




ZAYA1-8B: The Efficient MoE Reasoning Model That Punches Far Above Its Weight
A model with under one billion active parameters just scored 91.9% on AIME'25 — a math olympiad benchmark where most frontier models top out around 90%. It nearly matched GPT-5-High on HMMT'25. And it runs on hardware that would struggle with models ten times its size. That model is ZAYA1-8B, released by Zyphra on May 6, 2026, and it may be the clearest proof yet that we are entering the era of intelligence density over raw scale.
What Is ZAYA1-8B?
ZAYA1-8B is a Mixture-of-Experts (MoE) language model from Zyphra, optimized for maximum reasoning performance per active parameter. With 8 billion total parameters but under 1 billion active per token, it achieves competitive scores on math, coding, and reasoning benchmarks against models that are 30 to 100 times larger.
Unlike most frontier models that are either fully dense or operate on tens of billions of active parameters, ZAYA1-8B takes a different path. To understand why this architecture matters, the Mixture of Experts (MoE) explained guide on Build Fast with AI covers the core mechanics: a router decides which small subset of expert sub-networks handles each token, keeping compute low while total knowledge capacity remains high.
ZAYA1-8B was trained entirely on AMD Instinct MI300X GPUs — a 1,024-GPU cluster with AMD Pensando Pollara networking on IBM Cloud. This makes it one of the first frontier-class reasoning models built without a single Nvidia GPU in the training stack. The implication is significant: it demonstrates that high-quality reasoning model training is no longer exclusively tied to CUDA.
The model is open-weight and available on Hugging Face under a permissive license, making it accessible to individual developers, research teams, and startups who previously had no path to this level of math and reasoning capability without API access to closed models.
Architecture Deep Dive: CCA, MLP Router, and Residual Scaling
ZAYA1-8B is not just a standard MoE with a new training recipe. It ships three specific architectural innovations that separate it from the field.
Compressed Convolutional Attention (CCA)
Standard attention is expensive because it stores a key-value (KV) cache that grows with every token in the context. For long inputs, this becomes the memory bottleneck. Zyphra's Compressed Convolutional Attention replaces standard attention with a convolutional variant that compresses the KV cache by 8x.
In practical terms: a conversation or document that would normally require 8 GB of KV cache now requires about 1 GB. This is what makes ZAYA1-8B viable on hardware that would otherwise be too constrained for a model of this capability level. CCA does not meaningfully hurt accuracy on benchmarks — the compression is structured rather than lossy.
MLP-Based Expert Router
In most MoE models, the router (the network that decides which experts handle each token) is a simple linear layer followed by a softmax. ZAYA1-8B replaces this with a Multi-Layer Perceptron (MLP) router, which is more expressive. The practical benefit: better expert specialization, more stable training, and the ability to use a top-k of 1 (only one expert per token) without needing residual experts as a safety net. This is a meaningful efficiency gain — activating one expert instead of two per token cuts compute further.
Learned Residual Scaling
Deep networks suffer from residual norm growth: as signals pass through many layers, their magnitude can drift and destabilize training. ZAYA1-8B introduces learned residual scaling, a lightweight mechanism that controls this growth through depth at negligible parameter and FLOP cost. The result is more stable training at depth — which matters when you're trying to pack reasoning capability into fewer parameters.
Markovian RSA: Test-Time Compute Explained
Test-time compute is one of the most important trends in AI right now. The idea: rather than only investing compute during training, let the model spend more computation during inference for harder problems. This is what powers the reasoning modes in models like o1, o3, and DeepSeek-R1.
ZAYA1-8B introduces its own approach called Markovian RSA (Randomized Sequential Aggregation). Here is how to think about it in plain terms:
- Standard inference: the model generates one answer in a single forward pass.
- Best-of-N sampling: generate N independent answers, pick the best-scoring one. Simple, but the candidates don't learn from each other.
- Markovian RSA: generates multiple reasoning traces in parallel, but each new trace is conditioned on a fixed-length summary of the previous traces rather than starting fresh. The model accumulates insight across attempts without growing context length exponentially.
The 'Markovian' name comes from how state is passed: only a fixed-length summary carries forward, not the entire prior reasoning chain. This keeps memory bounded while still letting the model benefit from multiple passes. At increased test-time compute budget, ZAYA1-8B with Markovian RSA closes in on GPT-5-High — a proprietary model with an estimated active parameter count more than 30 times larger.
Hot take: Markovian RSA is the architecture innovation most worth watching from this release. Test-time compute is where the AI efficiency frontier is moving fastest in 2026, and bounded-context multi-pass reasoning is a genuinely different approach from what the major labs have published.
ZAYA1-8B Benchmark Results
The benchmark numbers are the part that makes researchers do a double-take. Here is ZAYA1-8B compared to key open-weight and proprietary models:
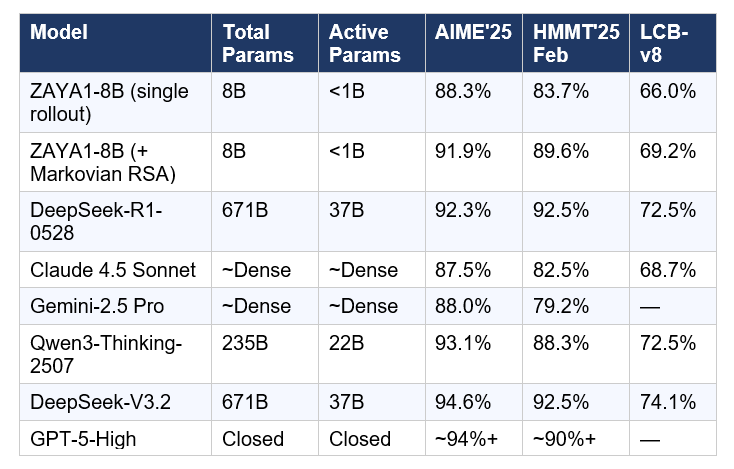
Source: Zyphra official release, May 6, 2026. ZAYA1-8B + Markovian RSA scores use extended test-time compute. All other scores are vendor-reported or independently verified via public leaderboards.
The honest read on these numbers: with a single rollout (no extended test-time compute), ZAYA1-8B already beats Claude 4.5 Sonnet on AIME'25 and HMMT'25. Add Markovian RSA and it nearly matches Claude on every benchmark while using a fraction of the active parameters. It does not yet match DeepSeek-V3.2 or GPT-5-High — and that is the right expectation to set. But the ratio of performance to active compute is genuinely unprecedented.
For full context on where DeepSeek-V3.2 and V4 sit in the current landscape, the DeepSeek V4 Pro deep dive on Build Fast with AI covers the architecture innovations that let V4-Pro hit 80.6% on SWE-bench Verified at 49B active parameters — a different efficiency story but a related trend.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
The Intelligence Density Trend: Why Smaller Is Winning in 2026
ZAYA1-8B is not an outlier. It is the latest data point in a clear directional trend that researchers have been tracking for over a year.
In late 2025, researchers published the Densing Law in Nature Machine Intelligence: capability density (performance per parameter) doubles approximately every 3.5 months. That is a faster compression rate than most practitioners expected. The implication: a model that required 70 billion parameters in 2024 can likely be replicated by a 7 billion parameter model in 2026 — if training and architecture are done right.
ZAYA1-8B is Exhibit A for this law. It achieves near-frontier math and reasoning performance with under 1 billion active parameters — a parameter count that, two years ago, could barely handle basic instruction following.
The efficiency revolution is not just about math benchmarks. It changes who can build with frontier AI. If you want to explore running efficient MoE models on alternative inference hardware, the Cerebras Cookbook from Build Fast with AI shows how fast inference on non-Nvidia hardware (Cerebras WSE) works in practice — a complementary angle to Zyphra's AMD-native training story.
There is a commercial angle here too. Inference compute is projected to exceed training compute demand by 118x by 2026. Running smaller models with high intelligence density is not just an academic exercise — it is the economic rational choice for teams building production AI systems at scale.
How to Run ZAYA1-8B on Hugging Face
ZAYA1-8B is available open-weight on Hugging Face. Here is how to load and run it using the Transformers library. A standard GPU with 12–16 GB VRAM is sufficient for the quantized version; the full BF16 model fits comfortably in 24 GB VRAM.
Step 1: Install dependencies
pip install transformers accelerate torchStep 2: Load the model
from transformers import AutoTokenizer, AutoModelForCausalLM import torch model_id = "zyphra/ZAYA1-8B" tokenizer = AutoTokenizer.from_pretrained(model_id) model = AutoModelForCausalLM.from_pretrained( model_id, torch_dtype=torch.bfloat16, device_map="auto" )Step 3: Run inference
messages = [
{"role": "user", "content": "Solve: Find all integer solutions to x^2 + y^2 = 2026."} ]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt" ).to(model.device)
outputs = model.generate(
input_ids, max_new_tokens=2048, temperature=0.6, do_sample=True ) response = tokenizer.decode(outputs[0][input_ids.shape[-1]:], skip_special_tokens=True) print(response)Step 4: Enable Markovian RSA for harder problems
# Markovian RSA is triggered via generation parameters and system prompt # For extended test-time compute, use the reasoning system prompt: system_msg = "You are a careful mathematical reasoner. Think step by step, "\ "verify your work, and try multiple approaches before answering." messages = [ {"role": "system", "content": system_msg}, {"role": "user", "content": "Solve: ..."} ] # Then use the same generation call as above with higher max_new_tokens (4096+)
For hands-on experimentation notebooks with open-source reasoning models and local inference patterns, the Build Fast with AI gen-ai-experiments repository has 130+ production-ready notebooks covering Hugging Face Transformers, vLLM, and model evaluation — a solid starting point for integrating ZAYA1-8B into your own projects.
One important note on hardware: the full BF16 model requires approximately 16 GB of GPU VRAM. For constrained environments, use bitsandbytes 4-bit quantization (load_in_4bit=True) to bring this down to roughly 6 GB — still with very strong reasoning performance on most tasks.
Frequently Asked Questions
What is ZAYA1-8B?
ZAYA1-8B is an open-weight Mixture-of-Experts reasoning model released by Zyphra on May 6, 2026. It has 8 billion total parameters but under 1 billion active per token, and scores 91.9% on AIME'25 with Markovian RSA test-time compute — competitive with models more than 30 times larger.
What is Markovian RSA and how does it work?
Markovian RSA (Randomized Sequential Aggregation) is Zyphra's test-time compute method. Instead of running inference once, it generates multiple reasoning traces in parallel, with each trace conditioned on a fixed-length summary of prior traces. This bounded-context multi-pass approach improves reasoning accuracy without exponential memory growth — enabling ZAYA1-8B to close in on GPT-5-High with enough compute budget.
What is Compressed Convolutional Attention (CCA)?
CCA is Zyphra's replacement for standard attention in ZAYA1-8B. It reduces the KV cache (the memory stored during inference to represent prior tokens) by 8x through a convolutional compression approach. This makes longer contexts and lower-VRAM inference viable without significant accuracy loss.
How does ZAYA1-8B compare to DeepSeek-V3.2?
DeepSeek-V3.2 scores higher on most benchmarks (94.6% on AIME'25 vs. 91.9% for ZAYA1-8B with Markovian RSA). However, DeepSeek-V3.2 uses 671 billion total parameters and 37 billion active per token — roughly 37 times more active compute. ZAYA1-8B is not the absolute strongest open model; it is the strongest model at its active parameter count by a wide margin.
Can I run ZAYA1-8B on a consumer GPU?
Yes. The full BF16 model fits in 16 GB VRAM (e.g., RTX 3080 Ti, RTX 4080). With 4-bit quantization via bitsandbytes, it runs on 8 GB VRAM GPUs like the RTX 3070 or RTX 4060 Ti. Performance at 4-bit is slightly reduced on the hardest math problems but remains well above any dense model of comparable size.
What is intelligence density in AI?
Intelligence density (also called capability density) is performance per parameter. The Densing Law, published in Nature Machine Intelligence in 2025, found that capability density doubles approximately every 3.5 months — meaning frontier-level reasoning can be achieved with exponentially fewer parameters over time. ZAYA1-8B is a direct embodiment of this trend.
Is ZAYA1-8B open source?
ZAYA1-8B is open-weight — the model weights are publicly available on Hugging Face. The training code and full methodology are described in Zyphra's technical report. This is functionally open for research and commercial use, though 'open source' technically requires the training code and data to also be public.
Why was ZAYA1-8B trained on AMD instead of Nvidia?
Zyphra has built an AMD-native AI training stack as part of their infrastructure strategy (Zyphra Cloud runs on AMD). Training ZAYA1-8B on 1,024 AMD Instinct MI300X GPUs demonstrates that AMD hardware is production-viable for frontier model training — a significant commercial claim at a time when Nvidia dominates AI compute. It also has strategic implications for the AI compute supply chain independence from Nvidia's CUDA ecosystem.
Recommended Blogs
- Mixture of Experts (MoE) Explained — Architecture, Routing, and Why Every Major Model Uses It
- DeepSeek V4 Pro Review: Benchmarks, Architecture, and 7x Cost Advantage Over Claude
- DeepSeek V4 Flash Review: When the Budget Model Beats the Flagship
Start Building
ZAYA1-8B is live on Hugging Face right now. If you are building with reasoning models — for math, code generation, or complex agent tasks — this is the most compute-efficient open option available as of May 2026. Subscribe to the Build Fast with AI newsletter to stay ahead of every major model release with practical analysis and working code examples.
References
- Zyphra — ZAYA1-8B Official Press Release (May 6, 2026)
- AMD — Zyphra Unveils ZAYA1: First Large-Scale MoE Trained on AMD Instinct MI300X
- Nature Machine Intelligence — Densing Law of LLMs: Capability Density Doubles Every 3.5 Months
- HuggingFace — Mixture of Experts Explained (Architecture Deep Dive)
- Towards Data Science — Test-Time Compute: Why Reasoning Models Raise Your Compute Bill (2026)
- Build Fast with AI — Mixture of Experts (MoE) Explained
- Build Fast with AI — DeepSeek V4 Pro Review

