





The Privacy Challenge in Large Language Models
As large language models (LLMs) become more powerful, privacy risks have come into sharper focus. These models, trained on massive web-scale datasets, are vulnerable to memorization attacks, where sensitive or personally identifiable information (PII) can resurface.
This risk is especially concerning for open-weight models, where adversaries can directly probe or analyze the model to extract memorized training data. Past studies have shown that verbatim snippets of training text, including PII, can be extracted with the right prompts.
While fine-tuning with Differential Privacy (DP) has been attempted before, this only protects the fine-tuning data, not the billions of tokens used during pretraining. Once memorization has occurred, fine-tuning cannot erase it. The challenge is clear: privacy must be built in from the start.
Introducing VaultGemma
Google DeepMind and Google Research have released VaultGemma 1B, a 1-billion-parameter model from the Gemma family, trained from scratch with differential privacy.
This marks the largest open-weight LLM with rigorous privacy guarantees to date. Unlike earlier efforts that applied DP only at later stages, VaultGemma enforces full private pretraining, setting a new benchmark for privacy-preserving AI.
VaultGemma’s weights are available via Hugging Face and Kaggle, along with a comprehensive technical report, enabling researchers worldwide to study, replicate, and improve upon this work.
Formal Privacy Guarantee
VaultGemma’s training achieved a sequence-level DP guarantee of:
ε ≤ 2.0
δ ≤ 1.1 × 10⁻¹⁰
The privacy unit is a 1024-token sequence. This means that the model provides a provable guarantee that no single sequence in its training corpus significantly influences its outputs.
⚠️ However, this is not user-level DP. If sensitive information appears across many sequences, it could still be partially learned. Still, sequence-level DP is a major milestone for models at this scale.
Technical Foundations: How VaultGemma Was Built

VaultGemma builds on the Gemma 2 series but with key innovations for DP training:
DP-SGD (Differentially Private Stochastic Gradient Descent):
Each gradient update is clipped per example, then noise is added (Gaussian mechanism) to obscure the contribution of individual data points.Vectorized per-example clipping:
Maximizes parallelism and reduces computational bottlenecks.Gradient accumulation:
Simulates extremely large batch sizes, which are crucial for effective DP training.Truncated Poisson subsampling:
Efficiently integrated into the data loading pipeline for privacy accounting, enabling fast throughput without losing privacy guarantees.Training data:
VaultGemma used the same 13-trillion-token mixture as Gemma 2, covering English text, web documents, code, and scientific articles. This allows apples-to-apples comparison with non-private Gemma models.
Architecture Overview
VaultGemma is architecturally similar to Gemma-family decoder-only transformers, but optimized for private training.
Key confirmed choices:
1B parameters
1024-token sequence length (chosen for DP accounting efficiency)
Gemma 2 tokenizer and data mixture
Some micro-architecture details (e.g., number of layers, feedforward dimension, activation functions, and attention variants) are not explicitly listed in public reports. They are assumed to follow Gemma-family conventions but should not be overstated without the technical report.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Scaling Laws for Differential Privacy
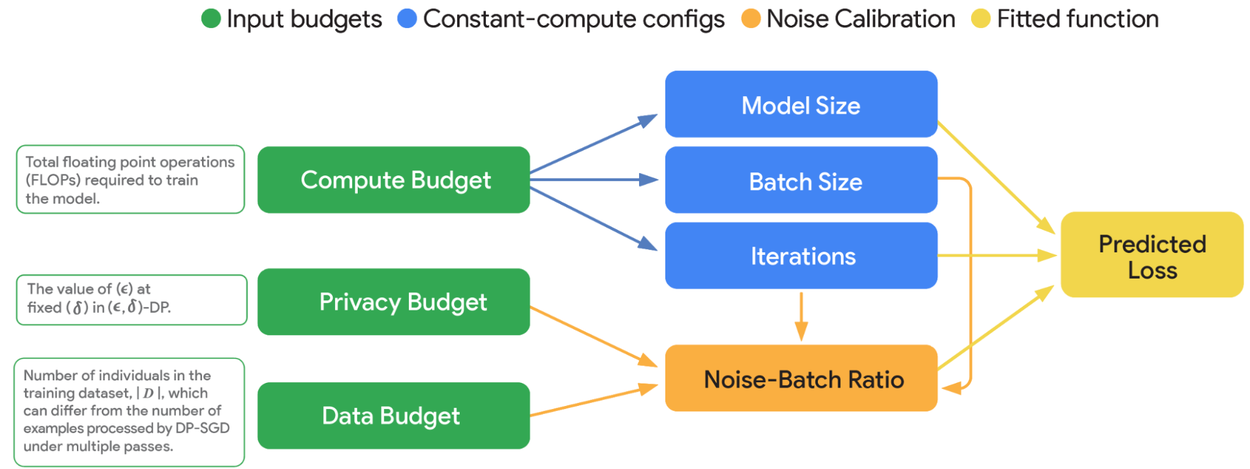
A key contribution of the VaultGemma project is new scaling laws tailored to DP models.
Google researchers developed three methodological advances:
Optimal learning rate modeling: Instead of grid search, they fit a quadratic curve to losses across multiple learning rates to estimate the best choice.
Parametric extrapolation: Predicted training loss across longer runs without needing all intermediate checkpoints.
Semi-parametric fits: Related model size, training steps, and noise-batch ratio to achievable loss, giving a roadmap for compute-privacy-utility tradeoffs.
Practical takeaway: Under DP, you often get better results by training a smaller model with much larger batches. Gains from increasing privacy budgets alone are limited unless matched with more data or compute.
Performance and Benchmarks
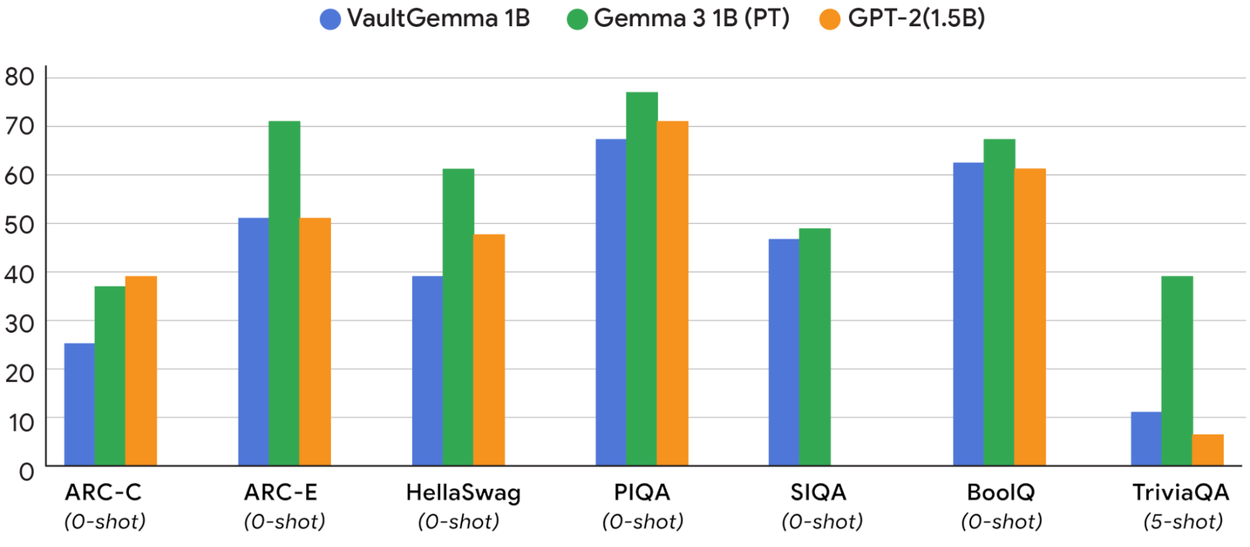
VaultGemma demonstrates that DP-trained models are viable, though still behind non-private state-of-the-art:
On benchmarks like ARC-C, PIQA, and TriviaQA, VaultGemma underperforms Gemma-3 1B, but matches the utility of non-private models from ~2019–2020 (e.g., GPT-2 1.5B).
This highlights the current utility gap: privacy comes at the cost of some performance, but it is closing with better scaling laws and training strategies.
Memorisation Testing
One of VaultGemma’s biggest achievements is its resistance to memorization attacks.
Researchers ran empirical tests using 1 million sampled training data sequences, probing with 50-token prefixes to see if the model reproduced exact or approximate suffixes.
Non-private Gemma models: Showed detectable levels of memorization.
VaultGemma: Showed no detectable verbatim memorization under these tests.
This confirms that DP training not only provides theoretical privacy guarantees, but also holds up in practice.
Limitations and Open Questions
Sequence-level DP only: User-level DP is harder and remains a goal for future work.
Utility gap persists: Today’s DP-trained models are competitive with older non-private models, not cutting-edge ones.
Compute cost: Training VaultGemma required large-scale TPU infrastructure; private training remains resource-intensive.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
Why VaultGemma Matters
VaultGemma is more than just a model: it’s a baseline for private AI research. By releasing weights, training methodology, and scaling laws, Google has:
Lowered the barrier for developing privacy-preserving AI systems
Enabled researchers to benchmark, extend, and refine DP methods
Demonstrated that rigorous privacy guarantees at pretraining scale are achievable
Conclusion: The Path Forward
VaultGemma represents a turning point: it proves that large-scale pretraining with differential privacy is possible without rendering models useless.
While performance lags behind the latest non-private LLMs, the gap is shrinking thanks to scaling laws, improved algorithms, and better data curation.
The vision is clear: the future of AI must be powerful and private by design. VaultGemma provides the tools, benchmarks, and proof that this is not only possible, but practical.
===================================================================
Master Generative AI in just 8 weeks with the GenAI Launchpad by Build Fast with AI.
Gain hands-on, project-based learning with 100+ tutorials, 30+ ready-to-use templates, and weekly live mentorship by Satvik Paramkusham (IIT Delhi alum).
No coding required—start building real-world AI solutions today.
👉 Enroll now: www.buildfastwithai.com/genai-course
⚡ Limited seats available!
===================================================================
Resources & Community
Join our vibrant community of 12,000+ AI enthusiasts and level up your AI skills—whether you're just starting or already building sophisticated systems. Explore hands-on learning with practical tutorials, open-source experiments, and real-world AI tools to understand, create, and deploy AI agents with confidence.
Website: www.buildfastwithai.com
GitHub (Gen-AI-Experiments): git.new/genai-experiments
LinkedIn: linkedin.com/company/build-fast-with-ai
Instagram: instagram.com/buildfastwithai
Twitter (X): x.com/satvikps
Telegram: t.me/BuildFastWithAI

