





EmbeddingGemma: Google’s 308M On-Device Embedding Model
Google has introduced EmbeddingGemma, a compact yet powerful multilingual embedding model designed for on-device AI. With just 308 million parameters, it delivers state-of-the-art performance across 100+ languages, topping the Massive Text Embedding Benchmark (MTEB) for models under 500M parameters.
This launch represents a breakthrough for mobile-first AI, enabling advanced tasks like semantic search, RAG pipelines, and private offline assistants — all without depending on the cloud.
Why EmbeddingGemma Matters
Large embedding models power tasks like semantic search, clustering, and document retrieval — but they usually require significant compute and memory. EmbeddingGemma breaks this barrier by combining efficiency with performance:
308M parameters with near-500M model performance
100+ languages supported out of the box
Privacy-first — runs fully offline
Under 200MB RAM usage with quantization
Mobile-ready — works on laptops, desktops, and smartphones
It’s Google’s way of democratizing high-quality embeddings, making them accessible even on resource-limited devices.
Inside the Architecture: Efficient by Design
Built on the Gemma 3 encoder backbone, EmbeddingGemma modifies a transformer architecture for embedding tasks. Unlike generative LLMs, it uses bidirectional attention, allowing tokens to attend both forward and backward — crucial for building strong embeddings.
Key design features include:
Transformer Encoder Stack → optimized for embedding generation.
Mean Pooling Layer → compresses variable token lengths into fixed-size vectors.
Dense Transformation Layers → outputs 768-dim embeddings for rich representation.
It handles up to 2,048 tokens, covering typical retrieval workloads without losing context.
Smarter Optimisation: Flexible, Fast & Lightweight
EmbeddingGemma introduces cutting-edge efficiency tricks:
Matryoshka Representation Learning (MRL) → Developers can truncate embeddings from 768 → 512 → 256 → 128 dimensions with minimal quality loss. This flexibility lets you optimize for speed, memory, or precision.
Quantization-Aware Training (QAT) → Keeps RAM usage under 200MB, perfect for mobile and edge devices.
Fast Inference → Generates embeddings in <15ms (256 tokens) on EdgeTPU.
👉 In short: It runs fast, uses little memory, and adapts to your hardware needs.
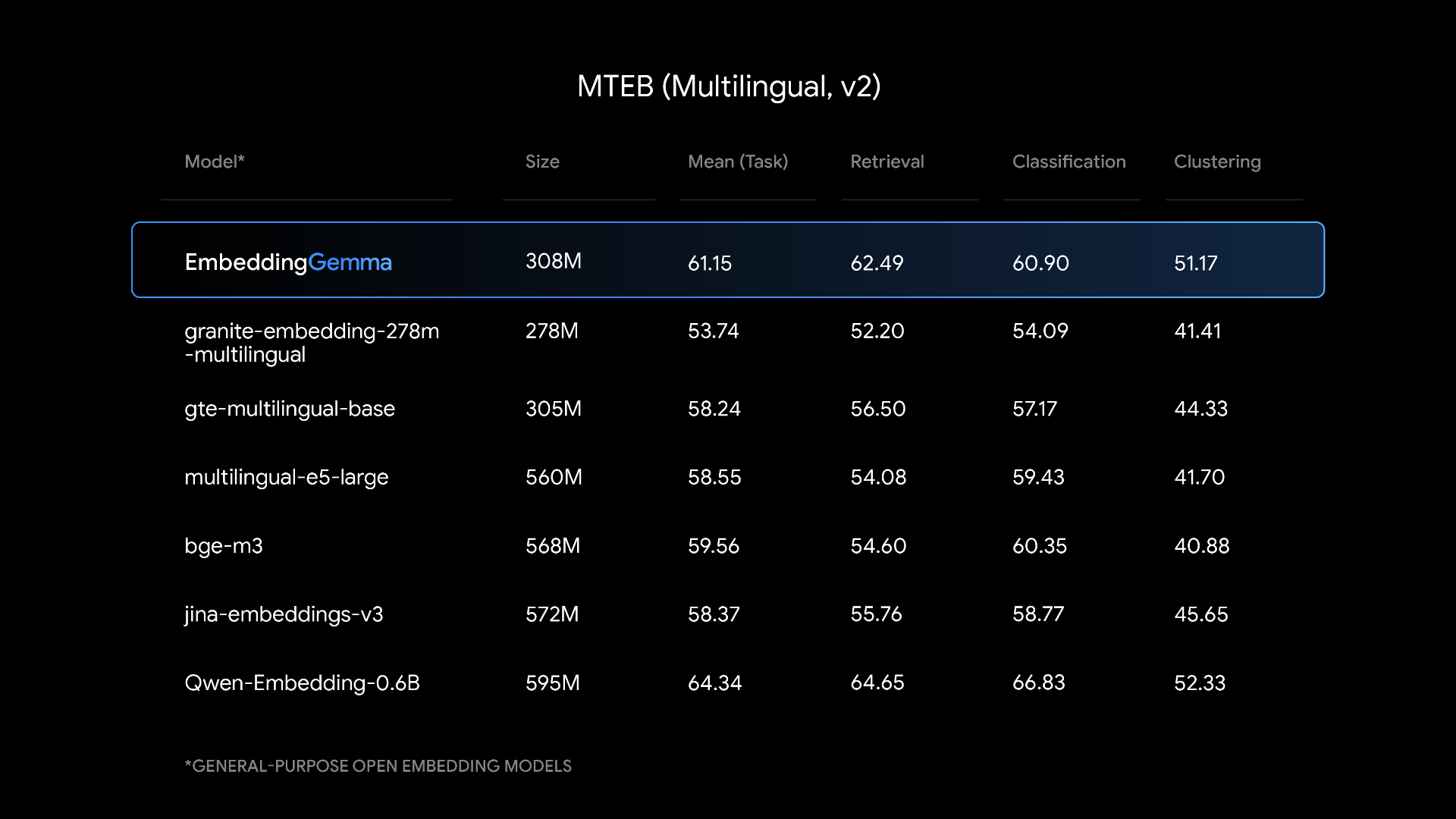
Benchmark Results: Punching Above Its Weight
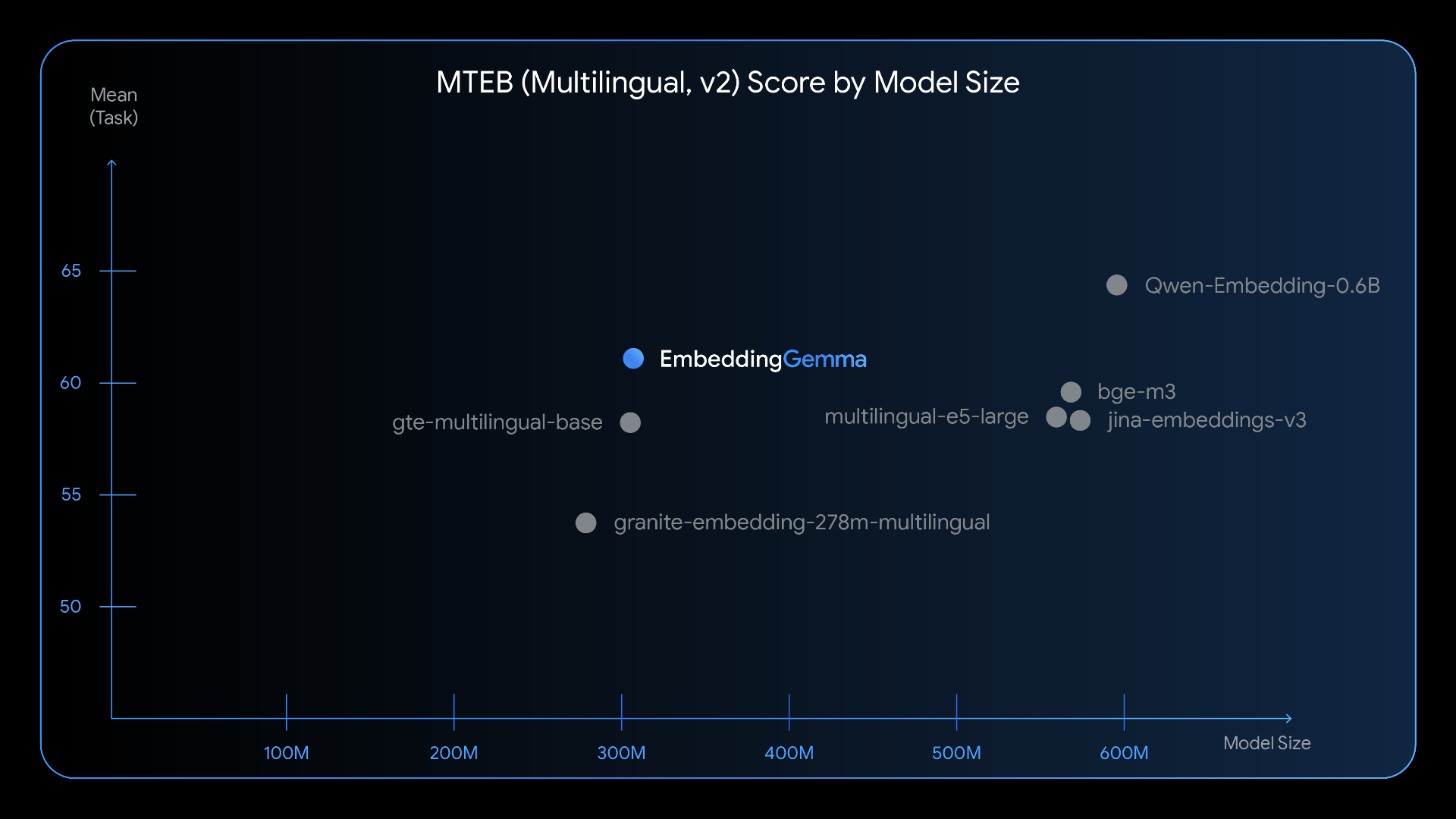
On MTEB, the gold standard for text embeddings, EmbeddingGemma ranked #1 among models under 500M parameters.
It excels in:
Retrieval → finding relevant docs with high accuracy.
Classification → sorting text across languages.
Clustering → grouping similar documents.
Cross-lingual tasks → strong multilingual retrieval and semantic search.
Despite being smaller, it rivals models nearly twice its size in real-world performance.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Real-World Use Cases
EmbeddingGemma unlocks powerful applications across both enterprise and developer ecosystems:
🔒 Privacy-Preserving AI
Fully offline semantic search across personal files, emails, and docs.
Chatbots that run locally without sending data to the cloud.
📱 Mobile-First AI
Offline RAG pipelines → combine retrieval + local generative models for instant answers.
Personal AI assistants that classify queries and trigger local actions.
👨💻 Developer Scenarios
Semantic code search in large repositories.
Multilingual document search for global businesses.
Custom enterprise search across knowledge bases.
This makes it a go-to solution for startups, enterprises, and app developers building on-device intelligent assistants.
Flexible Deployment
EmbeddingGemma integrates seamlessly with popular AI frameworks:
Hugging Face Transformers & SentenceTransformers
LangChain, LlamaIndex, Haystack for RAG
Vector databases like Weaviate
Cross-platform optimizations with ONNX Runtime, MLX (Apple Silicon), LiteRT (mobile)
It’s also available on Hugging Face Hub, Kaggle, and Google Vertex AI, ensuring easy access.
Training Data & Safety
EmbeddingGemma was trained on ~320B tokens, spanning:
🌍 Web documents in 100+ languages
👨💻 Code & technical docs
🛠️ Synthetic task-specific datasets for embeddings
Google also applied rigorous filtering to remove unsafe, low-quality, and sensitive data — ensuring reliable and safe embeddings.
Future Impact: Smarter, Smaller, More Private AI
EmbeddingGemma is more than just another embedding model. It signals a shift in how AI will be deployed:
AI Everywhere → Advanced embeddings, now on your phone.
Privacy by Default → No cloud dependency for intelligent search.
Innovation for All → Startups and researchers with limited resources gain access to high-quality embeddings.
Enterprise Edge AI → Businesses can deploy local AI without risking sensitive data.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
Conclusion
EmbeddingGemma proves that bigger isn’t always better.
With just 308M parameters, it delivers world-class embeddings, supports 100+ languages, and runs efficiently on everyday devices. Its offline-first design, flexible embeddings, and ecosystem support make it a powerful tool for the next generation of private, mobile, and enterprise AI applications.
For developers, researchers, and enterprises alike, EmbeddingGemma represents a new era of accessible AI — one where powerful language understanding doesn’t come at the cost of speed, size, or privacy.
===================================================================
Master Generative AI in just 8 weeks with the GenAI Launchpad by Build Fast with AI.
Gain hands-on, project-based learning with 100+ tutorials, 30+ ready-to-use templates, and weekly live mentorship by Satvik Paramkusham (IIT Delhi alum).
No coding required—start building real-world AI solutions today.
👉 Enroll now: www.buildfastwithai.com/genai-course
⚡ Limited seats available!
===================================================================
Resources & Community
Join our vibrant community of 12,000+ AI enthusiasts and level up your AI skills—whether you're just starting or already building sophisticated systems. Explore hands-on learning with practical tutorials, open-source experiments, and real-world AI tools to understand, create, and deploy AI agents with confidence.
Website: www.buildfastwithai.com
GitHub (Gen-AI-Experiments): git.new/genai-experiments
LinkedIn: linkedin.com/company/build-fast-with-ai
Instagram: instagram.com/buildfastwithai
Twitter (X): x.com/satvikps
Telegram: t.me/BuildFastWithAI

