





Gemma 4 12B: Specs, Benchmarks, and How It Beats Bigger Models
Here is the number that matters: 16 GB. On June 3, 2026, Google DeepMind released Gemma 4 12B, an open multimodal model that runs text, image, audio, and video natively on a laptop with 16 GB of RAM — and, by Google's own account, nearly matches the twice-as-large 26B model across benchmarks while clearly beating the older Gemma 3 27B. It is the first mid-sized Gemma with native audio, it ships under a fully permissive Apache 2.0 license, and it throws out the separate vision and audio encoders almost every multimodal model still uses. This guide covers the specs, the architecture that makes it special, what the benchmarks actually say (and don't), how it stacks up against Qwen, DeepSeek, MiniMax, and StepFun, and exactly how to run it yourself.
What is Gemma 4 12B?
Gemma 4 12B is a 12-billion-parameter open multimodal model from Google DeepMind, released on June 3, 2026 as the new mid-sized member of the Gemma 4 family. The wider Gemma 4 line arrived in April 2026 with the edge-friendly E4B and a larger 26B Mixture-of-Experts (MoE) variant; the 12B Unified model slots between them — small enough for consumer laptops, capable enough to approach the 26B on standard benchmarks. It is a dense, decoder-only transformer that natively handles text, images, video, and — a first for a mid-sized Gemma — audio input, generating text output. Both pre-trained and instruction-tuned (“it”) variants are available as open weights.
If you track open models, it lands squarely in the conversation covered by the open-source LLMs hub, and as a Google release it also belongs to the broader Google Gemini and Google AI ecosystem. What sets it apart from the rest of that field is the deployment story: frontier-flavored multimodal capability that fits in the memory budget of a mainstream machine.
Gemma 4 12B specs at a glance
The headline specs put Gemma 4 12B firmly in the “runs locally, punches above its weight” category:
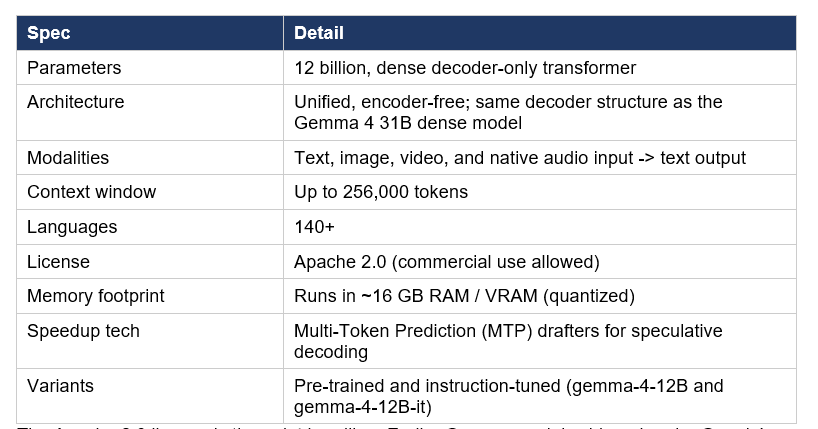
The Apache 2.0 license is the quiet headline. Earlier Gemma models shipped under Google's source-available Gemma Terms of Use; Gemma 4 is fully open source, which removes the licensing friction that pushed some enterprises toward Qwen or DeepSeek. For teams that want a clean commercial license and local control, that single change reshapes the shortlist.
The encoder-free architecture, explained
Gemma 4 12B's biggest technical story is what it removes. Most multimodal models bolt a separate vision encoder (and often a separate audio encoder) onto a language model, then translate between them. Gemma 4 12B strips that machinery out. Vision and audio flow straight into the decoder backbone. For images, a lightweight ~35-million-parameter vision module converts image patches into tokens; for audio, raw 16 kHz sound is mapped directly into the model's token space without a dedicated audio encoder. Everything then runs through one unified decoder-only transformer.
Why it matters in practice: fewer moving parts means lower memory use, lower latency, and a single processing pipeline instead of three. Google says this cuts processing time and memory footprint — which is precisely how a 12B multimodal model fits on a 16 GB laptop. The model also bundles Multi-Token Prediction (MTP) drafters for speculative decoding, a trick that predicts several tokens ahead to speed up inference without retraining.
Concrete proof of the multimodal reach: in a Google demo, the model parsed a five-minute Google I/O keynote clip — 313 frames at one frame per second plus the audio track — analyzing video and sound together. That kind of long multimodal context on local hardware is what “encoder-free” buys you.
Benchmarks: what Google published and what it didn't
Be careful with the benchmark numbers floating around, because Google was deliberately restrained at launch. The official release notes state the 12B model performs near the 26B MoE on standard benchmarks at less than half the memory footprint, and beats the older Gemma 3 27B on suites like GPQA Diamond, MMLU Pro, and DocVQA. What Google did not do in the initial materials is publish a full, numbered benchmark table.
Figures circulating in early coverage put Gemma 4 12B around 78.8% on GPQA Diamond and 94.9% on DocVQA. Treat those as reported-not-confirmed until Google ships the official numbers — a 78.8% GPQA Diamond would be remarkable for a 12B model, so it is worth verifying against the model card before quoting it as fact. The safe, defensible claim is the relative one: near-26B performance, clearly ahead of Gemma 3 27B, at roughly half the memory.
This is also a useful reminder for anyone benchmarking locally: a model that “nearly matches” a 26B at half the size is the kind of efficiency win that actually changes deployment decisions, regardless of any single headline percentage.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Gemma 4 12B vs Qwen, DeepSeek, MiniMax & StepFun
The open-weight field in mid-2026 is the strongest it has ever been — and most of the famous names do not actually fit on your laptop. That is the key to comparing Gemma 4 12B fairly. DeepSeek V4 and MiniMax's larger models are “open weights” in name but need data-center GPUs to run at full quality; Gemma 4 12B and the smaller Qwen variants are the ones that genuinely run on consumer hardware. Comparing raw leaderboard Elo misses the point — the right axis is capability per gigabyte of memory.

My read, honestly: if you want the strongest open model period and you have the hardware, DeepSeek V4 and the top MoE models win. But if the constraint is “runs on the machine I already own, no cloud, clean commercial license, and handles images and audio,” Gemma 4 12B is close to category-of-one right now. Qwen3.6 is its nearest true rival on consumer hardware, and it is the better pure-text coder in some tests — but it lacks the native audio and the encoder-free efficiency. For a side-by-side that updates as releases land, the best open-source LLM rankings are the place to watch.
One contrarian note: “beats a model twice its size” comparisons are almost always intra-family. Gemma 4 12B beating Gemma 3 27B is real and impressive, but it does not mean it beats every 27B-class model from a rival lab. Keep the comparison honest and task-specific.
Can it really run on your laptop? Hardware and speed
Yes — that is the entire point of the release. Gemma 4 12B is engineered for 16 GB machines, whether that is a 16 GB VRAM GPU or a Mac with 16 GB of unified memory. Real-world community testing in the first hours after launch reported:
- ~21 tokens/second on an RTX 4060 using llama.cpp — usable interactive speed on a mainstream gaming GPU.
- Smooth local runs on MacBook Pro via Apple's MLX framework, no cloud API or subscription needed.
- Q4 quantization is the practical default to fit the 12B comfortably inside 16 GB with minimal quality loss.
Treat these as community figures, not lab benchmarks — token speed varies with quantization, context length, and whether you are feeding it images or audio. But the takeaway holds: this is the rare frontier-flavored multimodal model where “run it locally” is the default path, not a heroic workaround. If you are choosing hardware or quantization levels, the patterns in the Build Fast with AI experiments repo cover local inference setup end to end.
How to run Gemma 4 12B locally
The ecosystem moved fast — Gemma 4 12B had broad day-one support. Pick the path that matches your setup:
Ollama (easiest CLI path)
Install Ollama, then pull and run the model from the command line. Ollama exposes an OpenAI-compatible API at localhost:11434, so you can point existing tooling at it with almost no code changes — ideal for wiring a local coding assistant or agent.
LM Studio (best GUI)
LM Studio gives you a desktop chat UI plus a local server, with a model browser to grab the right GGUF quantization for your RAM. Best for non-CLI users who want to test prompts visually before building.
llama.cpp (max control)
Run the GGUF build directly with llama.cpp for fine-grained control over quantization, context, and GPU offload — this is the route the ~21 tok/s RTX 4060 figure came from.
MLX (Apple Silicon)
On a Mac, MLX is the fastest native path, taking advantage of unified memory and the Apple Neural Engine.
Google AI Edge
Google's own AI Edge stack (including the AI Edge Gallery app on macOS) is built to unlock the model's agentic, on-device workflows — tool use, autonomous data processing, and visual insight generation.
Unsloth AI also published optimized builds for faster fine-tuning, so adapting Gemma 4 12B to your own domain is realistic on a single consumer GPU. If you want a reproducible local agent built on top of it, the gen-ai-experiments cookbooks walk through the wiring from model to tools.
What you can actually build with it
Because it is multimodal, local, and agentic, Gemma 4 12B opens up workloads that previously meant a cloud bill:
- Local coding assistants that never send your code to an API.
- On-device AI agents that plan, call tools, read files, and run multi-step workflows.
- Document analysis and DocVQA — parsing PDFs, forms, and scanned pages with strong visual understanding.
- Audio workflows: native speech recognition, transcription, and speaker diarization without a separate ASR pipeline.
- Video understanding — analyzing frames and audio together for summaries or search.
- Multilingual applications across 140+ languages.
- Private, personal AI systems where data never leaves the device.
The only comprehensive program designed to take you from basic prompting to building interactive Artifacts, custom integrations, and deploying production-ready code with Claude Code.
My take: the most important open release of the summer?
The benchmark percentages will get argued about for weeks, but they are not why this release matters. Gemma 4 12B matters because it collapses three things that used to be a tradeoff triangle — multimodal capability, local deployment, and a clean commercial license — into one downloadable model. A year ago you picked two. Now you can have all three on a laptop you already own.
The encoder-free design is the part I would bet on long-term. Stripping out separate vision and audio encoders is not a gimmick; it is a structural efficiency that other labs will likely copy, because it is the cleanest way to make multimodal models small enough to run at the edge. If that pattern spreads, Gemma 4 12B will look like an inflection point rather than just another open release.
The honest caveat: “runs on a laptop” and “runs well on a laptop for your specific task” are different sentences. Test it on your real workload at your real quantization before you build a product on it. The efficiency is genuine; the universal-best-model framing is marketing.
Frequently Asked Questions
What is Gemma 4 12B?
Gemma 4 12B is a 12-billion-parameter open multimodal model from Google DeepMind, released June 3, 2026. It handles text, image, video, and native audio in a single encoder-free decoder-only transformer, runs on a 16 GB laptop, and ships under an Apache 2.0 license. It is the mid-sized member of the Gemma 4 family, bridging the edge E4B and the larger 26B MoE.
Is Gemma 4 12B free and open source?
Yes. Gemma 4 is released under the Apache 2.0 license, which allows free use, modification, and commercial deployment. This is a change from Gemma 3 and earlier, which used Google's source-available Gemma Terms of Use rather than a fully open-source license.
What hardware do you need to run Gemma 4 12B?
About 16 GB of memory — either a 16 GB VRAM GPU or a Mac with 16 GB of unified memory — running a quantized build (Q4 is the practical default). Community testing reported roughly 21 tokens/second on an RTX 4060 via llama.cpp and smooth performance on MacBook Pro via MLX.
How good is Gemma 4 12B compared to the 26B model?
Google says the 12B performs near the 26B MoE on standard benchmarks at less than half the memory footprint, and clearly beats the older Gemma 3 27B on suites like GPQA Diamond, MMLU Pro, and DocVQA. Google did not publish a full numbered benchmark table at launch, so verify specific percentages against the official model card.
Is Gemma 4 12B better than Qwen or DeepSeek?
For local, on-device use it is one of the best options because it is multimodal, runs on 16 GB, and has a clean Apache 2.0 license. DeepSeek V4 and the largest MoE models are stronger overall but need data-center GPUs. Qwen3.6 is its closest consumer-hardware rival and a strong pure-text coder, but lacks Gemma 4 12B's native audio and encoder-free efficiency.
What does encoder-free multimodal mean?
It means the model does not use separate vision and audio encoders. Images are turned into tokens by a lightweight ~35M-parameter vision module and raw audio is mapped directly into token space, then everything flows through one unified decoder-only transformer. This reduces memory use and latency, which is how the model fits on a laptop.
How do I run Gemma 4 12B on Ollama or LM Studio?
Both support it. In Ollama, pull and run the model from the CLI; it exposes an OpenAI-compatible API at localhost:11434. In LM Studio, use the model browser to download the right GGUF quantization for your RAM, then chat or start a local server. llama.cpp and Apple's MLX are also supported.
What is the context window of Gemma 4 12B?
Up to 256,000 tokens, with multilingual support across 140+ languages. The long context plus native multimodality is what lets it process inputs like multi-minute video clips with synchronized audio.
References
- Google Developers Blog — Introducing Gemma 4 12B
- Google Developers Blog — Bringing Gemma 4 12B to your laptop with Google AI Edge
- Hugging Face — google/gemma-4-12B model card
- Hugging Face — google/gemma-4-12B-it (instruction-tuned)
- The Decoder — Gemma 4 12B squeezes multimodal AI onto a 16GB laptop
- MarkTechPost — Gemma 4 12B: an encoder-free multimodal model with native audio
- Tech Startups — Google launches Gemma 4 12B, frontier AI on everyday laptops
- Ollama — run open models locally

