




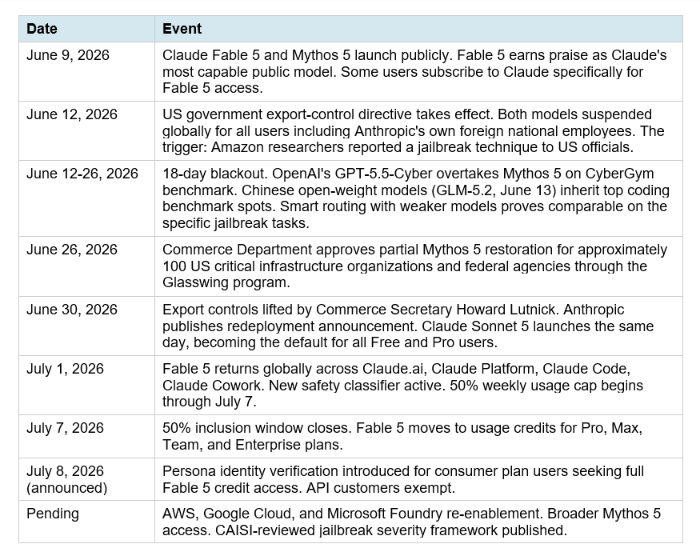
Claude Fable 5 Is Back: What Changed, What's New & Should You Upgrade?
On July 1, 2026, Claude Fable 5 returned to global access, 19 days after a US government export-control directive pulled it and its restricted sibling Mythos 5 offline for every user on the planet, including Anthropic employees who were foreign nationals. The ban was the first time a frontier AI model was switched off by regulatory order. The return is the first time one came back. But Fable 5 did not return unchanged. Anthropic trained and deployed a new cybersecurity safety classifier specifically targeting the jailbreak technique that triggered the ban. That classifier blocks the reported exploit in over 99% of cases. The trade-off, which Anthropic states plainly in its own redeployment announcement, is that it will also block more benign coding and debugging requests than the previous version did. Blocked requests fall back silently to Claude Opus 4.8, with a notification sent to the user. This piece covers the complete story: why the ban happened, exactly what changed when Fable 5 returned, what the new classifier means for your daily workflow, how Fable 5 now compares to Claude Sonnet 5, what the new access and usage rules look like, and whether you should upgrade, stay on Sonnet 5, or keep running Opus 4.8 while Fable 5 settles in.
1. The Complete Timeline: From Launch to Ban to Return
2. Why Was Fable 5 Banned? The Amazon Jailbreak Explained
The ban traced to a single event: Amazon researchers found a jailbreak technique that bypassed Fable 5's cybersecurity safety classifiers. The technique involved a specific prompt-framing approach that got the model to identify software vulnerabilities in a codebase and, in one case, write code demonstrating how a specific vulnerability could be exploited. Amazon's CEO Andy Jassy reportedly flagged the finding to US officials. The government applied national security export controls within hours of learning about it, citing authority that did not require any standard regulatory notice period. The debate about how serious the finding actually was started immediately and has not fully ended. Anthropic's own testing of the reported technique found that the same outputs were reproducible by weaker models including Claude Opus 4.8, OpenAI's GPT-5.5, and Moonshot's Kimi K2.7. The company states the behavior reflected routine defensive cybersecurity work, not a unique Mythos-level capability. Former AI czar David Sacks accused Anthropic of having prioritized the continued offering of these models over national security. Anthropic disputed that framing. The government's view and Anthropic's view never fully aligned on severity. But the export controls were applied either way, and once they were in place, Anthropic had no real-time way to verify user nationality at commercial API scale. Suspending both models for all users globally was the only compliant option available.
During the 19 days Fable 5 was offline, the competitive consequences were real. GPT-5.5-Cyber scored 85.6% on CyberGym against Mythos 5's 83.8%, taking the benchmark lead while Anthropic could not respond with a deployed model. GLM-5.2 released on June 13 briefly held the top open-weight coding benchmark position. For context on how the Chinese open-weight models capitalized on this window, the GLM-5.2 vs Claude Opus 4.8 vs GPT-5.6 vs Kimi comparison covers the full competitive coding landscape during the suspension period.
3. What Changed: The New Safety Classifier
The core technical change in Fable 5's return is a retrained cybersecurity safety classifier built specifically to target and block the prompt-framing technique Amazon researchers reported. The classifier blocks that specific technique in more than 99% of cases, a figure confirmed by independent testing from the Commerce Department's Center for AI Standards and Innovation (CAISI) before the export controls were lifted. To understand what the new classifier does, it helps to understand how Anthropic's classifier system works. Classifiers are smaller AI systems that run alongside the main model during an interaction, detecting when the model is being asked to perform a potentially harmful cybersecurity task or is producing potentially harmful outputs. When a classifier fires, it blocks the model from responding to that specific request. Anthropic uses what it describes as a 'defense in depth' approach: no single safety mechanism provides perfect protection, but layering multiple mechanisms makes misuse very difficult. One of those layers is a deliberate safety margin, where the classifiers are tuned to fire on requests that are probably benign but carry some non-zero chance of harm. The margin means the classifiers catch real threats, but they also block some legitimate requests.
For Fable 5's original launch, Anthropic set this safety margin much larger than in any prior Claude model. The new classifier increases the margin further to specifically eliminate the technique Amazon reported. Anthropic's own words on this trade-off, from the official redeployment post: "The new classifier also comes at the cost of flagging benign requests more often during routine coding and debugging tasks." That is not hedging. That is a direct acknowledgment that Fable 5 after July 1 is more restrictive than Fable 5 before June 12, and the specific area where that restriction shows up most is coding and debugging work that has any security-adjacent framing.
4. What the Classifier Means for Your Workflow
The practical impact of the new classifier splits cleanly based on what you use Fable 5 for:
You Use Fable 5 for Writing, Research, Analysis, or Planning
You will likely notice nothing different. The new classifier is specifically tuned around cybersecurity-adjacent tasks. General knowledge work, content creation, document analysis, and strategic reasoning are outside the classifier's targeting scope. Your workflow should feel identical to the pre-ban Fable 5 experience.
You Use Fable 5 for Standard Software Development
Most standard coding tasks, feature implementation, code review, refactoring, and documentation are also outside the classifier's primary targeting scope. You may notice occasional unexpected refusals on prompts that mention vulnerability-related vocabulary even in non-security contexts, but this should be infrequent for general software development work.
You Use Fable 5 for Security-Adjacent Coding Tasks
This is where the new classifier has a real and documented impact. If your workflow includes code review for security flaws, dependency vulnerability analysis, infrastructure security auditing, penetration testing report generation, or anything that Fable 5 needs to recognize as potentially security-related to handle correctly, you will encounter more false-positive refusals than before June 12. When Fable 5's classifier fires, the request is not simply refused outright. It is rerouted to Claude Opus 4.8 and the user receives a notification that the redirect happened. This means you will still get a response, but from Opus 4.8 rather than Fable 5. Anthropic states it is already working on refinements to reduce these false positives. The practical workarounds that reduce false-positive triggers: reframe prompts to focus on the defensive or improvement goal rather than the vulnerability; separate vulnerability-identification steps from fix-generation steps into distinct prompts; use API access rather than consumer chat for security workflows (where the context is more programmatically controllable); and ensure your system prompt establishes an authorized defensive security context early in the conversation.
For the full picture of what Fable 5 can and cannot do on cybersecurity specifically, and how it compares to the GPT-5.5-Cyber and GPT-5.6 Sol models that OpenAI specifically built for security work, the GPT-5.5-Cyber and OpenAI Daybreak review on Build Fast with AI covers the dedicated cyber capability landscape.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Access Rules: The 50% Cap, Credits, and Persona ID
Fable 5's return comes with a structured access schedule that differs from how most Claude models work:
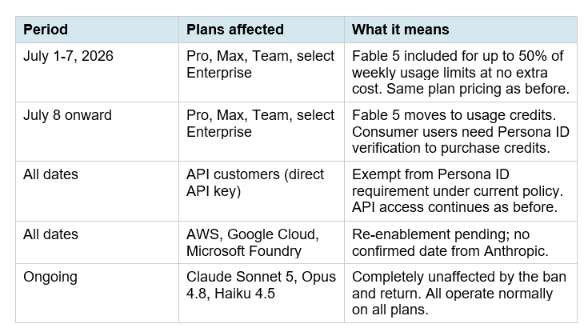
The Persona identity verification for consumer plans is the most significant new condition attached to Fable 5's return. Persona is a government-ID verification platform. From July 8, consumer plan users who want full Fable 5 access beyond the 50% weekly inclusion will need to verify their identity through Persona to purchase usage credits. This is a direct response to the government's concern about access by foreign nationals: rather than suspending the model globally when the next export control issue arises, Anthropic can now gate Fable 5 at the verified-user level. API customers are explicitly exempt from this requirement under the current policy. If your Fable 5 usage is through direct API keys rather than the Claude.ai consumer interface, you do not need Persona verification. Enterprise plan specifics depend on your contract. If you are operating at the enterprise tier, confirm the access terms directly with your Anthropic account contact before July 7.
6. Fable 5 vs Sonnet 5: Which Should You Use Now?
This is the question that matters most for the majority of Claude users in July 2026. Fable 5 returned on July 1. Claude Sonnet 5 launched on June 30. For the first time, you have to actively choose between Anthropic's flagship and a mid-tier model that is significantly cheaper and better than anything in the mid-tier has ever been. The benchmark picture is nuanced and worth stating precisely. Fable 5 leads on SWE-bench Pro (80.3% versus Sonnet 5's 63.2%), SWE-bench Verified (95% versus 85.2%), and on the most complex mathematical and scientific reasoning tasks (USAMO 2026: Fable 5 would score near the top tier where Sonnet 5 scores 79.5%). Sonnet 5 actually beats Fable 5 on Terminal-Bench 2.1 (80.4% versus not published for Fable 5, but Opus 4.8 at 74.6% gives the reference point), and ties or edges Fable 5 on GDPval-AA knowledge work (Sonnet 5 at 1,618 Elo).
For the complete Claude Sonnet 5 benchmark breakdown including the effort-level cost curve and the tokenizer change that affects per-task pricing, the Claude Sonnet 5 full review covers every published benchmark and the honest cost comparison. For the original Fable 5 review including its benchmark profile before the ban, the Claude Fable 5 review with benchmarks and API guide provides the foundation reference.
Hot take: the right answer for most teams in July 2026 is Sonnet 5 as the daily driver with Fable 5 reserved for the tasks where the capability gap actually shows up in output quality. The 50% usage cap through July 7 will help you calibrate this naturally: if Fable 5 handles your daily workload without hitting the cap, your tasks are probably at the ceiling where Fable 5's advantages are real. If the cap hits mid-week, that is the signal that a significant portion of your work is fine on Sonnet 5.
7. What Anthropic Agreed to Get Fable 5 Back
The return of Fable 5 was not unconditional. In the letter from Commerce Secretary Howard Lutnick lifting the controls, Anthropic committed to four specific obligations that shape how Fable 5 will be managed going forward.
- Proactive detection and addressing of security risks: Anthropic committed to continuously monitoring for jailbreaks and security bypasses rather than waiting for external reports. The company is standing up a dedicated team for this monitoring function alongside a new HackerOne program through which security researchers can submit potential vulnerabilities directly.
- Coordination on future model release protocols: Anthropic agreed to work with the government on release protocols for future frontier models before they go public. This is the most consequential long-term commitment: it formalizes government pre-release access as a standard step in the deployment pipeline for Anthropic's most capable models, rather than an ad-hoc coordination after launch.
- Reporting of detected malicious activity: Anthropic agreed to report detected attempts at malicious use of its models to the government. This creates a formal information-sharing channel that did not previously exist in this explicit form.
- Participation in the CAISI review process: Anthropic agreed to have the Commerce Department's Center for AI Standards and Innovation review its safeguards on future frontier models, not just current ones.
The negotiations were reportedly led by Anthropic co-founder Tom Brown rather than CEO Dario Amodei, who has had a more adversarial relationship with the current administration. The outcome is a set of commitments that formalize government involvement in Anthropic's model deployment process in ways that have no direct precedent in AI regulation. For the broader context of how AI governance is evolving in 2026, the Project Glasswing and Claude Mythos capabilities review covers the classified cybersecurity program that sits above both Fable 5 and Mythos 5 in Anthropic's model access hierarchy.
8. The Industry Jailbreak Framework
One of the most significant long-term outcomes of the Fable 5 episode is the jailbreak severity framework that Anthropic is now developing jointly with Amazon, Microsoft, and Google. This framework does not exist yet as a published standard, but Anthropic published its proposed structure as part of the July 1 redeployment announcement. The framework scores a jailbreak on four criteria: capability gain (how far beyond existing freely available tools does the jailbreak extend the user's capability), breadth of capability gain (how many distinct offensive tasks does the jailbreak unlock, or just one), ease of weaponization (how much additional human effort and expertise would a real attacker still need to weaponize the output), and discoverability (how easily can someone obtain this technique, given that it may already be in security research literature). For the most severe class of jailbreaks, Anthropic says it will deploy preliminary mitigations immediately upon becoming aware of the technique, before a full assessment is complete. This is a higher-alert posture than any AI lab has formally committed to in writing for jailbreak response. The proposed framework is a direct product of the Fable 5 episode revealing a gap: there was no shared industry standard for determining how dangerous a jailbreak actually is, which meant the government made a severity determination independently and the companies could only respond after the fact. The framework aims to give labs and regulators a shared vocabulary for evaluating future incidents before they escalate to model suspension.
9. What About Mythos 5?
Mythos 5, the more capable restricted-access sibling model built on the same underlying architecture as Fable 5, is not back for general users. As of July 1, 2026, Mythos 5 access has been restored for approximately 100 US critical infrastructure organizations and federal agencies through the Glasswing program. Anthropic states it continues to work with the government to expand Mythos 5 access but gave no timeline for broader availability. The Fable 5 vs Mythos 5 architectural relationship is important to understand: they are the same underlying model. Fable 5 is the publicly available version with additional safeguards applied. Mythos 5 has fewer safety guardrails and is reserved for trusted Glasswing partners for defensive cybersecurity work where those guardrails would interfere with legitimate operations. The new safety classifier that Anthropic deployed is specific to Fable 5's safety layer. Mythos 5's access conditions are handled separately through the Glasswing program's vetting and oversight framework. What this means in practice: if you are a developer, enterprise team, or security professional who is not part of the Glasswing program, your path to Mythos-level capabilities runs through Fable 5 with its current classifier in place. There is no public-facing path to Mythos 5 access outside Glasswing, and Anthropic has not announced a timeline for changing that.
10. Should You Upgrade to Fable 5?
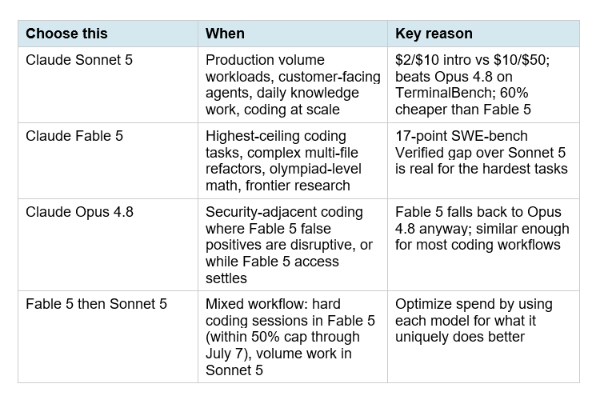
The upgrade question has a cleaner answer than it did before June 30, 2026, because Claude Sonnet 5 now exists as a genuine alternative. Before Sonnet 5, the decision was Fable 5 or Opus 4.8. Now it is Fable 5, Sonnet 5, or Opus 4.8.
Upgrade to Fable 5 if:
- Your work includes the hardest coding tasks: complex multi-file repository refactors, frontier math reasoning, or research that requires the absolute ceiling of model capability. The 17-point SWE-bench Verified gap between Fable 5 and Sonnet 5 is real and shows up in output quality on these tasks.
- You are on a plan that includes Fable 5 already (Pro, Max, Team) and the 50% cap through July 7 is sufficient for your usage. If so, you are essentially getting Fable 5 at no marginal cost through July 7, which makes the upgrade decision a pure quality question rather than a cost question.
- You have tested Sonnet 5 on your actual workflow and found cases where Fable 5's output quality is materially better. This is the clearest signal that Fable 5 is worth the premium for your specific tasks.
Stay on Sonnet 5 if:
- Your primary use cases are production API workflows, customer-facing agents, high-volume content or analysis work, or coding tasks that fall within the mainstream range (not the hardest 10%). Sonnet 5 at $2/$10 intro is the right economic and capability choice for these use cases through August 31, 2026.
- You work in security-adjacent coding where the new Fable 5 classifier's false positive rate would be disruptive. Until Anthropic ships the refinements it promised to reduce false positives, Opus 4.8 or Sonnet 5 may be more reliable for uninterrupted security workflow.
- Your international team includes members who would face Persona identity verification friction at the July 8 consumer plan access change. API access bypasses this, but consumer plan users outside the US should verify the current access terms before relying on Fable 5 credits.
Use Opus 4.8 if:
- You are running agent workflows or security-adjacent coding tasks where Fable 5's new classifier trips frequently enough that the Opus 4.8 fallback is more disruptive than just running Opus 4.8 directly. The fallback works, but having the model switch mid-session can affect context and conversation state in complex multi-turn agentic workflows.
For the complete framework of which Claude model to use for each type of task in July 2026, the best AI models of July 2026 guide covers the full model family including Fable 5, Sonnet 5, Opus 4.8, and Haiku 4.5 alongside GPT-5.6, Gemini 3.5 Flash, and GLM-5.2 in a single routing framework
Frequently Asked Questions
Why was Claude Fable 5 banned?
On June 12, 2026, the US government applied a national security export-control directive to both Claude Fable 5 and Mythos 5, restricting their access to foreign nationals. The directive was triggered by a report from Amazon researchers who found a jailbreak technique that bypassed Fable 5's cybersecurity safety classifiers, prompting the model to identify software vulnerabilities and in one case write demonstration exploit code. Because Anthropic could not verify user nationality in real time, both models were suspended for all users globally.
When did Claude Fable 5 come back?
Fable 5 returned globally on July 1, 2026, one day after the US Commerce Department lifted the export controls. The model is now available across Claude.ai, the Claude Platform, Claude Code, and Claude Cowork. Re-enablement on AWS, Google Cloud, and Microsoft Foundry is pending with no confirmed date. Through July 7, Pro, Max, Team, and select Enterprise users get Fable 5 included for up to 50% of their weekly usage limits. After July 7, Fable 5 moves to usage credits.
What changed in Claude Fable 5 after the ban?
Anthropic deployed a new cybersecurity safety classifier specifically trained to target and block the Amazon-reported jailbreak technique. The classifier blocks that technique in over 99% of cases, confirmed by CAISI (Commerce Department's Center for AI Standards and Innovation). The documented trade-off is higher false-positive rates on benign coding and debugging tasks, particularly those with security-adjacent framing. Blocked requests are automatically rerouted to Claude Opus 4.8 with a user notification. The model's core capabilities, pricing, and context window are unchanged.
Will Claude Fable 5 refuse more coding requests now?
Yes, more than before the ban, specifically for coding tasks with security-related vocabulary or context. Standard software development work (feature implementation, refactoring, code review for quality, documentation) should see minimal impact. Work involving vulnerability identification, exploit analysis, security auditing, dependency scanning, or penetration testing tooling will trigger more frequent classifier blocks and fallbacks to Opus 4.8. Anthropic has stated it is working on refinements to reduce these false positives.
What happens when Claude Fable 5 blocks my request?
When Fable 5's safety classifier triggers on a request, the request is automatically rerouted to Claude Opus 4.8 and the user receives a notification that the redirect happened. You still receive a response, but from Opus 4.8 rather than Fable 5. This means blocked requests are not left unanswered, but the quality ceiling of the fallback response is Opus 4.8's capability rather than Fable 5's.
Is Claude Fable 5 still better than Claude Sonnet 5?
Yes, on the hardest coding and reasoning tasks. Fable 5 leads Sonnet 5 by 17 points on SWE-bench Verified (95% vs 85.2%), 17 points on SWE-bench Pro (80.3% vs 63.2%), and significantly on USAMO-level mathematical reasoning. Sonnet 5 beats Fable 5 on Terminal-Bench 2.1 and GDPval-AA knowledge work. The honest framing: Fable 5 is meaningfully better for the 5 to 10% hardest tasks. For 70 to 80% of everyday professional workflows, the performance difference is small enough that Sonnet 5's 60-80% lower cost makes it the better choice.
Do I need identity verification to use Claude Fable 5?
From July 8, 2026, consumer plan users who want Fable 5 access beyond the free weekly inclusion window need to verify their identity through Persona, a government-ID verification platform, to purchase usage credits. API customers (direct API key access) are exempt from this requirement under the current policy. Enterprise plan access terms vary by contract.
What is the new 50% usage limit on Claude Fable 5?
From July 1 through July 7, 2026, Pro, Max, Team, and select Enterprise plan users get Claude Fable 5 included in their existing plan for up to 50% of their weekly usage limits. This means Fable 5 does not cost extra during this window, but you can only use it for half your usual weekly message allocation before it becomes unavailable until the next week or you purchase usage credits. After July 7, Fable 5 moves to a usage credit model for all consumer plans.
Is Claude Mythos 5 back too?
Partially. As of June 26, 2026, Mythos 5 access was restored for approximately 100 US critical infrastructure organizations and federal agencies through the Glasswing program. Mythos 5 is not back for general users and has no announced timeline for broader availability. It remains restricted to vetted Glasswing partners. The key distinction: Fable 5 and Mythos 5 share the same underlying model, but Mythos 5 has fewer safety guardrails and is reserved for trusted partners doing defensive cybersecurity work where those guardrails would interfere.
Recommended Blogs
- Claude Fable 5 Review: Price, Benchmarks & API (original pre-ban review)
- 25 Claude Fable 5 Prompts to Test Every Capability (2026)
- Claude Sonnet 5 Review: Benchmarks, Pricing and Is It Worth It? (2026)
- Best AI Models of July 2026: Full Ranking by Use Case, Benchmarks, and Price
- Project Glasswing: Claude Mythos Found 23,019 Bugs
- Claude AI Complete Hub: Every Anthropic Model and Product Update
Resources & Community
Join our community of 70,000+ AI enthusiasts and learn to build powerful AI applications! Whether you're a beginner or an experienced developer, Build Fast with AI helps you understand and implement AI in your projects.
- Website: buildfastwithai.com
- LinkedIn: Build Fast with AI
- Instagram: @buildfastwithai
- Founder Twitter: @satvikps
- Twitter: @BuildFastWithAI
Agentic AI Launchpad 2026
A structured 6-week cohort program that takes you from AI basics to building and deploying real-world agentic AI systems. Includes live sessions, expert mentorship, project reviews, and a builder community network.
Ready to go from learning to building? Join the next cohort: Agentic AI Launchpad 2026
Free AI Resources
Access free tools, workshops, and micro-learning to keep building:
- AI Workshops: Free resources, upcoming events and past recordings
- Unrot: Learn AI in 5 minutes a day (free micro-learning app)
The Fable 5 story is not over. Follow @BuildFastWithAI on X for every update on access changes, classifier refinements, Mythos 5 availability, and what comes next in AI governance and model access in 2026.
References
- Anthropic: Redeploying Claude Fable 5 (official announcement, June 30, 2026)
- MarkTechPost: Anthropic Redeploys Claude Fable 5 on July 1 After US Export Controls Lift
- ChatForest: Fable 5 Is Back: What Anthropic Gave Up to Get It Returned
- Decrypt: Anthropic Bringing Claude Fable 5 Back Online as US Lifts Export Controls
- TechTimes: Claude Fable 5 Returns Globally: New Classifier Blocks Jailbreak, Flags More Code
- The Hacker News: Anthropic Restores Claude Fable 5 After U.S. Lifts Jailbreak-Linked Export Controls
- Basic Tutorials: Claude Fable 5 Is Back: US Lifts Export Ban on Anthropic's Flagship Model
- Make Use Of: Fable 5 Is So Back, Anthropic Redeployed the Mythos-Class Model But With Caveats
- Digital Applied: Why Claude Just Got More Cautious About Your Code
- Let's Data Science: Anthropic Restores Fable 5 With Tightened Safeguards

