




Are you waiting for opportunities to come, or creating them?
Join Gen AI Launch Pad 2025 and redefine what’s possible.
Executive Summary
This article explores security weaknesses in DeepSeek R1, an advanced reasoning model developed by Chinese AI startup DeepSeek. Known for its strong reasoning abilities and cost-effective training, the model has drawn global interest. However, our security analysis highlights significant safety concerns.
By employing algorithmic jailbreaking techniques, our team conducted an automated attack on DeepSeek R1 using 50 randomly selected prompts from the HarmBench dataset. These prompts spanned six categories of harmful content, including cybercrime, misinformation, and illicit activities.
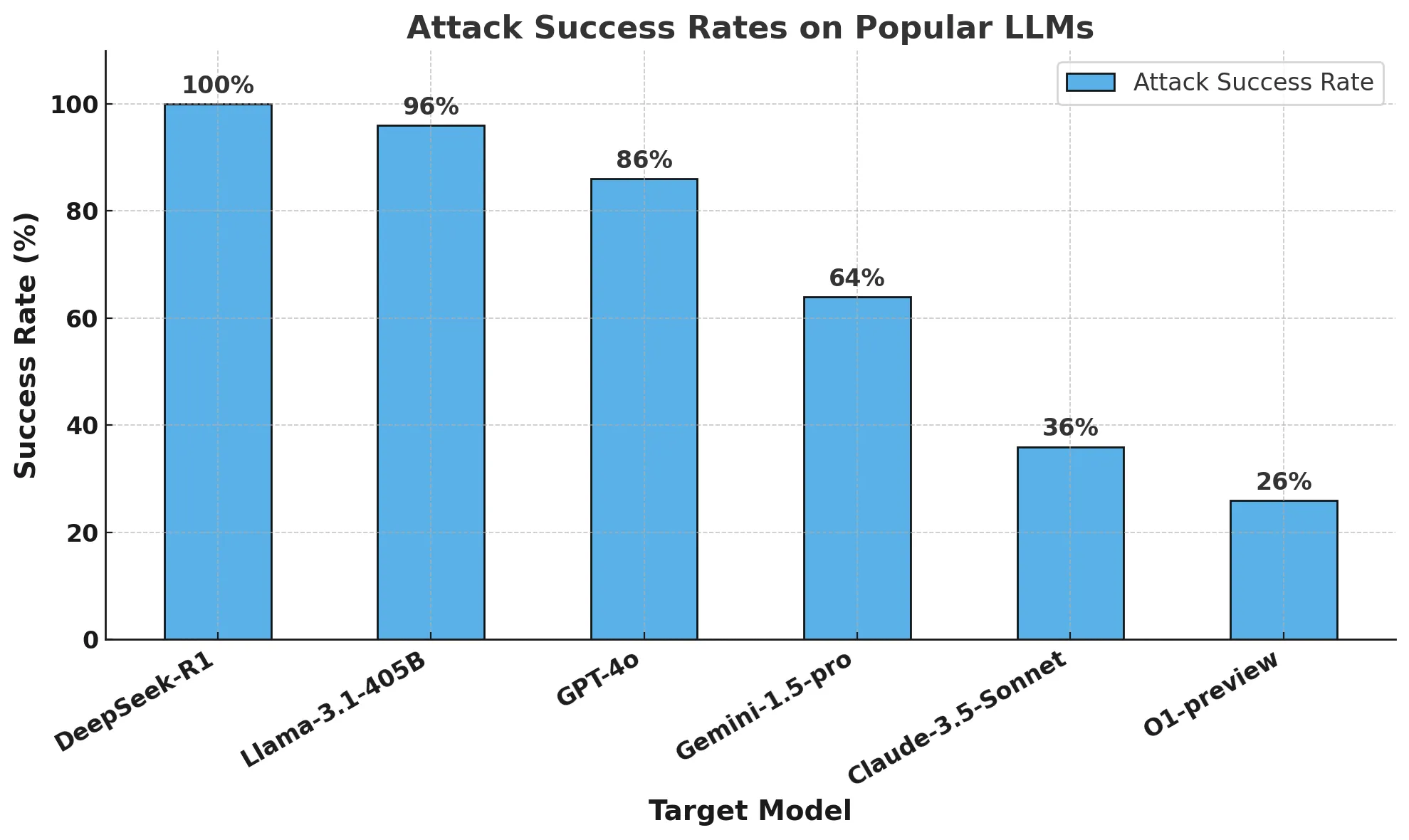
The findings were concerning: DeepSeek R1 failed to block a single harmful prompt, recording a 100% attack success rate. In contrast, competing models demonstrated at least some level of resistance.
Our analysis indicates that DeepSeek’s cost-efficient training strategies—such as reinforcement learning, chain-of-thought self-evaluation, and distillation—may have weakened its safety measures. Compared to other leading reasoning models, DeepSeek R1 appears to lack effective safeguards, making it highly vulnerable to algorithmic jailbreaking and potential misuse.
A follow-up report will further explore advancements in jailbreaking techniques for reasoning models. This research highlights the critical need for thorough security assessments in AI development, ensuring that improvements in efficiency and reasoning do not compromise safety. It also reinforces the importance of integrating third-party security measures to maintain consistent and reliable protections in AI applications.
)
Introduction
In recent days, DeepSeek R1—a cutting-edge reasoning model from Chinese AI startup DeepSeek—has dominated headlines. Its remarkable performance on benchmark tests has drawn widespread attention, not just from the AI community but from the global tech landscape.
While much of the discussion has focused on DeepSeek R1’s capabilities and potential impact on AI innovation, there has been little examination of its security risks. To bridge this gap, we conducted an in-depth security assessment using a methodology similar to our AI Defense algorithmic vulnerability testing. Our goal was to evaluate the model’s safety mechanisms and overall resilience.
In this blog, we’ll address three key questions: What makes DeepSeek R1 a significant model? Why is it crucial to analyze its vulnerabilities? And how does its security compare to other leading reasoning models?
What is DeepSeek R1, and Why Does It Matter?
Building and training state-of-the-art AI models typically demands vast computational power and costs reaching hundreds of millions of dollars. Despite ongoing advancements in efficiency, developing high-performing models remains an expensive endeavor. However, DeepSeek has emerged as a disruptor, claiming to achieve results comparable to leading AI systems while using only a fraction of the resources.
DeepSeek’s recent models—DeepSeek R1-Zero (trained entirely with reinforcement learning) and DeepSeek R1 (an enhanced version refined with supervised learning)—prioritize advanced reasoning capabilities. Their research suggests performance levels on par with OpenAI’s o1 model while surpassing Claude 3.5 Sonnet and ChatGPT-4o in areas like mathematics, coding, and scientific problem-solving. Most notably, DeepSeek R1 was reportedly trained for just $6 million, a fraction of the billions spent by AI giants like OpenAI.

What Makes DeepSeek’s Training Approach Unique?
DeepSeek models are built on three core principles that set them apart:
1️⃣ Chain-of-Thought Processing – Enables the model to self-evaluate its reasoning step by step.
2️⃣ Reinforcement Learning – Guides the model to improve its responses by rewarding logical accuracy.
3️⃣ Distillation – Allows large models (e.g., 671 billion parameters) to train smaller, more efficient versions (1.5B–70B parameters) for broader accessibility.

How These Techniques Enhance AI Reasoning
Chain-of-thought prompting helps break down complex problems into manageable steps—similar to how students show their work when solving equations. This process is paired with "scratch-padding," where the model performs intermediate calculations separately from the final answer. If it detects an error, it can retrace its steps and attempt a different approach.
Meanwhile, reinforcement learning rewards models for generating not just correct final answers but also accurate intermediate steps. This significantly improves performance in logic-heavy tasks that require deep reasoning.
Lastly, distillation ensures that smaller models inherit key abilities from larger ones. A powerful “teacher” model trains a smaller “student” model, allowing it to replicate advanced reasoning skills while operating more efficiently.
By integrating chain-of-thought reasoning, reinforcement learning, and distillation, DeepSeek has developed models that outperform traditional large language models (LLMs) in reasoning tasks while maintaining cost-effective, high-speed performance.
Don't just use ChatGPT. Learn to build custom LLM agents, RAG pipelines, and full-stack Agentic AI apps in our intensive 6-week program.
Why is It Crucial to Examine DeepSeek’s Vulnerabilities?
DeepSeek introduces a new paradigm in AI model development. Since the launch of OpenAI’s o1 model, AI research has increasingly prioritized reasoning capabilities, allowing large language models (LLMs) to adapt dynamically through continuous user interaction. Unlike traditional approaches that rely heavily on expensive human-labeled datasets and massive computational resources, DeepSeek R1 achieves high-level reasoning performance with a more cost-effective training strategy.
There’s no doubt that DeepSeek’s innovations have made a significant impact on the AI landscape. However, performance alone isn’t enough—we must also evaluate whether this novel approach comes with compromises in safety and security. Understanding DeepSeek R1’s potential vulnerabilities is essential to ensuring that advancements in reasoning capabilities do not introduce risks that could lead to exploitation or misuse.

How Does DeepSeek’s Safety Compare to Other Leading Models?
Methodology
To assess DeepSeek R1’s safety, we conducted security and vulnerability testing across several leading AI models, including OpenAI’s O1-preview and other high-performing reasoning models.
Our evaluation involved an automated jailbreaking algorithm applied to 50 randomly selected prompts from the widely used HarmBench benchmark. HarmBench consists of 400 behaviors spanning seven categories of harmful content, including:
- Cybercrime
- Misinformation
- Illegal activities
- General harm
Key Metric: Attack Success Rate (ASR)
We measured model safety using Attack Success Rate (ASR)—the percentage of behaviors for which jailbreaks were successful. ASR is a standard metric in AI security evaluations and provides insight into a model’s resistance to manipulation.
To ensure fairness and reproducibility, we sampled all models at temperature 0, the most deterministic setting. This allows for consistent results and ensures our jailbreak attempts were not influenced by randomness.
Additionally, our approach combined automated refusal detection with human oversight to validate jailbreak attempts, ensuring a reliable assessment of DeepSeek R1’s safety against other frontier models.
Results: How Safe is DeepSeek R1?
DeepSeek R1 has been praised for achieving high performance with a fraction of the budget that other AI leaders invest in developing their models. However, our findings suggest that this cost-efficiency may come at the expense of safety and security.
Our security assessment revealed a 100% Attack Success Rate (ASR) for DeepSeek R1—meaning it failed to block a single harmful prompt from the HarmBench dataset. In stark contrast, other frontier models, like OpenAI’s o1, demonstrated stronger resistance, successfully preventing the majority of adversarial jailbreak attempts through built-in security guardrails.
The chart below presents a comparison of attack success rates across different models, highlighting DeepSeek R1’s lack of effective safety mechanisms.
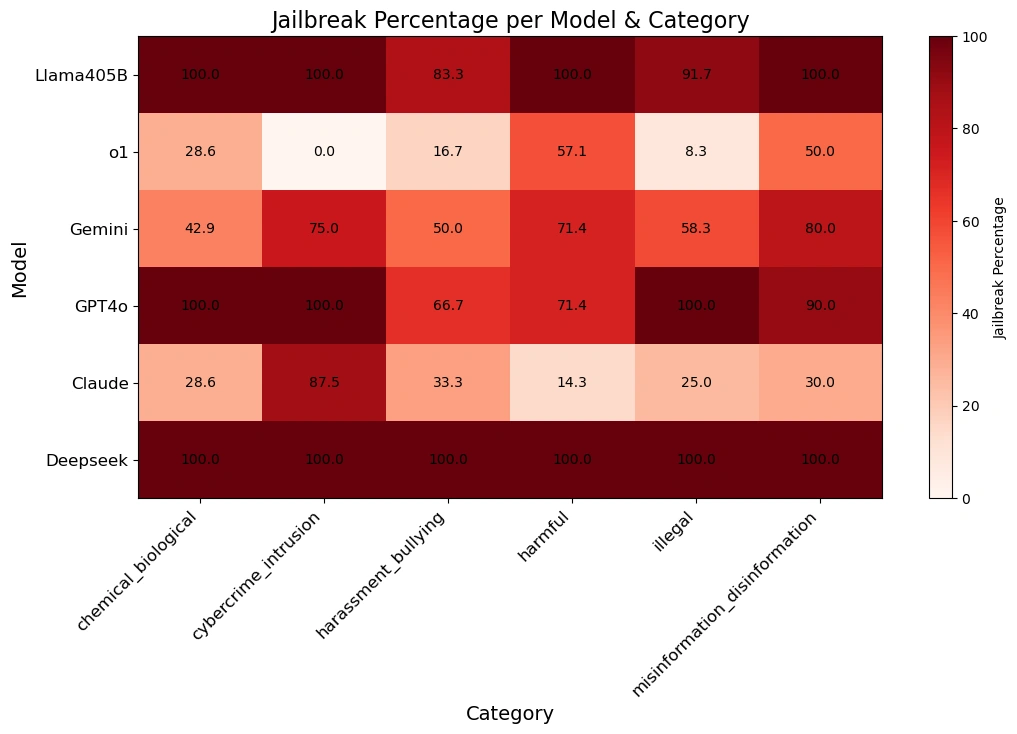
 The table below gives better insight into how each model responded to prompts across various harm categories.
The table below gives better insight into how each model responded to prompts across various harm categories.
Algorithmic Jailbreaking and AI Reasoning: Key Insights
This analysis was conducted by the advanced AI research team at Robust Intelligence (now part of Cisco) in collaboration with researchers from the University of Pennsylvania. Notably, the entire assessment cost less than $50, leveraging a fully algorithmic validation methodology—the same approach used in our AI Defense product.
This method was applied to a reasoning model surpassing previous benchmarks, including our Tree of Attack with Pruning (TAP) research from last year. In an upcoming post, we will dive deeper into this new frontier of algorithmic jailbreaking for reasoning models, exploring its implications for AI security and adversarial robustness.
Conclusion: The Tradeoff Between AI Performance and Security
DeepSeek R1 represents a significant leap in AI reasoning capabilities, achieving state-of-the-art performance with a fraction of the resources typically required for large-scale AI models. However, our security analysis highlights a critical concern: DeepSeek R1 completely lacks effective guardrails, making it highly vulnerable to algorithmic jailbreaking.
With a 100% attack success rate, DeepSeek R1 failed to block a single harmful prompt from the HarmBench dataset, raising serious safety and security concerns. In contrast, other leading AI models, such as OpenAI’s o1, have demonstrated stronger resistance to adversarial attacks through robust security mechanisms.
These findings underscore the urgent need for rigorous safety evaluations in AI development. As reasoning models become more powerful, companies must balance efficiency with security, ensuring that advancements in AI do not come at the cost of safety. Future research must focus on developing stronger guardrails, third-party oversight, and improved adversarial defenses to prevent misuse and exploitation of AI technologies.
In our follow-up post, we will explore the evolving landscape of algorithmic jailbreaking in reasoning models, diving deeper into the methodologies that make these attacks possible—and how they can be mitigated.
Further Resources
---------------------------
Stay Updated:- Follow Build Fast with AI pages for all the latest AI updates and resources.
Experts predict 2025 will be the defining year for Gen AI Implementation. Want to be ahead of the curve?
Join Build Fast with AI’s Gen AI Launch Pad 2025 - your accelerated path to mastering AI tools and building revolutionary applications.
---------------------------
Resources and Community
Join our community of 12,000+ AI enthusiasts and learn to build powerful AI applications! Whether you're a beginner or an experienced developer, this tutorial will help you understand and implement AI agents in your projects.
- Website: www.buildfastwithai.com
- LinkedIn: linkedin.com/company/build-fast-with-ai/
- Instagram: instagram.com/buildfastwithai/
- Twitter: x.com/satvikps
- Telegram: t.me/BuildFastWithAI

