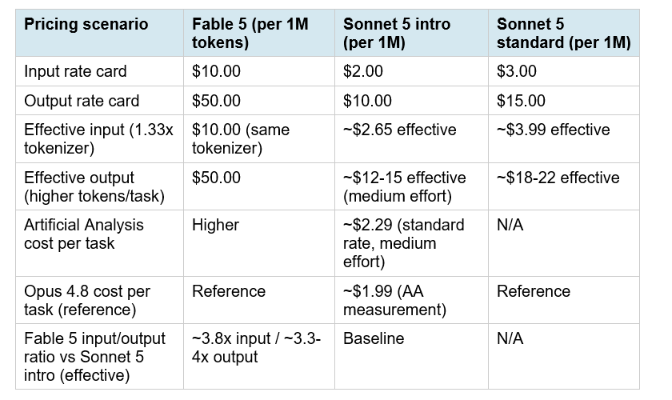
The Artificial Analysis measurement revealing that Sonnet 5 costs approximately $2.29 per task versus Opus 4.8's $1.99 at standard pricing is worth understanding carefully. It does not mean Sonnet 5 is expensive. It means Sonnet 5 emits more tokens per task than Opus 4.8 on their benchmark suite at equivalent quality output. At high and x-high effort levels, Sonnet 5's token emission rate increases further because the model thinks longer. The cost-per-task advantage of Sonnet 5 over Fable 5 is clearest at medium effort, where Sonnet 5 generates fewer tokens and the 5x rate card advantage is largely preserved in practice. At x-high effort on hard tasks, that advantage compresses. Bottom line: at medium effort for typical professional tasks, Sonnet 5 is genuinely approximately 3 to 4 times cheaper than Fable 5 in practice after accounting for the tokenizer. At x-high effort on hard tasks, the gap can narrow to 2 times or less, and on tasks where Sonnet 5 fails and requires retry loops, the effective cost per completed task can exceed what Fable 5 charges for a single successful pass.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. The Tokenizer Catch: Why Sonnet 5's Real Cost Is Higher Than $2
Both Fable 5 and Sonnet 5 use Anthropic's updated tokenizer introduced with Claude Opus 4.7. The same text that produced 1,000 tokens in Sonnet 4.6 produces approximately 1,300 to 1,350 tokens in Sonnet 5. Simon Willison's analysis documented the specific breakdowns: English prose is 1.33 to 1.42 times more tokens, Python code is 1.27 to 1.28 times more tokens, Spanish is 1.33 times, Simplified Chinese is essentially unchanged at 1.01 times. The practical effect on the introductory Sonnet 5 rate: the $2 input rate becomes approximately $2.60 to $2.85 effective for English workloads after tokenizer inflation. The $10 output rate becomes approximately $13 to $14 effective. At standard pricing from September 1, 2026, the $3 input becomes approximately $3.99 to $4.28 effective for English, and the $15 output becomes approximately $19.50 to $20.25 effective. This does not make Sonnet 5 expensive. At effective rates of approximately $2.70 input and $13 output for English during the introductory window, it is still meaningfully cheaper than Opus 4.8 at $5/$25 and dramatically cheaper than Fable 5 at $10/$50. But teams migrating from Sonnet 4.6 who assume cost neutrality at the same rate card will see real billing increases. Budget for approximately 30% more token volume for English text workloads when modeling your September 1 cost cliff.
6. The Effort Level Variable: When Sonnet 5 Costs More Than Fable 5
Both Fable 5 and Sonnet 5 support five effort levels: low, medium, high, max, and x-high (extra high). Higher effort means the model allocates more thinking budget, producing more accurate results at higher token cost. The effort level interaction with cost creates a situation that is counterintuitive until you model it explicitly.
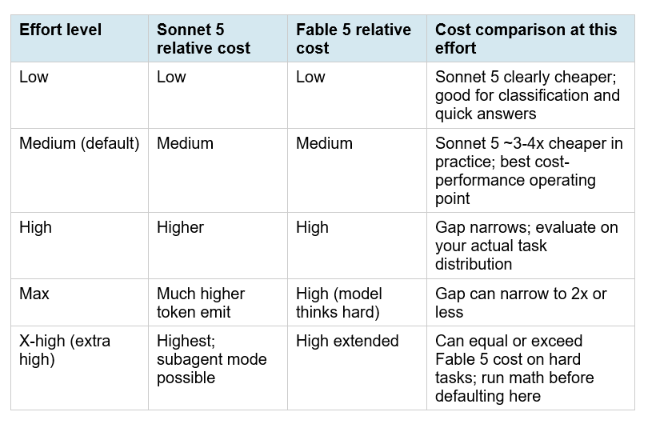
Anthropic's own published cost-performance curves on BrowseComp and OSWorld-Verified show Sonnet 5 at x-high effort performing roughly in line with Fable 5 at medium-to-high effort on both benchmarks. That means the quality gap between the two models is smaller than it appears at equivalent effort levels when you allow Sonnet 5 to think harder. But it also means running Sonnet 5 at x-high is potentially more expensive than running Fable 5 at medium on some tasks. The key question for production routing: are you paying Fable 5 prices for Fable 5 quality, or are you paying Fable 5 prices for Sonnet 5 thinking harder? The former is efficient. The latter is the expensive mistake. Run the effort level math on your specific task distribution before setting x-high as your default.
7. Benchmark Deep Dives: The Dimensions That Actually Matter
Coding: SWE-bench Pro Is the Decisive Benchmark
SWE-bench Pro, which uses contamination-resistant test sets from actively maintained repositories, is the benchmark that most accurately reflects production coding capability. The 17-point gap between Fable 5 (80.3%) and Sonnet 5 (63.2%) is the largest published capability gap between these two models and the one that most directly affects production output quality. What does 17 points on SWE-bench Pro mean in practice? At 80.3%, Fable 5 resolves 8 out of every 10 hard GitHub issues it attempts. At 63.2%, Sonnet 5 resolves 6.3 out of 10. On a 100-task batch of genuinely hard production coding issues, Fable 5 delivers approximately 17 more successful resolutions than Sonnet 5. Each failed Sonnet 5 resolution either requires a human to complete the task, a retry loop that adds cost, or acceptance of a suboptimal solution. The economic argument for Fable 5 on these tasks is not about the per-token price. It is about whether the per-task success rate difference justifies the per-token premium.
The honest framing: for tasks that are medium-difficulty in real production codebases, that 17-point gap compresses or disappears because both models succeed. The gap is most real and most meaningful at the hardest end of the coding task distribution: large multi-file refactors with complex dependency chains, overnight autonomous agents working through frontier-difficulty bugs, codebase migrations across hundreds of files where each decision has downstream consequences. For the full coding benchmark comparison including GLM-5.2 and GPT-5.6 at similar price points, the GLM-5.2 vs Claude Opus 4.8 vs GPT-5.6 vs Kimi comparison covers the full competitive landscape.
Terminal and CLI: Where Sonnet 5 Wins
Terminal-Bench 2.1 measures autonomous terminal-based workflows: file operations, command execution, multi-step scripting, environment management. Sonnet 5 scores 80.4%, beating Claude Opus 4.8's 74.6% by a meaningful margin. Fable 5's Terminal-Bench 2.1 score has not been published by Anthropic, but GPT-5.6 Sol Ultra's 91.9% sets the current ceiling. The practical implication: for CLI automation, shell scripting, DevOps tooling, and terminal-native agent workflows, Sonnet 5 is not just good enough, it is genuinely the better choice among the two Claude models at this task category, independent of price.
Knowledge Work: The Narrow Sonnet 5 Edge
GDPval-AA v2 measures AI performance across 44 professional occupations including software engineers, lawyers, nurses, and financial analysts. Sonnet 5 at 1,618 Elo edges Fable 5's estimated 1,615 Elo. The gap is narrow and likely within noise range, but the direction is worth noting: for the professional knowledge work that occupies most of the working day of most users, Sonnet 5 delivers equivalent or marginally better output than Fable 5 at dramatically lower cost. This is the most direct evidence that Fable 5's premium is not evenly distributed across all task types.
Mathematical Reasoning: Fable 5's Clearest Advantage
USAMO 2026 shows Fable 5 well ahead of Sonnet 5's 79.5%. For teams doing frontier mathematics, formal theorem proving, complex quantitative modeling, or scientific reasoning at the absolute edge of model capability, Fable 5's mathematical reasoning ceiling is meaningfully higher. This is the use case where the Fable 5 premium is most clearly justified.
A note on the 25 prompts test: your Fable 5 prompts post (1,262 views) demonstrated that many capabilities are best understood through direct testing rather than benchmark reading. The 25 Claude Fable 5 prompts to test every capability gives you a practical testing framework to compare both models on your specific task types before committing to a routing decision.
8. Latency and User Experience
Fable 5 is described as slow to first token and built for long-horizon asynchronous work. This is not a bug; it is an architectural choice reflecting the model's purpose. When you run Fable 5 on a hard multi-file coding task, the model spends meaningful time planning before it outputs. That planning is what produces 80.3% SWE-bench Pro. But it makes Fable 5 a poor fit for anything a user is actively waiting on in real time. Sonnet 5 is genuinely faster at mid-tier latency. It is the right choice for: interactive coding assistants where developers need responses within seconds, customer-facing chat applications where generation latency affects user experience, real-time document analysis where a user is watching the response arrive, and autocomplete or inline suggestion features where sub-second response is the expectation. The practical workflow separation this creates: use Sonnet 5 for the interactive layers of your product (the chat interface, the inline suggestions, the quick drafts) and use Fable 5 for the non-interactive layers (the overnight refactor, the CI pipeline check, the autonomous bug investigation that runs while the developer does other work). The latency difference between the models maps almost perfectly onto the synchronous vs asynchronous job distinction.
9. Safety: What Changed with Fable 5's Return
Fable 5 returned on July 1 with a new cybersecurity safety classifier that blocks the Amazon-reported jailbreak technique in over 99% of cases. The documented trade-off is higher false-positive rates on benign coding and debugging tasks with security-adjacent framing. Blocked requests fall back to Opus 4.8 rather than Sonnet 5. For most workflows, this does not change the Fable 5 vs Sonnet 5 decision. For security-adjacent workflows, it does. Sonnet 5 ships with the same cybersecurity safeguards as Opus 4.7 and 4.8, which are less strict than Fable 5's new post-return classifier. Anthropic's own published safety guidance: for security research that requires reduced guardrails, reach for Opus 4.8 rather than either Fable 5 or Sonnet 5. Sonnet 5's prompt-injection attack resistance is meaningfully better than Sonnet 4.6 (0.93% attack success rate in browser-use testing versus 31.5% for Opus 4.8 without safeguards), making it the safer choice for automated workflows operating in less controlled environments. The safety decision tree: if your workload has no security-adjacent components, the new Fable 5 classifier is invisible. If your workload involves security tooling, Sonnet 5 or Opus 4.8 gives you fewer false-positive disruptions right now, while Anthropic works on the refinements it has promised.
For the complete story on the Fable 5 safety classifier, the Amazon jailbreak, and the four commitments Anthropic made to get the ban lifted, the Claude Fable 5 is back: what changed review covers every detail of the return.
10. The Routing Framework: When to Use Which
The practical framework, stated as a decision tree you can apply at the task level:
Run Sonnet 5 first, always.
- Default every task to Sonnet 5 at medium effort. This is the correct economic and quality choice for the majority of tasks.
- If Sonnet 5 fails or produces clearly insufficient output, escalate to Fable 5 rather than running Sonnet 5 again at higher effort. At x-high effort, Sonnet 5 can approach Fable 5 cost without matching Fable 5 quality on the hardest problems. Fable 5 at medium effort on a hard task is often better economics than Sonnet 5 at x-high.
- Escalate directly to Fable 5 (skip Sonnet 5) for: tasks you have empirically identified as falling in the top 10% difficulty range based on your own benchmark data, overnight autonomous agent jobs where human review is not immediate, and complex multi-file refactors across large codebases where a failed run costs more than the token delta.
- Use Opus 4.8 or Sonnet 5 instead of Fable 5 for: security-adjacent coding tasks where the new Fable 5 classifier's false positive rate is disruptive, real-time interactive features where latency matters, and any pipeline where Fable 5's 50% usage cap (through July 7) or credit requirement creates workflow interruptions.
The 80/20 allocation that most teams end up at after calibrating: 80 to 90% of API calls go to Sonnet 5 at medium effort, 10 to 20% escalate to Fable 5 for the identified hard cases. This allocation gives you the economics of Sonnet 5 pricing for the majority of your volume while preserving Fable 5 quality where it demonstrably matters. The specific ratio shifts based on your workload: more coding at the hard end means more Fable 5; more knowledge work, writing, and real-time interaction means less Fable 5. For the full cross-model comparison including GPT-5.6 Sol/Terra/Luna which begins general availability in mid-July 2026, the best AI models of July 2026 guide covers every tier of the competitive landscape simultaneously.
11. The September 1 Cliff: Planning for Standard Pricing
Sonnet 5's introductory $2/$10 pricing ends on August 31, 2026. September 1 brings the $3/$15 standard rate, which is the same rate card as Sonnet 4.6. Two things you need to do before August 31 to avoid surprises:
- Benchmark your real token consumption now, not the rate card. Because of the 1.33x tokenizer multiplier, your September cost at $3 input is not 50% more than your current $2 cost. It is approximately 100% more for English text ($3 rate times 1.33x tokens versus $2 rate). Run actual API calls on your production prompt set and measure token counts before and after migration to get the real number.
- Decide your September routing strategy before August 31. If GPT-5.6 Terra reaches general availability in mid-July as expected, it will be priced at $2.50/$15 standard, competing directly with Sonnet 5 at its September pricing. Model your September cost at standard Sonnet 5 pricing and compare it against GPT-5.6 Terra, GLM-5.2 at $1.40/$4.40, and other alternatives before the introductory window closes.
The current opportunity: the window between now and August 31 is the most favorable Sonnet 5 pricing this model will ever be available at. For teams that want to migrate from Sonnet 4.6, Opus 4.8, or even Fable 5 and validate the new workflow before standard pricing kicks in, the next 60 days is exactly the right window. The tokenizer migration, the effort level calibration, and the routing decisions should all be done now so they are production-validated before the September 1 cliff. If you are not yet running on Claude Sonnet 5 for your production workloads, there is no better time than today through August 31 to test and validate.
Frequently Asked Questions
Is Claude Fable 5 worth the extra cost over Sonnet 5?
For most professional workflows: no. Sonnet 5 ties or edges Fable 5 on GDPval-AA knowledge work, beats it on Terminal-Bench 2.1, and nearly ties it on BrowseComp agentic research. For the hardest coding tasks specifically (SWE-bench Pro: 80.3% vs 63.2%), Fable 5's quality advantage is real and can justify the 3 to 5x premium when a failed task costs more than the token delta. Run the cost-per-completed-task math on your actual workload rather than the per-token rate card.
Which Claude model is better for coding in July 2026?
For everyday production coding (medium-difficulty bugs, refactors, code review, documentation): Sonnet 5 is the better value and sufficient quality. For the hardest production coding (large multi-file refactors, frontier-difficulty bugs, overnight autonomous agents): Fable 5's 17-point SWE-bench Pro lead produces meaningfully better task completion rates. The recommended routing: default to Sonnet 5, escalate specifically identified hard tasks to Fable 5.
Does Sonnet 5 beat Fable 5 on any benchmarks?
Yes, on three published benchmarks. Terminal-Bench 2.1: Sonnet 5 at 80.4% beats Opus 4.8's 74.6% reference (Fable 5's score is unpublished, but the Sonnet 5 advantage over the Opus reference is documented). GDPval-AA v2 knowledge work: Sonnet 5 at 1,618 Elo edges Fable 5's estimated 1,615. HLE with tools: Sonnet 5 at 57.4% nearly ties Opus 4.8 at 57.9%, suggesting it is in the same range as Fable 5 on this benchmark. These results reflect a consistent pattern: Sonnet 5 is competitive or better on workflow-tool-use tasks and falls behind on raw reasoning depth without tools.
What is the real price difference between Fable 5 and Sonnet 5?
Rate card: Fable 5 is 5x more expensive than Sonnet 5's introductory rate and 3.33x more expensive than the September 1 standard rate. Effective rate after tokenizer inflation: Sonnet 5's 1.33x more tokens per task for English text raises the effective cost to approximately $2.65 input and $13.30 output per million tokens during the introductory window. Fable 5's effective cost advantage over Sonnet 5 after tokenizer adjustment is approximately 3.8x on input and 3.3 to 4x on output in practice.
When does the Sonnet 5 introductory pricing end?
August 31, 2026. From September 1, 2026, Sonnet 5 moves to standard pricing of $3 per million input tokens and $15 per million output tokens. After the tokenizer multiplier of approximately 1.33x for English, effective September costs are approximately $3.99 input and $19.50 output per million semantic tokens. Budget for roughly double your current introductory-period cost when planning September and beyond.
Is Claude Fable 5 faster or slower than Sonnet 5?
Fable 5 is slower to first token and is designed for long-horizon asynchronous work. Sonnet 5 has better latency for interactive use cases. For real-time chat, autocomplete, inline suggestions, and any workflow where a human is actively waiting for the response, Sonnet 5 is the right choice. For overnight autonomous agent runs, batch processing, and heavy agentic tasks where the model works independently without a user watching, Fable 5's latency profile is appropriate for the use case.
Can I run both Fable 5 and Sonnet 5 in the same Claude plan?
Yes. Both are available on Max, Team, and Enterprise plans. On Pro plans, both are available with Fable 5 subject to the 50% weekly usage cap through July 7, 2026, after which it moves to usage credits. Sonnet 5 is the default model on Free and Pro plans with standard message limits. API customers can switch between model IDs (claude-fable-5 and claude-sonnet-5) within the same account and API key.
Recommended Blogs
- Claude Fable 5 Review: Price, Benchmarks & API (original pre-ban review)
- Claude Sonnet 5 Review: Benchmarks, Pricing and Is It Worth It? (2026)
- Claude Fable 5 Is Back: What Changed, What's New & Should You Upgrade?
- Best AI Models of July 2026: Full Ranking by Use Case, Benchmarks, and Price
- 25 Claude Fable 5 Prompts to Test Every Capability (2026)
- Claude AI Complete Hub: Every Anthropic Model and Product Update
Resources & Community
Join our community of 70,000+ AI enthusiasts and learn to build powerful AI applications! Whether you're a beginner or an experienced developer, Build Fast with AI helps you understand and implement AI in your projects.
- Website: buildfastwithai.com
- LinkedIn: Build Fast with AI
- Instagram: @buildfastwithai
- Founder Twitter: @satvikps
- Twitter: @BuildFastWithAI
Agentic AI Launchpad 2026
A structured 6-week cohort program that takes you from AI basics to building and deploying real-world agentic AI systems. Includes live sessions, expert mentorship, project reviews, and a builder community network.
Ready to go from learning to building? Join the next cohort: Agentic AI Launchpad 2026
Free AI Resources
Access free tools, workshops, and micro-learning to keep building:
- AI Workshops: Free resources, upcoming events and past recordings
- Unrot: Learn AI in 5 minutes a day (free micro-learning app)
The Anthropic model lineup is changing fast. Follow @BuildFastWithAI on X to stay ahead of every benchmark, pricing change, and access update that affects your Claude workflows.
References
- Anthropic: Claude Sonnet 5 System Card (all Sonnet 5 benchmark figures)
- Anthropic: Introducing Claude Sonnet 5 (June 30, 2026 launch post)
- Anthropic: Redeploying Claude Fable 5 (July 1, 2026)
- Lushbinary: Claude Fable 5 vs Claude Sonnet 5: When to Use Each
- CodingFleet: Claude Fable 5 vs Claude Sonnet 5 (SWE-bench Pro, Terminal-Bench, pricing analysis)
- DataCamp: Claude Sonnet 5: Features, Benchmarks, and Pricing
- BenchLM: Claude Fable 5 vs Claude Sonnet 5 AI Benchmark Comparison 2026
- Digital Applied: Sonnet 5 vs Opus 4.8 vs Fable 5: Which to Use When
- Morph LLM: Claude Benchmarks 2026 (full Claude family SWE-bench and Terminal-Bench scores)
- CodingFleet: Claude Sonnet 5 vs GPT-5.5 (Terminal-Bench 2.1 scores and tokenizer analysis)
- CallMissed: Claude Sonnet 5 vs Fable 5: Benchmarks, Pricing, and Best Use
Bravenewcoin: What AI Model Should I Use? The 2026 Guide (Claude Sonnet 5 and Fable 5 context)

