




What’s the one problem AI hasn’t solved yet?
Join Gen AI Launch Pad 2024 and turn groundbreaking challenges into your greatest achievements. The future of AI is waiting for you to lead.
Introduction
In the age of AI and big data, vector databases have become indispensable for applications like recommendation systems, image and text retrieval, and more. This blog dives into Milvus, a leading open-source vector database designed to handle massive-scale vector data efficiently. By the end of this post, you will understand the fundamentals of Milvus, how to set it up, and use its powerful features to build your own vector-based applications.
Setting Up Milvus
Code Block: Installing Dependencies
# Install pymilvus, the Python SDK for Milvus !pip install pymilvus==2.0.0
Explanation
The pymilvus library provides a Python interface to interact with the Milvus database. This command installs version 2.0.0, which is compatible with the examples provided in this blog. The ! is used to execute the command in a Jupyter Notebook or similar interactive environment.
Key Points
- Why Version 2.0.0? Ensures compatibility with the Milvus server version used in this tutorial.
- Environment Requirements: Python 3.7 or later is recommended.
Expected Output
The terminal or notebook output will display logs confirming the installation:
Collecting pymilvus==2.0.0 ... (installation logs) Successfully installed pymilvus-2.0.0
If errors occur, ensure your environment has network access and pip is updated.
Real-World Application
Installing pymilvus is essential for developing Python applications that interact with Milvus. This step lays the groundwork for building vector-based AI systems.
Connecting to Milvus
Code Block: Establishing a Connection
from pymilvus import connections
# Connect to a Milvus instance
connections.connect(
alias="default",
host="localhost",
port="19530"
)
Explanation
This snippet establishes a connection to the Milvus server. It uses the default alias "default" to refer to this connection in subsequent operations. The host and port parameters specify the server location and the port it is listening on (default is 19530).
Key Points
connections.connect: Links the application to the Milvus server.- Localhost: Assumes Milvus is running locally. Replace with the actual IP or domain if Milvus is deployed remotely.
- Alias: Enables multiple connections to different Milvus instances.
Expected Output
No explicit output is shown if the connection is successful. If the server is not reachable, an error message similar to this will appear:
RuntimeError: Failed to connect to Milvus server at localhost:19530.
Real-World Application
This step is foundational for using Milvus. Without a connection, no operations (like inserting or searching data) can be performed.
Creating a Collection
Code Block: Defining a Collection
from pymilvus import FieldSchema, CollectionSchema, DataType, Collection
# Define schema for the collection
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=128)
]
schema = CollectionSchema(fields, description="Demo collection for vector data")
# Create the collection
collection = Collection(name="demo_collection", schema=schema)
Explanation
In this block, we define the schema for a Milvus collection and create the collection. A collection is analogous to a table in relational databases.
Key Points
- Schema Definition:
FieldSchema: Defines attributes of a field.name: Field name (e.g., "id" or "embedding").dtype: Data type (e.g.,INT64for IDs,FLOAT_VECTORfor embeddings).is_primary: Marks the field as the primary key.dim: Specifies the dimensionality for vector fields.CollectionSchema: Groups fields into a single schema.
- Collection Creation:
Collection: Instantiates a new collection with the defined schema.
Expected Output
Upon successful creation, no direct output is shown. Errors may occur if the collection name is already in use or the schema is invalid:
CollectionAlreadyExistException: Collection demo_collection already exists.
Real-World Application
Collections organize data in Milvus. Use them to store embeddings for applications like image retrieval, text similarity, or recommendation systems.
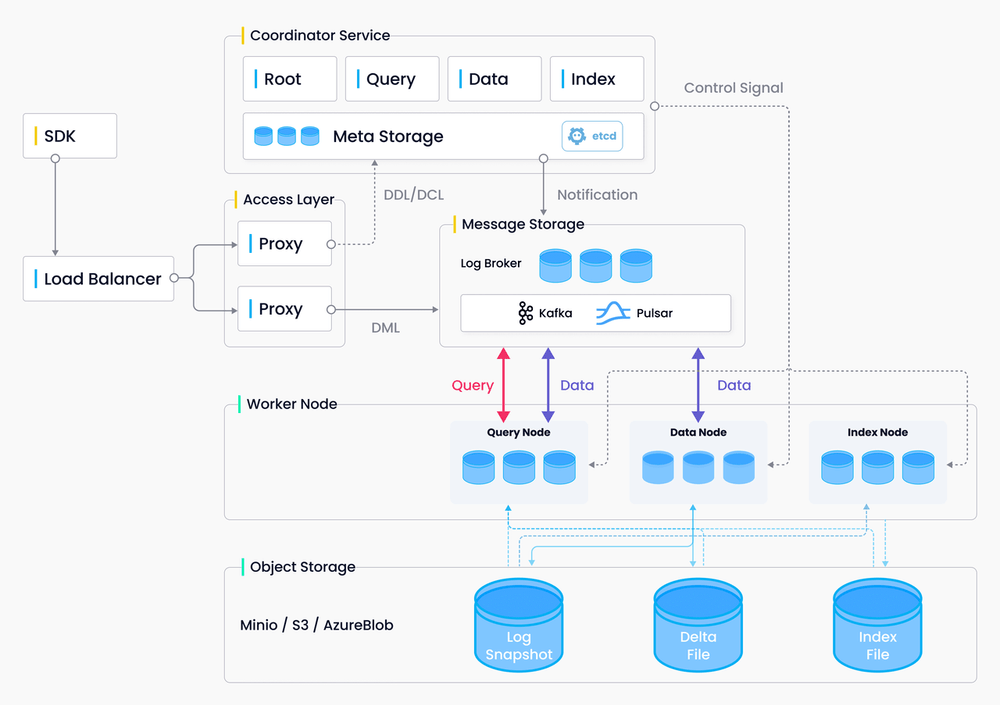
Building a Vector Database for Scalable Similarity Search
Inserting Data
Code Block: Adding Data to the Collection
import random # Generate sample data ids = [i for i in range(100)] embeddings = [[random.random() for _ in range(128)] for _ in range(100)] # Insert data into the collection collection.insert([ids, embeddings])
Explanation
This block demonstrates how to generate and insert data into the collection:
- ID Generation:
- A list of unique integers from 0 to 99 is created.
- Embedding Generation:
- Random 128-dimensional vectors are generated using Python’s
randommodule.
- Data Insertion:
- The
insertmethod adds the IDs and embeddings to the collection.
Key Points
- Data format must match the collection schema.
- Ensure the number of IDs matches the number of embeddings.
Expected Output
{ "insert_count": 100 }
This indicates that 100 records have been successfully inserted into the collection.
Real-World Application
Inserting data is critical for applications that rely on vector search, such as retrieving similar images or finding related documents.
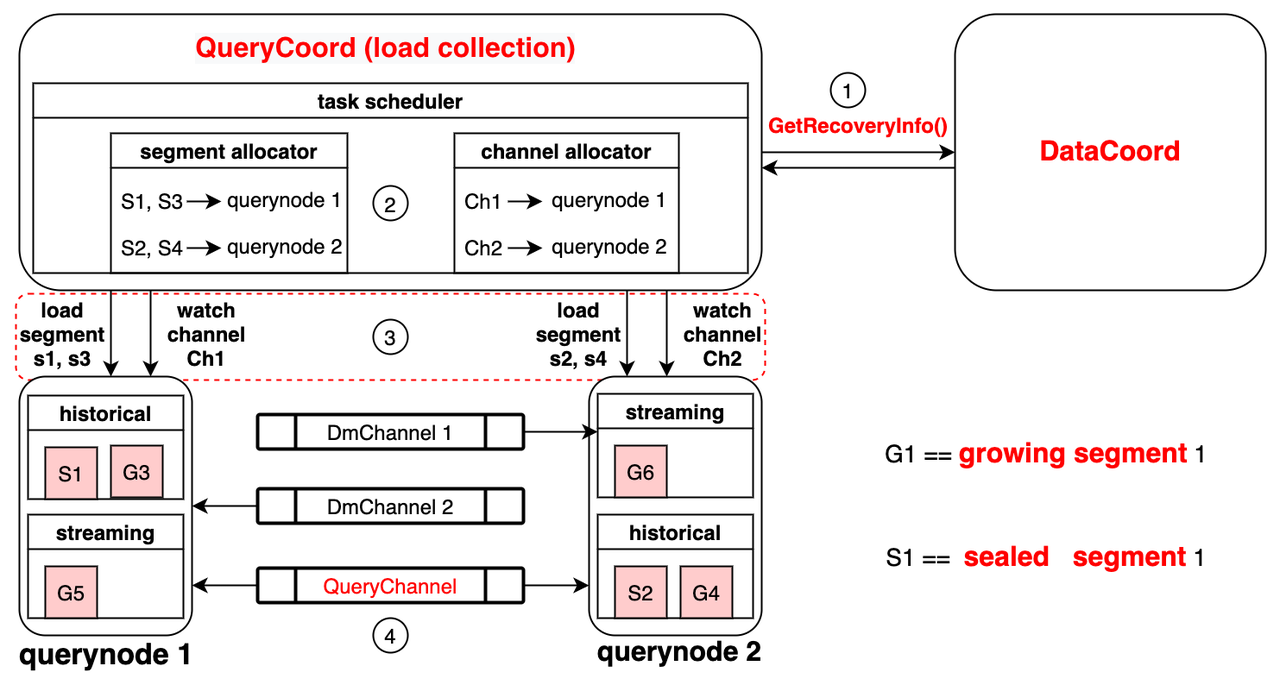
Using the Milvus Vector Database for Real-Time Query
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Searching Data
Code Block: Performing a Vector Search
# Load the collection into memory
collection.load()
# Perform a search
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
query_vectors = [[random.random() for _ in range(128)]]
results = collection.search(query_vectors, "embedding", search_params, limit=5)
# Display results
for result in results:
print(result)
Explanation
This code performs a similarity search in the collection:
- Loading Data:
load: Brings the collection data into memory for faster querying.
- Search Parameters:
metric_type: Specifies the distance metric (e.g., L2 for Euclidean distance).nprobe: Number of partitions to search for approximate nearest neighbors.
- Query:
- A random 128-dimensional vector is generated and used as the query.
search: Finds the top 5 vectors closest to the query vector.
Key Points
- Results are sorted by similarity (smallest distance for L2 metric).
- Adjusting
nprobecan balance speed and accuracy.
Expected Output
A list of search results showing IDs and distances:
[<SearchResult: id=12, distance=0.123>, <SearchResult: id=54, distance=0.456>, ...]
Real-World Application
Vector search is used in systems like facial recognition, recommendation engines, and document retrieval.
Conclusion
Milvus simplifies the implementation of vector search, enabling developers to build scalable, high-performance AI applications. With its intuitive Python SDK, you can create, manage, and query collections effortlessly.
Key Takeaways
- Milvus is optimized for vector search at scale.
- Collections and schemas form the foundation of data organization.
- The Python SDK makes integration straightforward.
Resources
- Milvus Official Documentation
- PyMilvus SDK Guide
- GitHub Repository
- Build Fast With AI NoteBook Building a Recommendation System with Milvus
---------------------------------
Stay Updated:- Follow Build Fast with AI pages for all the latest AI updates and resources.
Experts predict 2025 will be the defining year for Gen AI implementation.Want to be ahead of the curve?
Join Build Fast with AI’s Gen AI Launch Pad 2025 - your accelerated path to mastering AI tools and building revolutionary applications.

