



Tomorrow’s leaders are building AI today. Are you one of them?
Sign up for Gen AI Launch Pad 2024 and begin your journey to shaping the future. Be a builder, not a bystander.
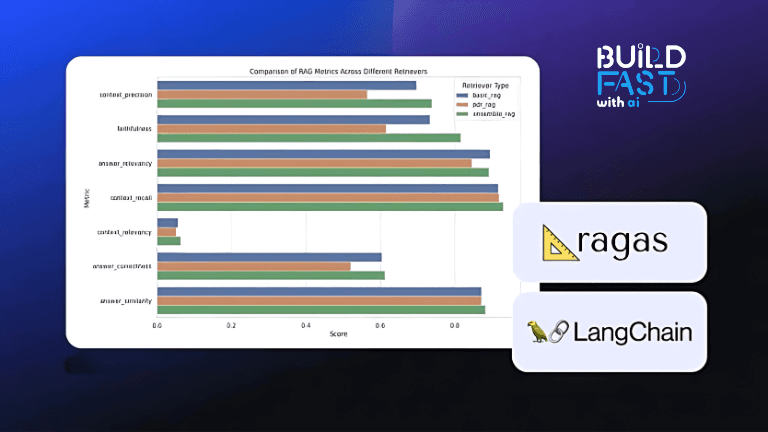
Retrieval-Augmented Generation (RAG) systems have emerged as a transformative technology in artificial intelligence, combining the strengths of retrieval and generative models. However, evaluating their performance effectively has remained a challenge. This blog post delves into Ragas, an open-source evaluation framework designed to address this gap, offering developers tools to analyze and optimize their RAG workflows.
Introduction
Ragas provides a structured approach to assess the quality of RAG systems by focusing on two key components: retrieval and generation. With support for metrics like precision, recall, response coherence, and more, Ragas helps developers fine-tune their systems to deliver accurate and reliable results. This blog will guide you through the following:
- Understanding the setup and installation of Ragas.
- Building a simple question-answering (QA) application using LangChain and OpenAI models.
- Creating evaluation datasets and utilizing Ragas metrics to analyze performance.
- Insights into advanced evaluation techniques and real-world applications.
By the end of this post, you will be equipped to leverage Ragas for enhancing your RAG systems.
Getting Started with Ragas
Setup and Installation
To begin, install Ragas and its dependencies using the following commands:
pip install ragas sacrebleu langchain-openai pip install git+https://github.com/explodinggradients/ragas.git
Set up your API keys for seamless integration:
from google.colab import userdata
import os
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
Key Components
Ragas integrates seamlessly with popular RAG frameworks like LangChain, enabling easy evaluation and optimization. For this walkthrough, we'll build a simple QA application using LangChain's tools and OpenAI models.
Building a Simple QA Application
Data Preparation
The foundation of any QA system is high-quality data. Here's an example dataset containing brief biographies of prominent AI leaders:
from langchain_core.documents import Document
content_list = [
"Andrew Ng is the CEO of Landing AI and is known for his pioneering work in deep learning. He is also widely recognized for democratizing AI education through platforms like Coursera.",
"Sam Altman is the CEO of OpenAI and has played a key role in advancing AI research and development. He is a strong advocate for creating safe and beneficial AI technologies.",
"Demis Hassabis is the CEO of DeepMind and is celebrated for his innovative approach to artificial intelligence. He gained prominence for developing systems that can master complex games like AlphaGo.",
"Sundar Pichai is the CEO of Google and Alphabet Inc., and he is praised for leading innovation across Google's vast product ecosystem. His leadership has significantly enhanced user experiences on a global scale.",
"Arvind Krishna is the CEO of IBM and is recognized for transforming the company towards cloud computing and AI solutions. He focuses on providing cutting-edge technologies to address modern business challenges.",
]
langchain_documents = [Document(page_content=content) for content in content_list]
Setting Up the Vector Store
To enable efficient document retrieval, we'll use OpenAI embeddings and an in-memory vector store:
from langchain_openai.embeddings import OpenAIEmbeddings from langchain_core.vectorstores import InMemoryVectorStore embeddings = OpenAIEmbeddings(model="text-embedding-3-small") vector_store = InMemoryVectorStore(embeddings) _ = vector_store.add_documents(langchain_documents)
Configuring the Retriever
The retriever fetches the most relevant documents based on a query:
retriever = vector_store.as_retriever(search_kwargs={"k": 1})
Implementing the QA Pipeline
Language Model and Prompt Configuration
Leverage OpenAI's GPT models to generate answers:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(model="gpt-4o-mini")
template = """Answer the question based only on the following context:
{context}
Question: {query}
"""
prompt = ChatPromptTemplate.from_template(template)
qa_chain = prompt | llm | StrOutputParser()
Query Processing
Here's how you can process queries and retrieve answers:
def format_docs(relevant_docs):
return "\n".join(doc.page_content for doc in relevant_docs)
query = "Who is the CEO of OpenAI?"
relevant_docs = retriever.invoke(query)
qa_chain.invoke({"context": format_docs(relevant_docs), "query": query})
Expected Output:
'The CEO of OpenAI is Sam Altman.'
Evaluating the QA System with Ragas
Creating an Evaluation Dataset
Ragas enables systematic evaluation of RAG systems using metrics like recall and coherence. Here’s how to create an evaluation dataset:
from ragas import EvaluationDataset
dataset = []
sample_queries = [
"Which CEO is widely recognized for democratizing AI education through platforms like Coursera?",
"Who is Sam Altman?",
"Who is Demis Hassabis and how did he gain prominence?",
"Who is the CEO of Google and Alphabet Inc., praised for leading innovation across Google's product ecosystem?",
"How did Arvind Krishna transform IBM?",
]
expected_responses = [
"Andrew Ng is the CEO of Landing AI and is widely recognized for democratizing AI education through platforms like Coursera.",
... # Other responses
]
for query, reference in zip(sample_queries, expected_responses):
relevant_docs = retriever.invoke(query)
response = qa_chain.invoke({"context": format_docs(relevant_docs), "query": query})
dataset.append({
"user_input": query,
"retrieved_contexts": [rdoc.page_content for rdoc in relevant_docs],
"response": response,
"reference": reference,
})
evaluation_dataset = EvaluationDataset.from_list(dataset)
Applying Ragas Metrics
Evaluate the dataset using key metrics:
from ragas import evaluate
from ragas.llms import LangchainLLMWrapper
from ragas.metrics import LLMContextRecall, Faithfulness, FactualCorrectness
evaluator_llm = LangchainLLMWrapper(llm)
result = evaluate(
dataset=evaluation_dataset,
metrics=[LLMContextRecall(), Faithfulness(), FactualCorrectness()],
llm=evaluator_llm,
)
Expected Output:
{'context_recall': 1.0000, 'faithfulness': 0.9500, 'factual_correctness': 0.9140}
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Conclusion
Ragas is a powerful tool for evaluating RAG systems, providing insights into retrieval accuracy and generation quality. By following this guide, developers can create robust QA systems and continuously improve their performance. To explore more, visit the Ragas GitHub repository.
Next Steps
- Experiment with additional metrics to assess system performance.
- Integrate Ragas into larger-scale projects.
- Explore advanced RAG workflows with LangChain and other frameworks.
Resources
---------------------------------
Stay Updated:- Follow Build Fast with AI pages for all the latest AI updates and resources.
Experts predict 2025 will be the defining year for Gen AI implementation.Want to be ahead of the curve?
Join Build Fast with AI’s Gen AI Launch Pad 2025 - your accelerated path to mastering AI tools and building revolutionary applications.

