




Gemma 4 MTP Drafter: How to Get 3x Faster Inference (2026 Setup Guide)
On May 5, 2026 — just weeks after Gemma 4 racked up 60 million downloads — Google dropped something the developer community had been asking for since launch day: Multi-Token Prediction (MTP) drafters. The promise is up to 3x faster inference with zero quality loss. For anyone running Gemma 4 locally on a consumer GPU, an Apple Silicon Mac, or an NVIDIA H100, this is a significant upgrade worth understanding and implementing today.
This guide explains exactly how MTP drafters work, shows you the real benchmark numbers across hardware, and walks you through setup on Hugging Face Transformers and vLLM — the two most common deployment paths for Gemma 4.
1. Why Standard LLM Inference Is Slow (The Root Cause)
Standard LLM inference is slow not because your GPU lacks processing power — it is slow because of memory bandwidth. Every time the model generates a single token, the processor must move billions of parameters from VRAM to the compute units, perform a forward pass, produce one token, and then repeat the entire cycle. The GPU sits mostly idle during the transfer, waiting for weights to arrive.
This creates a fundamental inefficiency: the model dedicates identical compute to predicting an obvious continuation — like 'words' after 'Actions speak louder than…' — as it does to solving a complex logic problem. Every token costs the same regardless of how predictable it is.
The bottleneck gets more painful on consumer-grade hardware where memory bandwidth is lower. A developer running Gemma 4 31B on a workstation GPU feels this directly as high latency between tokens — especially on longer outputs. Solving this does not require faster hardware. It requires smarter software — and that is exactly what MTP drafters deliver.
2. What Is the Gemma 4 MTP Drafter?
The Gemma 4 MTP drafter is a lightweight companion model designed to work alongside the main Gemma 4 model through speculative decoding. For every Gemma 4 variant — E2B, E4B, 26B MoE, and 31B Dense — there is a corresponding lightweight drafter released under the same Apache 2.0 license.
The drafter is a 4-layer model, orders of magnitude smaller than the target model. Its job is not to produce the final output — it is to make fast, educated guesses about what tokens the larger model would generate, so the larger model can verify multiple tokens in a single forward pass instead of generating them one at a time.
Google engineered several enhancements that make the Gemma 4 MTP drafters more effective than generic speculative decoding approaches:
- Shared KV cache: The drafter reuses the target model's key-value cache and activations, avoiding redundant context recalculation that would otherwise eat into speed gains.
- Embedding clustering for edge models: For E2B and E4B variants where logit calculation becomes a bottleneck, Google implemented an efficient clustering technique in the embedder that further accelerates generation.
- Hardware-specific tuning: The drafters are optimized for NVIDIA GPUs, Apple Silicon via MLX, and Pixel TPU environments — not just generic inference.
If you are new to running Gemma models locally, the complete guide to running Gemma 3 locally walks through the foundational setup before you layer in MTP optimization.
3. How Speculative Decoding Works — Step by Step
Speculative decoding is an inference-time optimization that Google researchers first published in 2022 in 'Fast Inference from Transformers via Speculative Decoding' (Leviathan, Kalman, Matias — ICML 2023), where it delivered 2x to 3x acceleration on T5-XXL with identical outputs. The Gemma 4 MTP drafters are a production-grade implementation of that same line of research, now tuned specifically for the Gemma 4 architecture.
Here is the exact sequence of what happens on every generation cycle with MTP enabled:
- The drafter model runs multiple autoregressive forward passes rapidly — predicting several draft tokens in the time it would take the target model to generate just one.
- The target model receives the entire draft sequence and verifies all tokens in a single parallel forward pass.
- Any draft tokens the target model agrees with are accepted — the full sequence gets output in one cycle.
- The first rejected token causes all subsequent draft tokens to be discarded. The cycle restarts from the rejection point.
- Because the target model also generates one additional token of its own during verification, even a full rejection still produces one correct token.
The key insight is that the GPU's idle bandwidth during weight loading — which was previously wasted — is now used to verify multiple tokens simultaneously. When the drafter guesses correctly (which it does roughly 70–90% of the time on conversational tasks), you get several tokens for the price of one target model pass. The output is mathematically identical to what standard autoregressive generation would have produced.
4. Real Benchmark Numbers: Tokens Per Second by Hardware
Google benchmarked the MTP drafters across LiteRT-LM, MLX, Hugging Face Transformers, and vLLM. The numbers below reflect documented performance data from the May 5, 2026 release announcement and community benchmarking:
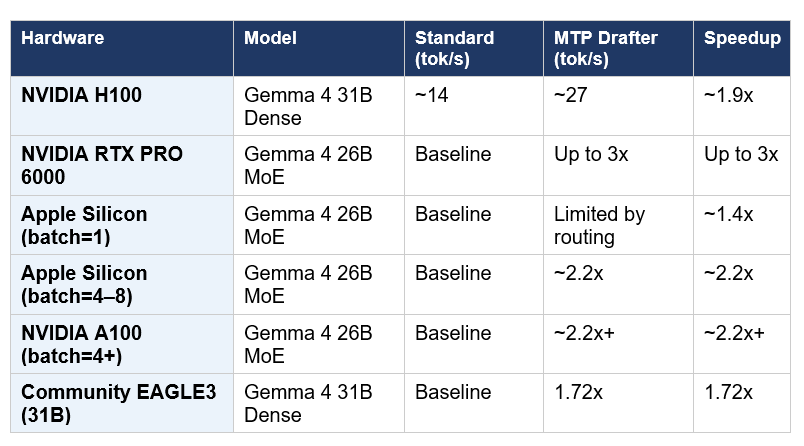
Honest reading of these numbers: the 3x figure is a best-case upper bound, achieved on the 26B MoE model with NVIDIA RTX PRO 6000 hardware and optimal batch configuration. The more consistent real-world number on most developer hardware is 1.7x to 2.2x — which is still a meaningful improvement that makes local Gemma 4 feel noticeably more responsive.
The practical speedup depends heavily on two variables: hardware type (NVIDIA vs Apple Silicon vs edge) and workload character (conversational tasks see higher acceptance rates and therefore larger gains than code-heavy tasks where token sequences are harder to predict).
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
5. Setup Guide: Gemma 4 MTP on Hugging Face Transformers
Setting up Gemma 4 MTP on Hugging Face Transformers requires loading two models — the target model and its corresponding assistant (drafter) — and passing the assistant model during generation. Here is the complete setup:
Step 1: Install dependencies
pip install transformers accelerate torch --upgradeStep 2: Load the target and drafter models
from transformers import AutoProcessor, Gemma4ForConditionalGeneration
import torch
# Target model — the main Gemma 4 model
target_model_id = "google/gemma-4-E2B-it"
target_model = Gemma4ForConditionalGeneration.from_pretrained(
target_model_id, torch_dtype=torch.bfloat16, device_map="auto"
)
processor = AutoProcessor.from_pretrained(target_model_id)
# Assistant model — the lightweight MTP drafter
assistant_model_id = "google/gemma-4-E2B-it-assistant"
assistant_model = Gemma4ForConditionalGeneration.from_pretrained(
assistant_model_id, torch_dtype=torch.bfloat16, device_map="auto"
)Step 3: Configure draft tokens and run inference
# Set how many draft tokens the assistant proposes
assistant_model.generation_config.num_assistant_tokens = 4
assistant_model.generation_config.num_assistant_tokens_schedule = "heuristic"# Prepare your input
messages = [{"role": "user", "content": "Explain speculative decoding in simple terms."}]
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(target_model.device)
# Generate with MTP drafter
outputs = target_model.generate(
**inputs,
assistant_model=assistant_model,
max_new_tokens=512,
do_sample=False,
)
response = processor.decode(outputs[0][inputs['input_ids'].shape[1]:], skip_special_tokens=True)
print(response)The num_assistant_tokens_schedule='heuristic' setting lets the framework dynamically adjust how many tokens the drafter proposes based on observed acceptance rates — you do not need to manually tune this for most use cases.
For developers looking to go beyond inference and build autonomous agents on top of Gemma 4, the guide to building multi-agent workflows with LangGraph Supervisor covers the orchestration layer that sits above the model.
6. Setup Guide: Gemma 4 MTP on vLLM
vLLM is the preferred serving framework for production Gemma 4 deployments and supports MTP drafters natively through its speculative decoding configuration. This approach is better for multi-user serving scenarios where throughput matters more than single-request latency.
Install vLLM
pip install vllm --upgradeLaunch the server with MTP drafter
vllm serve google/gemma-4-31B-it \
--speculative-model google/gemma-4-31B-it-assistant \
--num-speculative-tokens 4 \
--dtype bfloat16 \
--tensor-parallel-size 1Query the server
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="token-abc123")
response = client.chat.completions.create(
model="google/gemma-4-31B-it",
messages=[
{"role": "user", "content": "Write a Python function to sort a list of dicts by key."}
],
max_tokens=512,
)
print(response.choices[0].message.content)vLLM handles the drafter-target pairing internally. You do not need to manage two separate model instances in your application code — the server abstracts the speculative decoding loop entirely.
If you are building agentic workflows that need to run fast multi-step reasoning chains, the OpenAI Agents workflow automation guide shows how to structure those pipelines in a way that maps well to Gemma 4 as the underlying model.
7. Optimizing Draft Token Count for Your Use Case
The number of draft tokens you ask the assistant to generate is the primary lever for tuning MTP performance. There is a genuine tradeoff here that Google's official documentation makes clear:
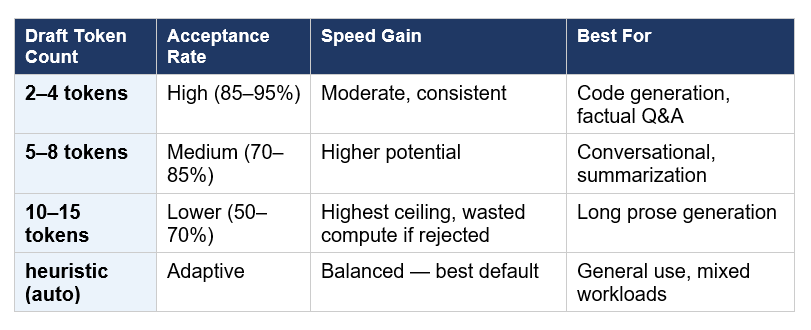
The 'heuristic' schedule is the recommended default for most deployments. It monitors acceptance rates in real time and adjusts the number of draft tokens dynamically — drafting more aggressively when the model is on a roll and pulling back when prediction difficulty increases, such as during complex reasoning or code with unusual syntax.
For code generation workloads specifically, keeping draft tokens at 3–4 produces better efficiency than pushing higher, because code token sequences are harder to predict than natural language and rejection rates climb quickly beyond that range.
8. Apple Silicon and MoE: What to Watch For
The 26B Mixture-of-Experts model deserves special attention on Apple Silicon because of a hardware-software interaction that affects MTP gains.
MoE models use dynamic routing — each forward pass activates a different subset of expert layers depending on the input. At batch size 1 (a single user prompt), this routing creates overhead that partially offsets MTP speed gains on Apple's unified memory architecture. The result: at batch=1, Apple Silicon users see smaller MTP benefits on the 26B MoE than they would on NVIDIA hardware.
The solution is straightforward — increasing batch size to 4–8 unlocks up to approximately 2.2x speedup on Apple Silicon with the 26B MoE. If you are building a local chat application or server that handles multiple requests, batching inputs is the correct configuration. If you are doing single-request interactive use, the 31B Dense model actually shows more consistent MTP gains on Apple Silicon than the 26B MoE because it has no routing overhead.
For Python developers building agentic applications that orchestrate Gemma 4 across multiple tasks, the Griptape AI workflow automation guide provides a framework for chaining LLM calls in ways that naturally benefit from MTP-optimized inference speed.
9. Honest Assessment: Does 3x Actually Happen?
The 3x figure from Google is real — but it is a best-case number, not a typical number. Let me break down what you will actually experience across realistic scenarios.
The 3x gain occurs on the 26B MoE model, on NVIDIA RTX PRO 6000 class hardware, at optimal batch sizes, generating conversational text where the drafter can predict tokens accurately. This is a specific, narrow set of conditions.
More typical real-world results for developer hardware:
- Consumer NVIDIA GPU (RTX 4090 class): 1.8x to 2.5x on conversational tasks
- Apple M3 Max / M4 Max (32GB+): 1.6x to 2.2x depending on model and batch size
- NVIDIA A100 cloud GPU: 2x to 2.5x at reasonable batch sizes
- Edge devices (E2B / E4B): 1.5x to 2x with embedding clustering gains
The honest bottom line: even a 1.7x speed improvement is meaningful in practice. If Gemma 4 31B was generating at 14 tokens/sec before, reaching 24 tokens/sec changes the interactive feel of a chat application from sluggish to usable. And the quality guarantee is absolute — because the target model retains final verification authority, the output is bit-for-bit identical to what standard inference would have produced.
The risk to manage is the Apple Silicon + 26B MoE combination at batch size 1 — if that is your configuration, start with batch size 4 or switch to the 31B Dense variant before concluding MTP is not helping.
Frequently Asked Questions
What is the Gemma 4 MTP drafter?
The Gemma 4 MTP drafter is a lightweight companion model released by Google on May 5, 2026, that works alongside any Gemma 4 target model through a technique called speculative decoding. The drafter predicts multiple future tokens at once — which the larger target model then verifies in parallel — delivering up to 3x faster inference without changing the output quality or reasoning accuracy.
Does the Gemma 4 MTP drafter reduce output quality?
No — output quality is mathematically identical to standard autoregressive inference. The target model retains final verification authority over every token. Any draft token the target model disagrees with is rejected; the output sequence only includes tokens the full Gemma 4 model endorses. This is a fundamental guarantee of speculative decoding, not a soft claim.
How do I set up Gemma 4 MTP on Hugging Face?
Load two models — the target Gemma 4 model and its corresponding assistant model (e.g., google/gemma-4-E2B-it and google/gemma-4-E2B-it-assistant). Pass the assistant_model parameter in the generate() call. Set num_assistant_tokens_schedule='heuristic' to let the framework dynamically tune draft token count. See Section 5 of this article for the complete code.
How fast is Gemma 4 with MTP on NVIDIA and Apple Silicon?
On NVIDIA H100, the Gemma 4 31B Dense reaches approximately 27 tokens per second with MTP versus roughly 14 without — about a 1.9x gain. On NVIDIA RTX PRO 6000 with the 26B MoE, speeds up to 3x have been benchmarked. On Apple Silicon with the 26B MoE at batch size 1, gains are limited by routing overhead; increasing to batch size 4–8 unlocks approximately 2.2x speedup.
What is the difference between a target model and a drafter model?
The target model is the full Gemma 4 model — E2B, E4B, 26B MoE, or 31B Dense. It is the authoritative model whose outputs define quality. The drafter model is a tiny 4-layer companion that makes fast, probabilistic guesses about which tokens the target model would choose next. The drafter is wrong occasionally — that is expected — but when it is right, multiple tokens are produced at the cost of one verification pass.
How many draft tokens should I use with Gemma 4 MTP?
Start with the heuristic schedule, which dynamically adjusts based on observed acceptance rates. If you want manual control: 3–4 draft tokens work well for code generation, 5–8 for conversational and summarization tasks, and 10–15 for long-form prose generation (with higher ceiling but also higher risk of wasted compute on rejections).
Where do I download the Gemma 4 MTP drafter models?
The MTP drafters are available on Hugging Face under the Apache 2.0 license. The model IDs follow the pattern 'google/gemma-4-[variant]-it-assistant' — for example, google/gemma-4-E2B-it-assistant, google/gemma-4-26B-A4B-it-assistant, and google/gemma-4-31B-it-assistant. They are also available on Kaggle.
Does Gemma 4 MTP work with Ollama?
Ollama support is listed as part of the ecosystem but is still being validated across versions as of May 2026. Hugging Face Transformers and vLLM are the most stable and well-documented paths for MTP integration today. Check the Ollama release notes for your installed version to confirm speculative decoding is supported for Gemma 4.
Recommended Blogs
- How to Run Google's Gemma 3 270M Locally: A Complete Developer's Guide
- OpenAI Agents: Automate AI Workflows
- LangGraph Supervisor: Building Multi-Agent Workflows
- Griptape: AI Workflow Automation
- Mastering LangGraph's Multi-Agent Swarm
- Top 11 AI-Powered Developer Tools Transforming Workflows in 2025
References
- Google Blog — Accelerating Gemma 4: Faster Inference with Multi-Token Prediction Drafters
- Google AI for Developers — Gemma 4 MTP Documentation (Hugging Face Transformers)
- Google Blog — Gemma 4: Byte for Byte, the Most Capable Open Models
- Claypier — Google Releases MTP Drafters for Gemma 4, Boosting Inference Up to 3x
- FlowHunt — Gemma 4 Was Released Without MTP Data — Here's Why That Matters
- WaveSpeed Blog — What Is Google Gemma 4? Architecture, Benchmarks, and Why It Matters
- Prem AI Blog — Speculative Decoding: 2-3x Faster LLM Inference (2026)
- Daily.dev — Multi-Token Prediction in Gemma 4
- Hacker News — Accelerating Gemma 4: Faster Inference with MTP Drafters (community discussion)

