



What if Your Innovation Could Shape the Next Era of AI?
Join Gen AI Launch Pad 2024 and bring your ideas to life. Lead the way in building the future of artificial intelligence.
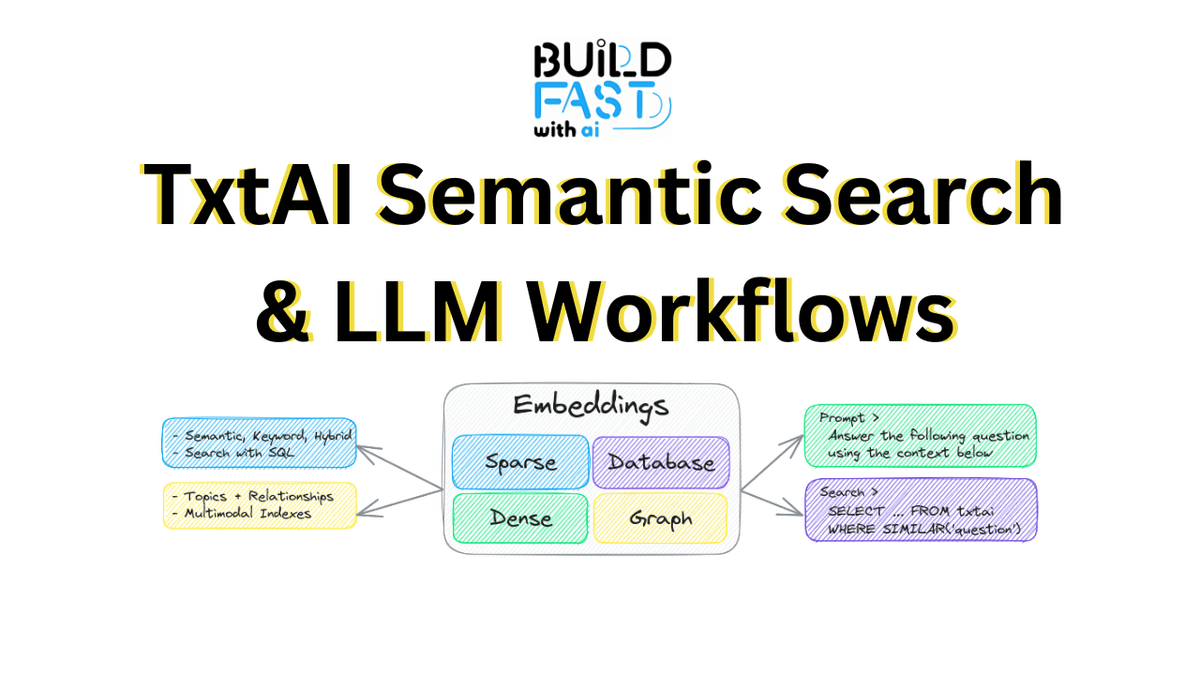
Semantic search has transformed the landscape of information retrieval. Unlike traditional keyword-based search methods, semantic search delves into the meaning and context of queries, offering a smarter and more intuitive search experience. At the heart of this evolution is txtai, an open-source platform that combines the power of embeddings with large language models (LLMs) to create sophisticated search and workflow solutions.
In this comprehensive blog, we’ll explore how to use txtai for semantic search and integrate it with LLM workflows. By the end, you’ll not only understand the theoretical underpinnings of these technologies but also gain practical insights into how to implement them in real-world scenarios.

What You’ll Learn
This blog is designed to provide an in-depth understanding of txtai and its applications. Here’s what we’ll cover:
- The fundamentals of semantic search and the role of embeddings.
- A step-by-step guide to building and querying embeddings indexes with txtai.
- Advanced use cases, including question answering, file-based search, and workflow integration.
- Practical tips for applying these techniques in various industries.
- Additional resources to deepen your knowledge.
By the end of this blog, you’ll have the tools and knowledge to build robust semantic search systems that leverage the power of AI.
Introduction to txtai
Before diving into the implementation details, let’s take a closer look at txtai. txtai is a platform that simplifies the process of building AI-powered search systems and workflows. It is designed to:
- Generate Embeddings: Create numerical representations of text, enabling similarity-based search.
- Perform Semantic Search: Retrieve results based on the meaning of queries rather than exact keyword matches.
- Integrate Workflows: Combine multiple AI-driven tasks into seamless pipelines.
Some of its standout features include:
- Support for various machine learning models to generate embeddings.
- Integration with large language models for tasks like question answering and summarization.
- Scalability for handling large datasets efficiently.
Whether you’re building a document search engine, an intelligent chatbot, or a recommendation system, txtai provides the tools to get started quickly and efficiently.
Deep Dive into Semantic Search with txtai
Step 1: Setting Up txtai
To begin, you need to install txtai. Open your terminal and run the following command:
pip install txtai
This command installs txtai along with all necessary dependencies. Once installed, you’re ready to start creating embeddings and performing semantic searches.
Step 2: Creating an Embeddings Index
Embeddings are the foundation of semantic search. They represent text as numerical vectors in a high-dimensional space, capturing the semantic meaning of the text. Here’s how to create an embeddings index with txtai:
Code Snippet:
from txtai.embeddings import Embeddings
# Create an embeddings index
embeddings = Embeddings()
# Index sample data
data = [
"txtai is a powerful semantic search library",
"Embeddings represent text as vectors",
"Semantic search focuses on meaning over keywords",
"You can integrate txtai with LLMs for advanced workflows"
]
for i, text in enumerate(data):
embeddings.add(i, text)
embeddings.save("index")
Detailed Explanation:
- Create an Embeddings Object: The
Embeddings()class initializes a new embeddings index where text data can be stored and queried. - Index Sample Data: Four sample sentences are added to the index, each assigned a unique ID.
- Save the Index: The
save()function persists the index to disk for reuse.
Practical Applications:
- Knowledge Bases: Use embeddings to index and search knowledge bases, enabling quick retrieval of relevant information.
- FAQ Systems: Build intelligent FAQ systems where users can ask natural language questions and get precise answers.
- Content Recommendations: Provide personalized recommendations by matching user preferences to content descriptions.
Step 3: Querying the Embeddings Index
Once the index is created, you can search it using natural language queries. txtai’s semantic search capabilities return results based on the meaning of the query, not just keyword matches.
Code Snippet:
# Reload the index
embeddings.load("index")
# Perform a search
query = "How does semantic search work?"
results = embeddings.search(query, 3)
for uid, score in results:
print(f"ID: {uid}, Score: {score}, Text: {data[uid]}")
Expected Output:
This query retrieves the top three results that best match the query. A sample output might look like this:
ID: 2, Score: 0.89, Text: Semantic search focuses on meaning over keywords ID: 0, Score: 0.85, Text: txtai is a powerful semantic search library ID: 1, Score: 0.83, Text: Embeddings represent text as vectors
Key Insights:
- The Score represents the relevance of each result, with higher scores indicating better matches.
- Semantic search enables a more natural and intuitive user experience compared to traditional keyword-based search.
Advanced Use Cases
While the basic implementation of txtai is powerful, its true potential lies in its advanced use cases. Let’s explore some of them.
1. Question Answering
Question answering systems are increasingly popular in customer support, e-learning platforms, and virtual assistants. txtai integrates seamlessly with LLMs to provide accurate answers to natural language queries.
Code Snippet:
from txtai.pipeline import QuestionAnswering
qa = QuestionAnswering()
context = "txtai supports semantic search and integrates with LLMs to build workflows."
question = "What does txtai support?"
answer = qa(question, context)
print(f"Answer: {answer}")
Expected Output:
Answer: semantic search and integrates with LLMs
Real-World Applications:
- Customer Support: Automate responses to common customer queries.
- Education: Provide instant answers to student questions based on course materials.
- Healthcare: Assist medical professionals with quick access to relevant information from clinical guidelines.
2. File-Based Search
Semantic search is particularly valuable for indexing and querying large collections of documents, such as PDFs, Word files, or text files. txtai can extract text from files and make it searchable.
Code Snippet:
from txtai.embeddings import Embeddings
embeddings = Embeddings()
# Add files to the index
embeddings.index((uid, text, None) for uid, text in enumerate(["Document 1 content", "Document 2 content"]))
# Search indexed documents
results = embeddings.search("content", 1)
print(results)
Expected Output:
[(0, 0.97)]
Practical Applications:
- Legal Document Discovery: Quickly find relevant legal documents in large datasets.
- Academic Research: Search through research papers, theses, and articles.
- Content Archiving: Organize and search through archived emails, reports, or other textual data.
3. Workflow Integration
txtai’s pipeline capabilities allow you to integrate multiple tasks into cohesive workflows. For example, you can combine summarization and search to handle lengthy documents effectively.
Code Snippet:
from txtai.pipeline import Summary summary = Summary() text = "txtai enables semantic search, integrates with LLMs, and supports workflows for advanced AI applications." print(summary(text))
Expected Output:
txtai enables semantic search and supports workflows.
Real-World Applications:
- Media Monitoring: Summarize and search through news articles or social media posts.
- Corporate Reports: Extract key insights from lengthy financial or business reports.
- E-Learning: Provide concise summaries of educational materials for students.
Best Practices for Using txtai
- Data Preprocessing: Ensure that the data you index is clean and well-structured. Remove unnecessary noise to improve the quality of search results.
- Model Selection: Experiment with different machine learning models supported by txtai to find the one that best suits your dataset.
- Performance Optimization: Use batch processing and indexing strategies to handle large datasets efficiently.
- User Feedback: Incorporate user feedback to continuously refine and improve the search system.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Conclusion
Semantic search and LLM workflows represent the future of information retrieval. With txtai, you have a powerful and flexible tool to build intelligent systems that go beyond traditional search capabilities. From creating embeddings to integrating workflows, txtai makes it easy to harness the power of AI for real-world applications.
We’ve explored the fundamentals of txtai, walked through practical implementations, and highlighted advanced use cases. Now it’s your turn to experiment and innovate with txtai.
Resources
To help you get started and deepen your understanding, here are some valuable resources:
---------------------------------
Stay Updated:- Follow Build Fast with AI pages for all the latest AI updates and resources.
Experts predict 2025 will be the defining year for Gen AI implementation.Want to be ahead of the curve?
Join Build Fast with AI’s Gen AI Launch Pad 2025 - your accelerated path to mastering AI tools and building revolutionary applications.

